Содержание статьи

UTF 16LE – это форма кодировки UTF-16 с порядком байтов Little Endian, где младший байт символа записывается первым. В отличие от UTF-8, каждый символ обычно занимает 2 байта, а для некоторых символов вне базовой многоязычной плоскости используется 4 байта, что важно учитывать при обработке бинарных файлов.
Определение правильной кодировки файла позволяет избежать появления некорректных символов или «кракозябр». Для этого стоит проверять наличие BOM (Byte Order Mark), который в UTF 16LE представлен байтами FF FE. Если BOM отсутствует, анализ первых нескольких байтов текста поможет выявить порядок следования байтов.
Расшифровка UTF 16LE напрямую зависит от корректной интерпретации последовательности байтов. В практических сценариях удобно использовать стандартные инструменты, например, Python с функцией decode(‘utf-16le’) или текстовые редакторы, поддерживающие выбор кодировки при открытии файла.
При работе с UTF 16LE важно учитывать различия с UTF 16BE: один и тот же набор байтов даст совершенно другой результат при неверной интерпретации порядка. Также стоит заранее планировать преобразование текста в другие кодировки, например UTF-8 или ANSI, чтобы сохранить корректное отображение символов и избежать потери данных.
Как определить, что файл использует UTF 16LE
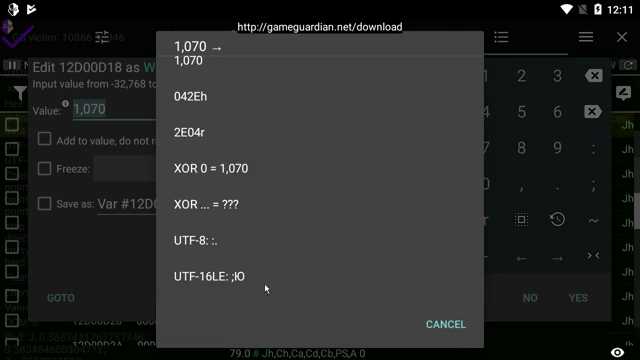
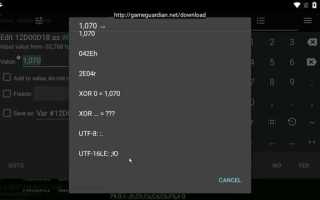
Первый способ определения кодировки – проверка наличия BOM (Byte Order Mark). В UTF 16LE BOM представлен двумя байтами FF FE в начале файла. Если эти байты присутствуют, можно с высокой вероятностью считать файл UTF 16LE.
Если BOM отсутствует, анализ последовательности байтов позволяет выявить порядок. В UTF 16LE младший байт символа идет первым, старший – вторым. Например, латинская буква «A» кодируется как 41 00, а не 00 41, что отличает её от UTF 16BE.
Дополнительно можно использовать текстовые редакторы или специализированные утилиты, которые показывают кодировку при открытии файла. В системах Linux команда file -i имя_файла часто отображает кодировку, а в Windows PowerShell доступна проверка через Get-Content -Encoding Byte с последующим анализом первых двух байтов.
Для автоматизации проверки в скриптах Python рекомендуется читать первые несколько символов в бинарном режиме и пробовать декодировать с помощью ‘utf-16le’. Если декодирование проходит без ошибок и символы отображаются корректно, файл действительно использует UTF 16LE.
Различие между UTF-16LE и UTF-16BE на практике
UTF-16LE и UTF-16BE различаются порядком байтов при записи символов. В UTF-16LE младший байт записывается первым, а старший вторым. В UTF-16BE – наоборот: старший байт идет первым. Например, символ «A» в UTF-16LE представлен как 41 00, а в UTF-16BE – как 00 41. Неправильная интерпретация порядка приводит к некорректному отображению текста.
При открытии файла без BOM важно учитывать эти различия, особенно при работе с бинарными данными. Текстовые редакторы, которые автоматически определяют кодировку, могут ошибаться, поэтому проверка первых символов вручную помогает подтвердить порядок байтов.
Для скриптовых решений в Python можно использовать разные декодеры: decode(‘utf-16le’) для LE и decode(‘utf-16be’) для BE. Тестирование на небольшом фрагменте текста позволяет выявить правильную кодировку до обработки всего файла.
При преобразовании текста в другие кодировки, например UTF-8, соблюдение правильного порядка байтов предотвращает появление мусора и некорректных символов. Это особенно важно при интеграции с базами данных и сетевыми приложениями.
Пошаговое преобразование байтов UTF 16LE в символы
Для преобразования UTF 16LE в текст сначала необходимо читать файл в бинарном режиме, чтобы получить последовательность байтов без интерпретации кодировки. В Python это делается через open(‘файл’, ‘rb’).
