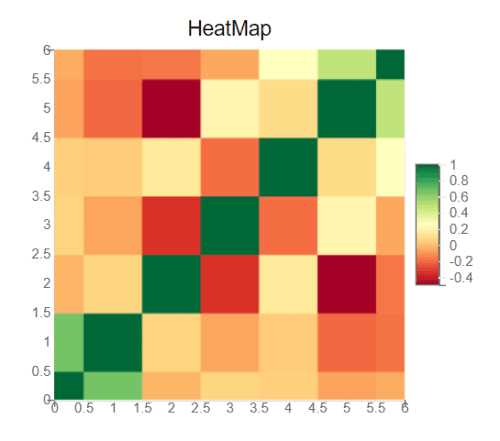
Heatmap – это инструмент визуального анализа, позволяющий выявлять закономерности в двумерных массивах данных за счёт цветового кодирования значений. В Python такие графики чаще всего применяются при анализе корреляций, мониторинге метрик, исследовании поведения пользователей и обработке результатов экспериментов. Ключевая особенность heatmap заключается в том, что она позволяет быстро определить области концентрации высоких и низких значений без сложных вычислений.
Для построения тепловых карт в Python обычно используются библиотеки matplotlib и seaborn, где последняя предоставляет более высокий уровень абстракции и удобные параметры настройки. Работа с heatmap почти всегда начинается с подготовки данных в формате pandas DataFrame, где строки и столбцы имеют осмысленные подписи, а значения представлены числовыми типами. Ошибки на этом этапе приводят к искажённой визуализации, поэтому корректная структура данных имеет решающее значение.
Практическая ценность heatmap напрямую зависит от грамотной настройки цветовой палитры, диапазона значений и подписей. Неподходящая шкала может скрыть важные различия между ячейками, а отсутствие аннотаций усложняет интерпретацию графика. В статье рассматривается пошаговый процесс построения heatmap в Python – от загрузки и очистки данных до сохранения готового изображения для отчёта или презентации.
Подготовка табличных данных для визуализации тепловой карты
Тепловая карта в Python строится на основе двумерного массива числовых значений, поэтому исходные данные необходимо привести к формату pandas DataFrame, где строки и столбцы отражают логические категории, а каждая ячейка содержит одно число. На практике это означает предварительную агрегацию данных: подсчёт средних значений, сумм, долей или коэффициентов вместо хранения «сырых» записей.
Перед визуализацией важно проверить типы данных. Все значения, используемые для окрашивания ячеек, должны иметь числовой тип (int или float). Столбцы с объектным типом необходимо преобразовать с помощью astype() или to_numeric(). Наличие строковых значений или смешанных типов приводит к ошибкам при построении heatmap или некорректной цветовой интерпретации.
Пропущенные значения требуют отдельного внимания. По умолчанию библиотеки визуализации отображают такие ячейки пустыми или окрашивают их в нейтральный цвет, что может исказить восприятие данных. В зависимости от задачи пропуски заполняют медианой, средним значением по строке или столбцу, либо удаляют целые строки и столбцы с чрезмерным количеством NaN.
Для корректного отображения осей необходимо явно задать индексы и названия столбцов DataFrame. Индекс должен быть осмысленным и уникальным, так как он используется для подписи строк на тепловой карте. При работе с временными рядами рекомендуется преобразовывать даты в читаемый формат или группировать их по периодам до построения графика.
Завершающим этапом подготовки данных является нормализация диапазона значений. Если в одном массиве присутствуют числа с сильно различающимися масштабами, цветовая шкала будет смещена в сторону экстремальных значений. В таких случаях применяют масштабирование или ограничение диапазона, чтобы тепловая карта отражала относительные различия между ячейками, а не только максимумы и минимумы.
Выбор библиотек Python для построения heatmap и их установка
Для построения тепловых карт в Python чаще всего используются matplotlib и seaborn. Matplotlib отвечает за базовую отрисовку графиков и управление осями, а seaborn расширяет его функциональность, предоставляя готовую функцию heatmap() с поддержкой аннотаций, цветовых палитр и автоматического масштабирования. Использование только matplotlib оправдано в случаях, когда требуется полный контроль над низкоуровневыми параметрами визуализации.
Библиотека pandas является обязательным компонентом, так как именно DataFrame используется в качестве основного контейнера данных для heatmap. Seaborn напрямую работает с pandas-структурами, что упрощает настройку подписей осей и порядок отображения значений. Без pandas подготовка данных для тепловой карты требует дополнительных преобразований массивов NumPy.
