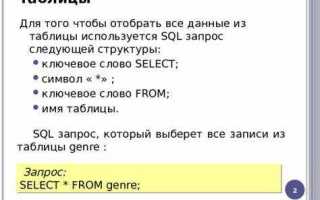
Дубликаты в таблицах возникают из-за повторных загрузок данных, отсутствия ограничений уникальности или ошибок при объединении источников. В SQL их поиск сводится не к абстрактному анализу, а к четкому пониманию, по каким полям запись считается повторяющейся и в каком виде нужен результат: агрегированный список значений или полный набор строк.
На практике чаще всего требуется ответить на конкретные вопросы: какие значения встречаются более одного раза, сколько раз они повторяются и какие именно строки участвуют в повторе. Для этого применяются GROUP BY, фильтрация через условия агрегации и запросы, возвращающие исходные данные без потери контекста. Выбор подхода напрямую зависит от структуры таблицы и цели анализа.
Отдельного внимания заслуживают ситуации, когда дубликаты определяются не одним столбцом, а их комбинацией, либо когда повторяемость нужно проверить только в пределах заданного диапазона данных. SQL предоставляет инструменты, позволяющие решать эти задачи без изменения схемы базы и без удаления данных, что особенно важно при диагностике проблем и подготовке отчетов.
Определение дубликатов по одному столбцу с помощью GROUP BY

Если дубликат определяется значением одного поля, задача сводится к группировке строк по этому столбцу и подсчету количества вхождений. Чаще всего это используется для поиска повторяющихся идентификаторов клиентов, адресов электронной почты или номеров документов, которые по логике данных должны быть уникальными.
Ключевой элемент такого запроса – оператор GROUP BY, примененный к анализируемому столбцу. В паре с агрегатной функцией COUNT() он позволяет получить количество строк для каждого значения. Далее отбираются только те группы, где количество записей больше единицы, что напрямую указывает на наличие повторов.
При формировании запроса важно учитывать тип данных столбца. Для строковых значений возможны ложные дубликаты из-за различий в регистре или пробелах, поэтому на этапе группировки часто применяются функции приведения регистра или очистки данных. Для числовых и идентификационных полей такие проблемы, как правило, отсутствуют.
Результат запроса по одному столбцу обычно используется как диагностический список: он показывает конкретные значения, которые нарушают ожидаемую уникальность, и количество их повторений. Эти данные затем применяются для проверки источников загрузки, настройки ограничений или последующего анализа связанных строк.
Поиск дубликатов по нескольким столбцам в таблице

Во многих прикладных задачах дубликат определяется не одним полем, а их комбинацией. Типичный пример – совпадение имени и даты рождения, артикула и склада, заказа и позиции. В таких случаях анализ одного столбца не выявит проблему, так как каждое значение по отдельности может быть корректным.
Для поиска повторяющихся строк используется группировка сразу по нескольким столбцам. SQL рассматривает такую комбинацию как составной ключ и объединяет строки только при полном совпадении всех указанных значений. Подсчет количества строк в каждой группе позволяет определить, какие сочетания встречаются более одного раза.
Важно заранее определить порядок и набор столбцов для проверки. Включение лишнего поля может скрыть дубликаты, а исключение значимого – привести к ложным совпадениям. Практика показывает, что состав проверяемых столбцов должен соответствовать бизнес-логике уникальности данных, а не текущей структуре таблицы.
Результаты поиска удобно анализировать в виде сводной таблицы, где каждая строка – это повторяющаяся комбинация значений с указанием количества записей.
| Столбец 1 | Столбец 2 | Количество строк |
|---|---|---|
| Значение A | Значение B | 3 |
| Значение C | Значение D | 2 |
Такая форма представления позволяет быстро определить масштаб проблемы и принять решение о дальнейших действиях: уточнении источника данных, корректировке логики загрузки или добавлении составных ограничений уникальности.
Использование HAVING для фильтрации повторяющихся строк
При поиске дубликатов важно понимать различие между фильтрацией исходных данных и отбором уже сгруппированных результатов. Условие для определения повторяемости формируется только после группировки, поэтому для этой задачи применяется HAVING, а не WHERE.
HAVING работает с результатами агрегатных функций и позволяет отсеивать группы по количеству строк, сумме значений или другим вычисленным показателям. В контексте дубликатов чаще всего используется проверка количества записей в группе, что дает точный контроль над тем, какие значения считаются повторяющимися.
Практический подход заключается в сочетании GROUP BY с HAVING, где первое формирует набор уникальных значений или их комбинаций, а второе оставляет только те группы, которые нарушают ожидаемую уникальность. Такой запрос возвращает компактный список проблемных данных без лишней информации.
HAVING также позволяет задавать более сложные условия, например учитывать только дубликаты, появившиеся определенное количество раз, или игнорировать единичные повторы. Это полезно при анализе больших таблиц, когда требуется сосредоточиться на системных ошибках, а не на единичных отклонениях.
Агрегированные запросы показывают, какие значения повторяются, но не раскрывают содержимое самих строк. Для анализа причин появления дубликатов и последующей очистки данных требуется получить полный набор записей, участвующих в повторе, со всеми полями таблицы.
На практике это достигается за счет связывания исходной таблицы с результатом группировки по проблемному столбцу или их комбинации. Такой подход позволяет отфильтровать только те строки, значения которых встречаются более одного раза, сохранив при этом исходную структуру данных.
Особое внимание стоит уделять ситуации, когда строки выглядят одинаково по ключевым полям, но различаются по служебным атрибутам: дате загрузки, источнику данных или статусу. Именно эти различия часто указывают на ошибки в логике импорта или обновления записей.
Поиск дубликатов с использованием оконных функций