Далее байты группируются по два для базовой многоязычной плоскости. Первый байт группы – младший, второй – старший. Например, последовательность 41 00 соответствует символу «A».
Для символов вне базовой плоскости используются четыре байта: два младших байта для первого суррогатного кода и два старших байта для второго. Корректное объединение этих пар позволяет получить исходный символ.
После формирования байтовых пар применяется декодирование. В Python это реализуется через bytes_object.decode(‘utf-16le’), что автоматически преобразует пары в Unicode-символы.
Если при декодировании появляются ошибки, необходимо проверить целостность байтов и наличие BOM. Отсутствие целого числа байтов или неверный порядок приведет к неправильным символам или исключениям.
Использование Python для декодирования UTF 16LE
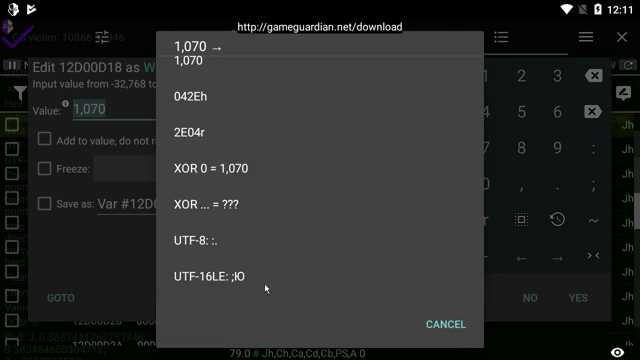
Python предоставляет встроенные возможности для работы с UTF 16LE, включая чтение бинарных файлов и декодирование байтов в текст.
Основные шаги:
- Открыть файл в бинарном режиме: with open(‘файл.txt’, ‘rb’) as f:
- Прочитать данные в виде байтов: data = f.read()
- Декодировать байты в строку Unicode: text = data.decode(‘utf-16le’)
При работе с большими файлами рекомендуется считывать данные блоками:
- Использовать f.read(1024) для чтения по 1024 байта за раз.
- Следить, чтобы блоки содержали четное число байтов, иначе символы будут обрезаны.
- Декодировать каждый блок отдельно и объединять результаты в одну строку.
Для обработки ошибок можно добавить параметр errors=’replace’ или errors=’ignore’ при декодировании, чтобы избежать прерывания скрипта при некорректных байтах.
Также Python позволяет конвертировать текст из UTF 16LE в другие кодировки с помощью text.encode(‘utf-8’), что полезно для интеграции с системами, поддерживающими только UTF-8.
Работа с текстовыми редакторами при открытии UTF 16LE
Текстовые редакторы по-разному обрабатывают файлы в кодировке UTF 16LE, особенно при отсутствии BOM. Правильная настройка позволяет избежать некорректного отображения символов.
Рекомендации для работы с UTF 16LE:
- Перед открытием файла убедитесь, что редактор поддерживает выбор кодировки.
- Если редактор не определяет кодировку автоматически, вручную установите UTF-16LE.
- Для больших файлов используйте редакторы, способные работать с бинарными данными без преобразования, чтобы не повредить байты.
- Проверяйте отображение первых символов: некорректные символы или пустые квадраты указывают на неправильный порядок байтов.
- При необходимости конвертируйте файл в UTF-8 или другую кодировку через функции «Сохранить как» с выбором кодировки.
Примеры редакторов с поддержкой UTF 16LE:
- Notepad++ – выбор кодировки через меню Кодировка → Преобразовать в UTF-16 LE.
- Sublime Text – установка кодировки при открытии файла через диалог «Open with Encoding».
- Visual Studio Code – указание кодировки при открытии и сохранении файлов через панель состояния.
Ошибки и проблемы при неправильной расшифровке UTF 16LE
- Неверный порядок байтов – использование UTF-16BE вместо UTF-16LE приводит к отображению символов в обратном порядке.
- Отсутствие целого числа байтов – если файл содержит нечётное количество байтов, последняя пара символов обрезается или вызывает ошибки декодирования.
- Игнорирование BOM – без BOM редакторы и скрипты могут ошибочно определить кодировку, что приведёт к неправильному отображению.
- Повреждённые байты – частичные записи файлов или неверная обработка бинарных данных создают недопустимые последовательности.
Рекомендации по предотвращению проблем:
- Всегда проверять наличие BOM и, при необходимости, использовать его для корректного определения кодировки.
- При работе с Python или другими скриптами читать данные блоками, соблюдая кратность 2 байтам.
- Перед конвертацией в другую кодировку тестировать декодирование на небольшом фрагменте текста.
- Использовать редакторы, поддерживающие явный выбор UTF-16LE, чтобы избежать автоматической ошибки определения кодировки.