Установка стандартного набора библиотек выполняется через пакетный менеджер pip. Для актуальных версий Python рекомендуется использовать одну команду установки matplotlib, seaborn и pandas, так как они совместимы по зависимостям. При работе в изолированной среде целесообразно предварительно создать виртуальное окружение, чтобы избежать конфликтов версий с уже установленными пакетами.
После установки важно проверить версии библиотек. Seaborn активно использует функции matplotlib, и устаревшая версия последнего может привести к ошибкам при рендеринге цветовых шкал или аннотаций. Минимально допустимые версии обычно указаны в документации seaborn, поэтому их несоблюдение напрямую влияет на корректность построения heatmap.
В задачах, связанных с интерактивной визуализацией, дополнительно применяются библиотеки plotly или bokeh. Они позволяют масштабировать heatmap, отображать всплывающие значения и встраивать графики в веб-приложения. Однако для пошагового построения и анализа данных в скриптах и ноутбуках связка pandas, matplotlib и seaborn остаётся основной.
Создание базовой heatmap с использованием seaborn
Базовая тепловая карта в seaborn строится на основе двумерного объекта данных, чаще всего DataFrame. Каждая строка и столбец автоматически преобразуются в подписи осей, а числовые значения используются для расчёта цветовой интенсивности. Перед построением важно убедиться, что порядок строк и столбцов соответствует логике анализа, так как seaborn отображает данные строго в том виде, в каком они переданы.
Минимальный набор параметров функции heatmap() уже позволяет получить информативную визуализацию, однако поведение по умолчанию не всегда подходит для прикладных задач. Наиболее часто используемые параметры определяют внешний вид и читаемость графика:
- включение аннотаций значений в ячейках для точной интерпретации данных;
- задание формата чисел для отображения дробных значений;
- отключение автоматического сглаживания границ между ячейками.
Размер графика следует задавать заранее через параметры фигуры matplotlib, так как плотные матрицы с большим количеством строк и столбцов быстро теряют читаемость. Для массивов размером более 20×20 рекомендуется увеличивать ширину и высоту графика, иначе подписи осей будут перекрываться.
При первом построении heatmap полезно явно задать параметр cbar, отвечающий за отображение цветовой шкалы. Наличие шкалы позволяет сопоставлять цвета с конкретными числовыми значениями и быстро оценивать диапазон данных. Для компактных визуализаций шкалу можно отключить, если значения уже подписаны внутри ячеек.
Типичный порядок действий при создании базовой тепловой карты выглядит следующим образом:
- передача подготовленного DataFrame в функцию heatmap();
- настройка отображения чисел и цветовой шкалы;
- корректировка размеров фигуры и ориентации подписей осей;
Такой подход позволяет получить корректную и наглядную heatmap без избыточной настройки, сохранив возможность дальнейшего расширения визуализации под конкретные требования анализа.
Настройка цветовой шкалы и диапазона значений
Цветовая шкала определяет, как числовые значения отображаются визуально, поэтому её выбор напрямую влияет на интерпретацию heatmap. В seaborn палитра задаётся через параметр cmap, который принимает как предустановленные схемы matplotlib, так и пользовательские градиенты. Для данных с естественным порядком значений подходят последовательные палитры, а для отклонений относительно опорной точки – дивергентные.
Диапазон значений необходимо контролировать вручную с помощью параметров vmin и vmax. Если оставить их неопределёнными, шкала будет строиться по минимальному и максимальному значениям массива, что часто приводит к смещению цветового контраста из-за выбросов. Фиксированный диапазон позволяет сравнивать несколько тепловых карт между собой без искажения визуального восприятия.
При анализе данных с симметричными отклонениями удобно использовать центральную точку шкалы, задаваемую параметром center. Это особенно полезно для корреляционных матриц или разностей показателей, где нулевое значение имеет смысловой приоритет. В этом случае отрицательные и положительные значения окрашиваются в разные направления градиента.
Для повышения читаемости важно учитывать плотность значений. Если большая часть данных сосредоточена в узком диапазоне, стандартная линейная шкала делает различия малозаметными. В таких ситуациях применяют логарифмическое преобразование данных до визуализации либо ограничивают диапазон значений, исключая экстремумы.
Цветовая шкала должна интерпретироваться однозначно, поэтому рекомендуется явно настраивать подписи и деления цветовой панели. Это позволяет сопоставлять цвет с числом без догадок и исключает ошибки при анализе тепловой карты, особенно в отчётах и презентациях, где график используется без поясняющего кода.
