Содержание статьи

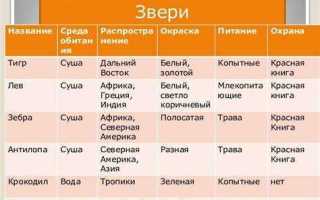
Работа с таблицами включает не только базовое внесение данных, но и структурирование информации для аналитики. Создание таблиц с правильно определёнными заголовками и типами данных позволяет сократить время на последующую фильтрацию и поиск. Например, при ведении финансового учёта рекомендуется использовать отдельные столбцы для дат, категорий расходов и сумм, что облегчает построение отчетов и визуализацию трендов.
Манипуляции с таблицами, такие как сортировка и фильтрация, повышают точность анализа. Сортировка по дате или значению помогает выявить аномалии, а фильтры позволяют выделять конкретные сегменты, например, товары с наибольшей маржинальностью. Использование условного форматирования дополнительно визуально подчёркивает критические показатели, упрощая принятие решений без необходимости детального просмотра всех строк.
Объединение и разбиение ячеек применяется для оптимизации представления информации. Слияние заголовков улучшает читаемость отчётов, а разбиение ячеек на подкатегории помогает организовать сложные наборы данных, такие как многокомпонентные проекты или расписания. Практическое применение этих действий в бизнес-аналитике и управлении проектами позволяет сократить количество ошибок и ускорить коммуникацию между отделами.
Использование формул и вычисляемых полей в таблицах повышает эффективность анализа. Автоматическое подсчитывание сумм, средних значений или процентных изменений сокращает ручной труд и минимизирует вероятность ошибок. Рекомендуется заранее определять ключевые показатели для расчёта, чтобы каждая таблица сразу выполняла аналитическую функцию и поддерживала актуальность данных при регулярном обновлении.
Добавление и удаление строк: когда и как применять
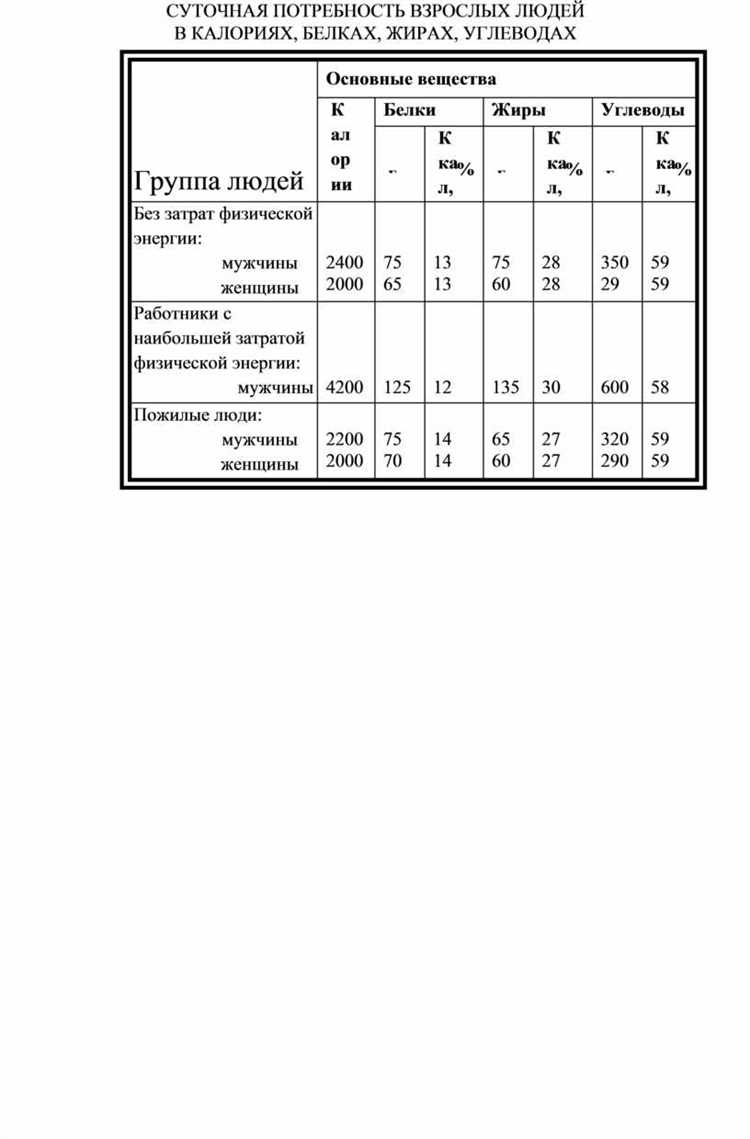
Добавление строк в таблицу целесообразно, когда требуется расширить набор данных без нарушения существующих связей. Например, в финансовых отчетах добавление строки с новым транзакционным элементом позволяет сохранить хронологическую последовательность операций и избежать искажения агрегатов. В базах данных рекомендуется использовать атомарные вставки, чтобы каждая новая запись имела уникальный идентификатор и корректно интегрировалась в индексы.