Преобразование UTF 16LE в другие кодировки
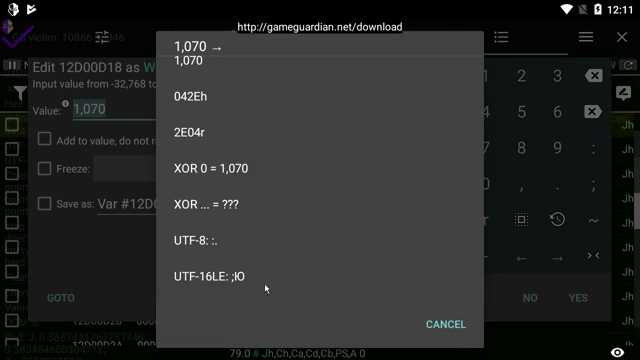
Преобразование текста из UTF 16LE в другие кодировки необходимо для совместимости с программами и системами, которые не поддерживают UTF-16. Основные шаги включают чтение исходного файла в бинарном режиме и последующее декодирование.
В Python процесс выглядит следующим образом:
- Открыть файл в бинарном режиме: with open(‘файл.txt’, ‘rb’) as f:
- Прочитать байты: data = f.read()
- Декодировать UTF 16LE: text = data.decode(‘utf-16le’)
- Преобразовать в целевую кодировку, например UTF-8: converted = text.encode(‘utf-8’)
- Сохранить результат: with open(‘файл_utf8.txt’, ‘wb’) as out: out.write(converted)
Важно учитывать следующие моменты:
- Неправильный порядок байтов приведёт к искажению символов, поэтому перед преобразованием проверяйте наличие BOM или корректность байтов.
- При конвертации в кодировки с ограниченным набором символов, например ANSI, неизвлекаемые символы могут быть заменены или потеряны. Используйте параметр errors=’replace’ при кодировании.
- Для больших файлов рекомендуется выполнять преобразование блоками, чтобы избежать переполнения памяти и сохранить целостность данных.
Чтение бинарных файлов с UTF 16LE без потери данных
При работе с бинарными файлами в кодировке UTF 16LE важно сохранять точную последовательность байтов, чтобы избежать повреждения символов. Чтение должно выполняться в бинарном режиме и учитывать порядок байтов.
Рекомендации по безопасному чтению:
| Действие | Описание |
|---|---|
| Открытие файла | Использовать бинарный режим: open(‘файл.bin’, ‘rb’), чтобы получить точные байты без интерпретации кодировки. |
| Считывание блоками | Читать файл блоками по 1024 или 2048 байт, соблюдая четность, чтобы не обрезать символы UTF 16LE. |
| Проверка BOM | Если в начале файла присутствует BOM FF FE, учитывать его при объединении блоков и декодировании. |
| Декодирование | Преобразовывать байты в текст с помощью decode(‘utf-16le’) после полного считывания или построчно для больших файлов. |
| Обработка ошибок | Использовать errors=’replace’ или errors=’ignore’ при декодировании, чтобы не прерывать процесс из-за поврежденных байтов. |
Следование этим шагам позволяет сохранить все символы исходного файла и корректно преобразовать их в текстовую форму без потерь данных.
Вопрос-ответ:
Как определить, что файл использует кодировку UTF 16LE?
Для определения UTF 16LE можно проверить наличие BOM (Byte Order Mark) в начале файла — это два байта FF FE. Если BOM отсутствует, анализ первых байтов помогает выявить порядок: в UTF 16LE младший байт символа идёт первым. Также можно использовать текстовые редакторы с возможностью выбора кодировки или команды типа file -i в Linux для проверки формата.
Чем UTF 16LE отличается от UTF 16BE при расшифровке текста?
Главное различие — порядок байтов. В UTF 16LE младший байт символа записывается первым, а старший вторым, тогда как в UTF 16BE — наоборот. Неправильная интерпретация порядка приводит к некорректному отображению текста, поэтому важно выбирать правильный декодер или явно указывать кодировку в редакторе или скрипте.
Какие ошибки чаще всего возникают при декодировании UTF 16LE?
Распространённые ошибки включают появление «кракозябр» при неверном порядке байтов, обрезку символов при нечётном количестве байтов, искажение текста из-за отсутствия BOM или повреждённых байтов. Для предотвращения ошибок рекомендуется проверять целостность байтов, соблюдать порядок при чтении блоками и использовать параметры errors=’replace’ или errors=’ignore’ при декодировании.
Как преобразовать текст из UTF 16LE в UTF-8 без потери данных?
Сначала файл читается в бинарном режиме, затем байты декодируются через decode(‘utf-16le’) в строку Unicode. После этого текст кодируется в UTF-8 с помощью encode(‘utf-8’) и сохраняется в новый файл. Для больших файлов рекомендуется работать блоками по 1024–2048 байт, чтобы сохранить целостность символов и избежать переполнения памяти.