Отображение подписей осей и значений ячеек
Подписи осей формируются на основе индексов и названий столбцов DataFrame, поэтому их читаемость напрямую зависит от структуры данных. Короткие и однозначные названия позволяют избежать визуального шума, а при длинных подписях рекомендуется поворачивать метки осей, чтобы они не перекрывались. Для категориальных данных порядок подписей следует задавать заранее, так как автоматическая сортировка может исказить смысл отображения.
Значения внутри ячеек включаются параметром аннотаций и используются для точного анализа без обращения к цветовой шкале. Такой подход особенно полезен при работе с небольшими матрицами или при подготовке аналитических отчётов, где требуется видеть конкретные числа. Формат отображения чисел необходимо настраивать в зависимости от диапазона данных, чтобы избежать избыточного количества знаков после запятой.
При настройке подписей и аннотаций важно учитывать плотность данных. Наиболее распространённые приёмы включают:
- отключение аннотаций для матриц с большим количеством ячеек;
- уменьшение размера шрифта для сохранения читаемости;
- выравнивание текста по центру ячейки для корректного восприятия.
Для осей с временными или числовыми индексами полезно явно управлять форматом подписей. Округление дат до периодов или сокращение числовых значений упрощает визуальный анализ и снижает нагрузку на восприятие. При необходимости подписи можно полностью скрыть, если они дублируют информацию, уже представленную в контексте графика.
Проверка итогового отображения подписей должна выполняться до сохранения heatmap. Даже корректно настроенные параметры могут давать нежелательный результат при изменении размера фигуры или экспорте в изображение, поэтому визуальная валидация является обязательным этапом подготовки графика.
Работа с пропущенными и аномальными данными на heatmap
Пропущенные значения в исходных данных напрямую отражаются на тепловой карте и могут создавать визуальные разрывы или нейтральные области. По умолчанию seaborn не закрашивает ячейки с NaN, поэтому такие зоны легко пропустить при анализе. Перед построением heatmap необходимо определить допустимую долю пропусков и принять решение о способе их обработки.
Наиболее распространённые стратегии включают удаление строк или столбцов с высокой концентрацией пропусков либо заполнение значений агрегированными показателями. Для временных и пространственных данных часто используют интерполяцию, тогда как для категориальных срезов предпочтительнее медианные или средние значения по группе. Выбранный метод должен соответствовать логике данных, иначе тепловая карта будет отражать не реальные закономерности, а результат заполнения.
Аномальные значения представляют отдельную проблему, так как они растягивают цветовую шкалу и делают различия между остальными ячейками малозаметными. Для выявления таких значений рекомендуется предварительно анализировать распределение данных и фиксировать допустимые границы. Значения за пределами этих границ либо исключаются, либо ограничиваются до заданного порога перед визуализацией.
В случаях, когда пропуски или выбросы несут аналитическую нагрузку, их следует отображать явно. Это достигается настройкой отдельного цвета для отсутствующих значений или использованием маски, которая подчёркивает проблемные зоны на heatmap. Такой подход позволяет сохранить целостность визуализации и одновременно обратить внимание на качество данных.
После обработки пропущенных и аномальных значений важно повторно проверить диапазон данных и параметры цветовой шкалы. Даже незначительные изменения в массиве могут изменить распределение цветов, поэтому корректировка визуальных настроек является обязательным шагом перед финальным использованием тепловой карты.
Построение heatmap из корреляционной матрицы
Корреляционная heatmap строится на основе матрицы коэффициентов связи между числовыми признаками. В pandas такая матрица формируется методом corr(), который по умолчанию вычисляет коэффициент Пирсона. Перед расчётом необходимо исключить нечисловые столбцы, так как их присутствие приводит к некорректным результатам или пустым значениям.
Полученная корреляционная матрица является симметричной, а значения располагаются в диапазоне от -1 до 1. Это требует использования дивергентной цветовой шкалы с центральной точкой в нуле. Такое отображение позволяет визуально разделить положительные и отрицательные связи и быстро определить пары признаков с выраженной зависимостью.
Для повышения читаемости часто применяют маскирование одной из треугольных частей матрицы. Это снижает визуальную нагрузку и устраняет дублирование информации, так как значения выше и ниже главной диагонали идентичны. Диагональные элементы, равные единице, также можно скрыть, если они не несут аналитической ценности.
Аннотации числовых значений полезны при детальном анализе, однако при большом количестве признаков они перегружают график. В таких случаях рекомендуется оставить только цветовую интерпретацию и ориентироваться на шкалу. Для компактных наборов данных отображение коэффициентов с округлением до двух знаков упрощает интерпретацию связей.