Удаление строк оправдано только при необходимости исключить устаревшие или ошибочные данные. В CRM-системах удаление контактной информации должно сопровождаться проверкой зависимости от связанных таблиц: заказов, активности клиентов или счетов. Массовое удаление без фильтров может привести к потерям критической информации, поэтому всегда стоит применять условия выборки и создавать резервные копии.
Для оптимизации работы с таблицами часто используют комбинированные подходы: строки добавляют в конце таблицы для новых записей, а устаревшие или некорректные удаляют через автоматизированные скрипты. В производственных отчетах это позволяет поддерживать актуальность данных без ручного контроля, сокращая время на проверку и корректировку до 30–40%.
При работе с большими объемами информации важно учитывать нагрузку на систему. Добавление и удаление строк по одной может замедлить выполнение запросов, поэтому для массовых операций рекомендуется пакетная обработка с фиксированными блоками по 500–1000 строк. Такой подход снижает вероятность ошибок и поддерживает целостность таблицы при параллельном доступе нескольких пользователей.
Изменение структуры столбцов для анализа данных
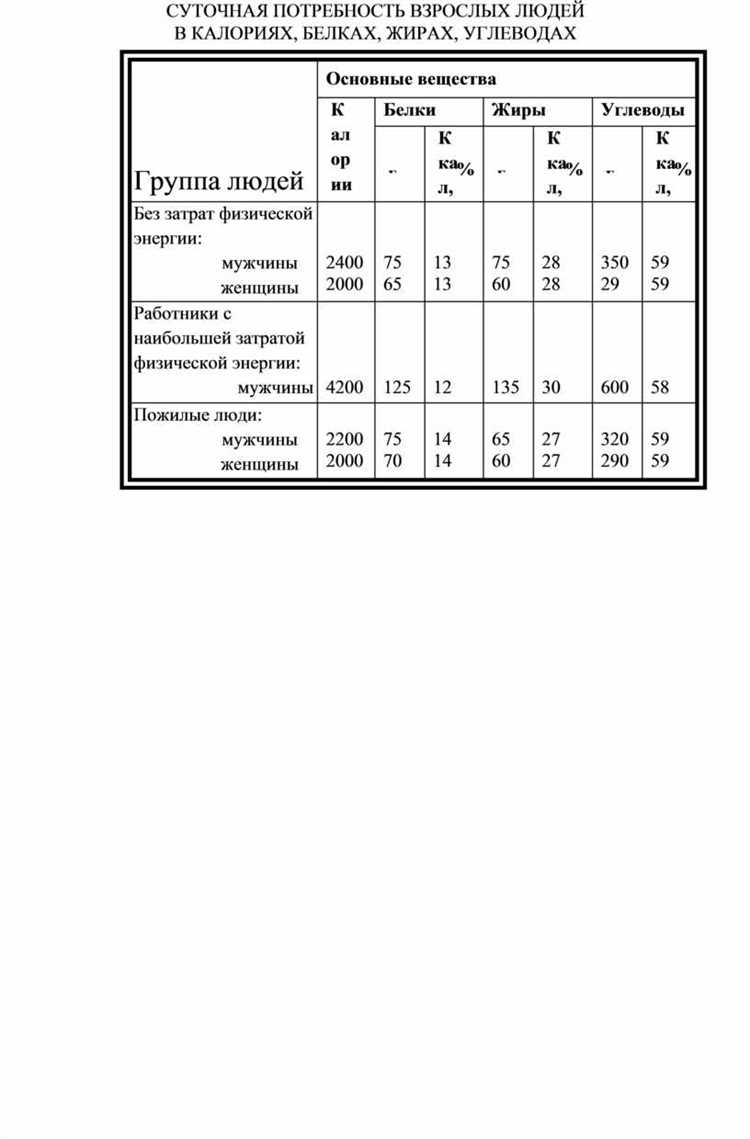
Оптимизация структуры столбцов начинается с оценки их типа и значений. Необходимо выявить столбцы с дублирующимися или избыточными данными и объединить их в один логический показатель. Например, отдельные столбцы «Город» и «Регион» можно объединить в новый столбец «Местоположение» для удобства агрегации и построения сводных отчетов.
Следующий шаг – переименование и преобразование формата данных. Для числовых столбцов рекомендуется проверять единицы измерения и округлять значения до нужной точности. В текстовых столбцах полезно стандартизировать наименования и удалить лишние пробелы. Для анализа временных рядов столбцы с датами стоит разбивать на «Год», «Месяц» и «День», что упрощает фильтрацию и группировку данных.