Оконные функции позволяют находить дубликаты без агрегации и потери строк, что особенно полезно при анализе данных с большим количеством атрибутов. Они работают поверх набора строк и вычисляют значения в пределах заданного окна, не сокращая результат до одной строки на группу.
Чаще всего для выявления повторов применяется нумерация строк внутри логической группы, определяемой одним или несколькими столбцами. Каждой записи присваивается порядковый номер, который сразу показывает, является ли строка первой или относится к повторяющимся.
- Разбиение данных на группы по столбцам, определяющим уникальность записи
- Задание порядка внутри группы для выявления первичной и вторичных строк
- Отбор строк с номером больше единицы как явных дубликатов
Такой подход удобен при необходимости сохранить все строки и параллельно отметить повторы дополнительным вычисляемым полем. Это упрощает последующую фильтрацию, сортировку и анализ данных без вложенных запросов.
- Подходит для сложных таблиц с десятками столбцов
- Позволяет учитывать бизнес-приоритеты при выборе основной записи
- Упрощает подготовку данных к очистке и сравнению версий
Оконные функции поддерживаются большинством современных СУБД, что делает этот способ универсальным для поиска дубликатов в аналитических и прикладных задачах.
Выявление дубликатов с учетом условий WHERE
В реальных наборах данных дубликаты редко анализируются по всей таблице целиком. Чаще требуется ограничить проверку конкретным периодом, статусом записи или источником данных. Для этого условия отбора задаются через WHERE до выполнения группировки или оконных вычислений.
WHERE фильтрует исходные строки, формируя рабочий набор данных, внутри которого и определяется повторяемость значений. Это принципиально важно: дубликаты ищутся только среди строк, удовлетворяющих заданным условиям, а не во всей таблице, что позволяет получать корректные и управляемые результаты.
Типовые сценарии включают поиск повторов только среди активных записей, анализ дубликатов за конкретную дату загрузки или проверку данных одного подразделения. В каждом случае условия WHERE должны отражать бизнес-контекст, иначе выявленные повторы будут вводить в заблуждение.
Комбинация WHERE с группировкой или оконными функциями дает гибкий инструмент диагностики. Такой подход позволяет локализовать источник проблемы, не затрагивая исторические или нерелевантные данные, и сосредоточиться на конкретном участке таблицы.
Проверка дубликатов перед вставкой новых данных

Контроль дубликатов на этапе вставки данных позволяет избежать последующего анализа и очистки таблиц. Перед добавлением новой записи важно определить, какие поля формируют уникальность: один идентификатор или их сочетание, отражающее бизнес-логику объекта.
Проверка обычно строится на сравнении входящих значений с уже существующими строками. Если совпадение найдено, операция вставки блокируется или заменяется альтернативным действием, например обновлением записи. Такой подход особенно актуален для интеграций и пакетных загрузок.
При высокой нагрузке и параллельных вставках логическая проверка должна сочетаться с ограничениями уникальности на уровне базы данных. Это защищает от ситуаций, когда несколько транзакций одновременно проходят проверку, но создают дубликаты из-за гонки данных.
Регулярное использование предварительной проверки снижает объем некорректных данных, упрощает отчетность и позволяет поддерживать предсказуемую структуру таблиц без последующих операций по поиску и устранению повторов.
Вопрос-ответ:
Почему запрос с GROUP BY показывает дубликаты, но не возвращает сами строки?
GROUP BY объединяет строки с одинаковыми значениями в одну группу, поэтому результат содержит только агрегированные данные: значение столбца и количество повторов. Сами строки при этом теряются, так как запрос работает уже не с исходной таблицей, а с результатом группировки. Чтобы получить полный набор записей, используется соединение с исходной таблицей или оконные функции, которые не сокращают количество строк.
Как определить дубликаты, если уникальность задается несколькими столбцами?
В этом случае повторяемость определяется совпадением всех выбранных столбцов одновременно. Проверка строится на группировке по их комбинации или разбиении данных на окна по тем же полям. Важно включать только те столбцы, которые действительно описывают уникальность записи, иначе можно получить ложные совпадения или не заметить реальные повторы.
Можно ли искать дубликаты только среди части данных, например за один день?
Да, для этого применяется условие WHERE, которое отбирает строки до выполнения анализа повторов. Если фильтрация задана корректно, дубликаты будут искаться только внутри выбранного диапазона данных. Такой подход часто используется при проверке загрузок, когда нужно проанализировать конкретную дату, пакет или источник.
Чем оконные функции удобнее вложенных запросов при поиске дубликатов?
Оконные функции позволяют сохранить все строки и одновременно вычислить признаки повторяемости, например порядковый номер внутри группы. Это упрощает чтение запроса и дает возможность сразу увидеть различия между строками-дубликатами, такие как время создания или источник данных, без дополнительных соединений.