Перед сохранением корреляционной heatmap важно проверить порядок признаков. Логическая группировка или предварительная сортировка столбцов помогает выявить блоки взаимосвязанных переменных и делает визуализацию более наглядной при анализе многомерных данных.
Сохранение и экспорт heatmap в файл изображения
После построения тепловой карты её необходимо зафиксировать в виде файла изображения, чтобы использовать результат вне среды выполнения Python. Для этого применяется функция сохранения фигуры matplotlib, которая экспортирует текущее состояние графика без повторной отрисовки. Перед сохранением важно завершить все настройки размеров, подписей и цветовой шкалы, так как файл будет точной копией отображаемого объекта.
Качество итогового изображения напрямую зависит от разрешения. Параметр плотности точек определяет, насколько чётко будут выглядеть подписи осей, аннотации и границы ячеек. Для публикаций и отчётов рекомендуется использовать повышенные значения, тогда как для предварительного анализа допустимы стандартные настройки.
Формат файла следует выбирать в зависимости от сценария использования. Растровые форматы подходят для презентаций и документов, а векторные сохраняют масштабируемость и точность линий при последующем редактировании. Основные различия между форматами экспорта приведены ниже.
| Формат | Особенности применения |
|---|---|
| PNG | Поддержка прозрачности, подходит для отчётов и презентаций |
| JPEG | Меньший размер файла, возможна потеря чёткости текста |
| SVG | Векторное представление, удобно для публикаций и редактирования |
| Используется для печати и встраивания в аналитические отчёты |
Перед экспортом рекомендуется отключить лишние элементы, такие как пустые отступы или невидимые подписи. Параметры автоматической обрезки позволяют уменьшить поля вокруг графика и сделать изображение компактным без ручной правки.
После сохранения файла необходимо открыть изображение вне среды Python и проверить читаемость всех элементов. Масштабирование, применяемое в просмотрщиках и документах, может выявить проблемы, которые не были заметны при отображении heatmap в интерактивном режиме.
Вопрос-ответ:
Почему heatmap может выглядеть «пустой» или с одинаковыми цветами во всех ячейках?
Чаще всего причина связана с диапазоном значений. Если в данных присутствуют выбросы, автоматическая цветовая шкала растягивается под них, а остальные значения визуально сливаются. Решение — задать границы шкалы вручную или предварительно ограничить экстремальные значения. Также стоит проверить, что в DataFrame действительно находятся числовые данные, а не строки.
Нужно ли всегда использовать seaborn для построения heatmap?
Нет, использование seaborn не является обязательным. Heatmap можно построить и средствами matplotlib, но это потребует большего количества настроек вручную. Seaborn удобен, когда требуется быстро получить читаемую визуализацию с подписями осей и цветовой шкалой без детальной низкоуровневой настройки.
Как корректно сравнивать несколько heatmap между собой?
Для сравнения нескольких тепловых карт необходимо использовать одинаковую цветовую палитру и фиксированный диапазон значений. Если шкалы отличаются, визуальные различия могут быть следствием настроек, а не данных. Также рекомендуется сохранять одинаковые размеры фигур и порядок строк и столбцов.
Что делать, если подписи осей накладываются друг на друга?
Проблема возникает при большом количестве категорий или длинных названиях. Обычно помогает поворот подписей осей, увеличение размера фигуры или сокращение текстов до аббревиатур. В некоторых случаях разумно скрыть часть подписей, если они не участвуют в интерпретации графика.
Подходит ли heatmap для анализа больших наборов данных?
Heatmap лучше всего работает с агрегированными данными. Для массивов с сотнями строк и столбцов визуализация теряет читаемость и превращается в цветовое поле без чётких ориентиров. В таких случаях сначала выполняют группировку или расчёт сводных показателей, а затем строят тепловую карту по уменьшенному набору признаков.
Почему значения на heatmap выглядят искажёнными после нормализации данных?
Искажение обычно связано с тем, что нормализация применяется ко всему набору данных без учёта структуры матрицы. Например, масштабирование по всем столбцам сразу может скрыть различия внутри отдельных строк. Перед построением heatmap стоит проверить, по какой оси выполняется преобразование, и соответствует ли оно задаче анализа. В ряде случаев логичнее нормализовать значения по строкам или столбцам отдельно, а затем фиксировать диапазон цветовой шкалы, чтобы сохранить сопоставимость визуализации.