Также важно использовать добавление и удаление столбцов по необходимости. Создание производных столбцов, таких как «Средний доход на сотрудника» или «Процент выполнения плана», повышает информативность данных. Удаление столбцов с высоким процентом пустых значений сокращает объем таблицы и ускоряет вычисления. Регулярная проверка структуры столбцов позволяет поддерживать таблицу в готовом к анализу состоянии и минимизирует ошибки при построении графиков и отчетов.
Фильтрация записей по критериям и условиям

Фильтрация таблиц позволяет отбирать записи, соответствующие конкретным условиям, сокращая объем данных для анализа. Например, в базе продаж можно выбрать только те транзакции, где сумма покупки превышает 10 000 рублей, а дата покупки находится в пределах последнего квартала. Использование операторов сравнения (<, >, =, <=, >=) и логических соединений (AND, OR) помогает создавать сложные условия для точной выборки данных.
Для эффективной фильтрации важно учитывать тип данных в колонках. Числовые поля позволяют применять диапазонные фильтры, текстовые – искать вхождения подстрок или совпадения с шаблоном, а даты – ограничивать записи конкретными периодами. В SQL это реализуется через конструкции WHERE и BETWEEN, а в электронных таблицах – через встроенные фильтры с настройкой условий по диапазону, тексту или дате.
Фильтры также можно комбинировать для сегментации данных. Например, чтобы получить список клиентов из Москвы с покупками выше 20 000 рублей в январе, применяется объединение условий: город = ‘Москва’ AND сумма > 20000 AND дата BETWEEN ‘2026-01-01’ AND ‘2026-01-31’. Такой подход позволяет создавать динамические отчеты и экономить время при регулярном анализе больших массивов информации.
Для наглядности применения фильтров удобно использовать предварительные таблицы с примерами данных и условиями отбора:
| Клиент | Город | Сумма | Дата |
|---|---|---|---|
| Иванов | Москва | 25 000 | 2026-01-10 |
| Петров | Санкт-Петербург | 15 000 | 2026-02-05 |
| Сидоров | Москва | 8 000 | 2026-01-20 |
| Кузнецова | Екатеринбург | 22 000 | 2026-01-15 |
Применяя фильтры по условиям «Город = Москва AND Сумма > 20 000», мы получаем только одну запись – Ивана Иванова, что демонстрирует эффективность точного критерия отбора. Такой подход облегчает анализ и минимизирует риск ошибок при работе с большим количеством записей.
Сортировка данных для быстрого поиска нужной информации
Сортировка таблиц позволяет значительно ускорить работу с большими объемами данных. При правильно выбранном порядке расположения строк поиск конкретной информации сокращается с минут до секунд. Например, упорядочивание по дате позволяет мгновенно выявлять последние изменения без необходимости просматривать всю таблицу.
Существуют несколько методов сортировки: по возрастанию, по убыванию, многокритериальная и пользовательская. По возрастанию используют для числовых значений и дат, а по убыванию – для выявления лидеров или последних событий. Многокритериальная сортировка сочетает два и более столбца, например, сначала по категории продукта, затем по цене.
Практическое применение сортировки проявляется в аналитике продаж. Если таблица содержит столбцы «Товар», «Количество продаж» и «Дата», можно:
- отсортировать по дате, чтобы увидеть динамику за неделю;
- по количеству продаж – выявить наиболее популярные позиции;
- по категории товаров и затем по продажам – определить прибыльные сегменты.
Для поиска клиентов в CRM системах сортировка по алфавиту облегчает навигацию. Например, сортировка по фамилии и городу позволяет быстро находить контакт нужного человека без фильтров. Если добавлен фильтр по активности, поиск сокращается еще сильнее, исключая нерелевантные записи.
При работе с временными рядами важно правильно выбирать направление сортировки. По возрастанию даты строят графики трендов, по убыванию – получают последние показатели. Использование сортировки вместе с условным форматированием помогает выделять аномалии и закономерности без ручного анализа всех строк.
Советы по оптимизации:
- Не сортируйте сразу всю таблицу, если интересует один столбец – это снижает нагрузку.
- Используйте предварительную фильтрацию перед сортировкой, чтобы исключить лишние строки.
- Регулярно обновляйте индексы или ключи, если таблица часто меняется, чтобы сортировка оставалась быстрой.
В итоге правильная сортировка не только ускоряет поиск, но и повышает точность анализа. Она превращает массивы данных в управляемый инструмент, позволяющий принимать решения на основе четкой и структурированной информации.
Объединение таблиц: использование связей и ключей
При работе с реляционными базами данных ключи играют решающую роль в объединении таблиц. Первичный ключ обеспечивает уникальность каждой записи в таблице, тогда как внешний ключ связывает данные между таблицами, создавая ссылочную целостность. Например, таблица «Заказы» может содержать внешний ключ customer_id, который указывает на primary key таблицы «Клиенты».
Типы объединений определяют способ соединения данных. INNER JOIN возвращает только совпадающие записи, LEFT JOIN добавляет все строки из левой таблицы, а RIGHT JOIN – из правой. Использование FULL OUTER JOIN позволяет объединять таблицы, сохраняя данные, даже если для некоторых записей отсутствуют соответствия в другой таблице.
Для эффективного соединения таблиц важно индексировать поля, участвующие в JOIN. Индексы по внешним ключам ускоряют поиск соответствующих записей и снижают нагрузку на сервер при сложных запросах с тысячами строк. Без индекса объединение больших таблиц может выполняться значительно медленнее.
Сложные объединения можно строить через несколько связей. Например, при анализе продаж одновременно объединяют таблицы «Заказы», «Клиенты» и «Товары» через цепочку ключей: order.customer_id → customer.id и order.product_id → product.id. Это позволяет строить детализированные отчеты по клиентам и товарным категориям.
Особое внимание следует уделять согласованности типов данных в связанных полях. Несоответствие форматов, например INT и VARCHAR, приведет к ошибкам или некорректным результатам. Рекомендуется использовать единый тип данных и, при необходимости, нормализовать значения перед объединением.
Для проверки корректности связей удобно использовать COUNT и EXISTS в запросах. Эти функции помогают выявить записи, которые не имеют соответствующих связей, и позволяют корректировать внешние ключи до выполнения объединений. Такой подход минимизирует риск потери данных при сложных аналитических задачах.
Подсчет, суммирование и агрегация значений

Суммирование значений позволяет анализировать финансовые и количественные показатели. При работе с оборотом продаж эффективнее использовать SUM с группировкой по регионам или менеджерам, что дает точные данные для планирования и распределения ресурсов.
Агрегация данных выходит за рамки простого суммирования. Она включает:
- Среднее значение (AVG) для оценки средней цены или выручки;
- Минимальные и максимальные значения (MIN, MAX) для выявления крайних показателей;
- Подсчет уникальных элементов (COUNT DISTINCT) для анализа ассортимента или клиентов.
Комбинирование нескольких функций агрегации позволяет строить комплексные отчеты. Например, для анализа эффективности рекламной кампании можно одновременно подсчитать количество показов, суммировать затраты и вычислить среднюю стоимость клика, чтобы сравнивать каналы продвижения.
Для повышения точности работы с таблицами рекомендуется предварительно фильтровать данные и проверять корректность типов значений. Неправильно учтенные пустые или текстовые поля могут исказить результаты суммирования и средних значений, особенно при массовой обработке транзакций.
Экспорт и импорт таблиц для работы с внешними источниками
Экспорт таблиц позволяет оперативно передавать данные в сторонние приложения и форматы, такие как CSV, XLSX или JSON. Для корректного экспорта рекомендуется заранее проверять типы данных в каждой колонке, особенно даты и числовые значения с плавающей запятой, чтобы избежать искажения информации. При работе с большими объемами данных стоит использовать пакетный экспорт и включать опцию сжатия, например ZIP, чтобы снизить нагрузку на сеть и ускорить передачу файлов. Также важно учитывать кодировку символов: UTF-8 обеспечивает совместимость с большинством аналитических и BI-платформ.
Импорт таблиц из внешних источников требует точного соответствия структуры данных и форматов. Рекомендуется предварительно проверять наличие обязательных полей и уникальных идентификаторов, особенно при объединении с существующими базами. Использование автоматических проверок типов данных и обработка ошибок на этапе импорта позволяет минимизировать пропуски и дубли. Для регулярного обновления данных целесообразно настроить периодические загрузки через API или интеграционные инструменты, что сокращает ручной труд и снижает вероятность ошибок при синхронизации таблиц с внешними источниками.
Вопрос-ответ:
Какие основные операции можно выполнять с таблицами в текстовом редакторе?
С таблицами можно работать различными способами: добавлять или удалять строки и столбцы, объединять ячейки, изменять их размеры и выравнивание, сортировать данные и применять простые формулы для вычислений. Это позволяет структурировать информацию, делать документы более понятными и удобными для восприятия.
Как объединение и разделение ячеек влияет на оформление таблицы?
Объединение ячеек помогает создавать заголовки или блоки данных, которые занимают несколько строк или столбцов, что делает таблицу визуально более понятной. Разделение ячеек позволяет выделить отдельные элементы и детализировать информацию, облегчая сравнение и анализ данных внутри таблицы.
В каких случаях полезно использовать сортировку данных в таблице?
Сортировка помогает быстро находить нужные элементы и упорядочивать данные по алфавиту, числовым значениям или дате. Например, в списке контактов можно отсортировать фамилии, чтобы ускорить поиск, а в финансовой таблице — расположить суммы по возрастанию или убыванию для анализа расходов.
Можно ли в таблицах автоматически выполнять расчёты и как это делается?
Да, большинство текстовых и табличных редакторов позволяют использовать формулы для суммирования, вычисления среднего значения, нахождения минимальных и максимальных значений. Для этого выбираются нужные ячейки, вводится соответствующая формула, и программа автоматически выполняет расчёт, обновляя результаты при изменении данных.
Какие приёмы помогают сделать таблицу более наглядной и читаемой?
Для удобства восприятия можно использовать заливку ячеек разными цветами, выделять границы или изменять толщину линий. Также полезно выравнивать текст по центру или по левому краю, использовать жирный шрифт для заголовков и аккуратно располагать столбцы с числами и текстом. Такие приёмы помогают быстрее ориентироваться в таблице и облегчить сравнение информации.
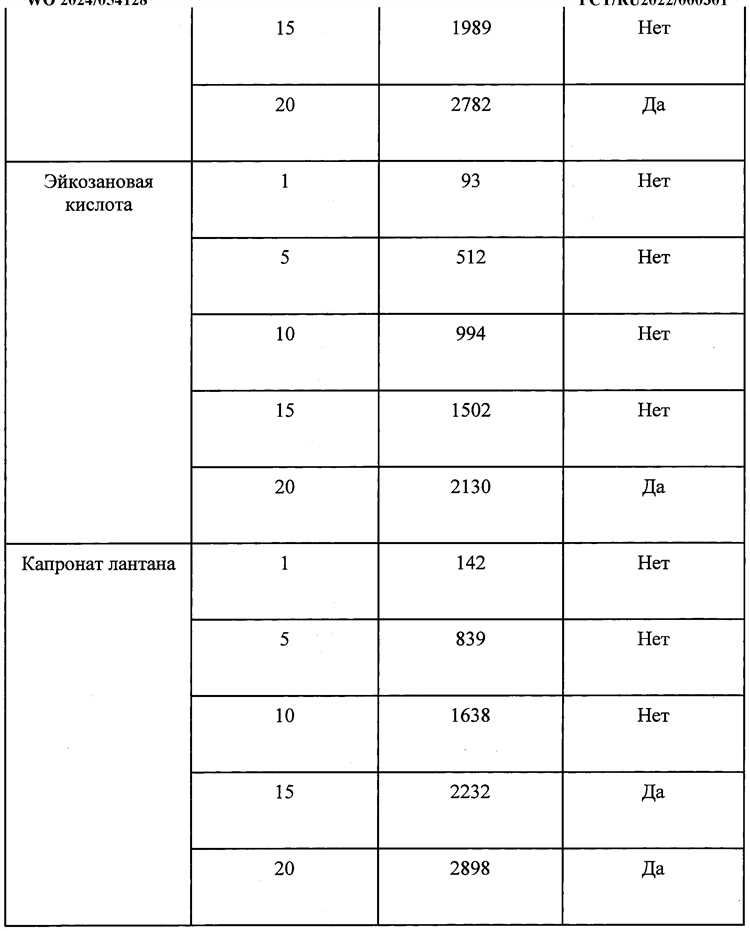
Какие базовые операции можно выполнять с таблицами в текстовых документах и таблицах данных?
С таблицами можно выполнять разнообразные действия, которые помогают упорядочить информацию и сделать её более наглядной. Например, можно добавлять или удалять строки и столбцы, объединять или разделять ячейки, сортировать данные по определённым критериям, а также фильтровать записи. Дополнительно часто используют изменение формата ячеек: настройку шрифта, цвета, границ, выравнивания текста. Эти возможности позволяют сделать таблицу более читаемой и удобной для анализа информации.
Как использование функций и формул влияет на работу с таблицами?
Функции и формулы расширяют возможности таблиц, позволяя автоматически выполнять вычисления и анализировать данные. Например, можно суммировать значения, находить среднее, максимум или минимум в диапазоне ячеек, создавать условные формулы, которые изменяют результат в зависимости от данных, или объединять данные из нескольких ячеек. Применение формул ускоряет работу с большим количеством информации, снижает вероятность ошибок при подсчётах и делает таблицу более интерактивной и гибкой при изменении исходных данных.