При работе с реляционными базами данных часто требуется получать только те строки, где значения действительно участвуют в расчетах, аналитике или бизнес-логике. Нули и NULL в SQL – разные сущности, и их смешение приводит к искаженным результатам выборок, неверным агрегатам и ошибкам в отчетах. Поэтому корректная фильтрация ненулевых значений – базовый навык для любого разработчика и аналитика.
SQL не интерпретирует 0 как отсутствие данных. Это полноценное числовое значение, которое может быть допустимым результатом вычислений. В отличие от него, NULL обозначает неизвестное или отсутствующее значение и не участвует в стандартных арифметических операциях. Запросы вида WHERE column <> 0 и WHERE column IS NOT NULL решают разные задачи, и выбор условия напрямую зависит от структуры данных и цели запроса.
Ошибки при отборе ненулевых значений часто возникают в агрегатных функциях, объединениях таблиц и условиях фильтрации. Например, SUM() игнорирует NULL, но учитывает нули, а COUNT(column) и COUNT(*) дают разные результаты при наличии пустых значений. Без понимания этих нюансов невозможно получить корректные показатели при анализе продаж, логов, финансовых операций или пользовательской активности.
Практика показывает, что выборка ненулевых значений должна учитывать тип данных, бизнес-смысл поля и особенности используемой СУБД. Числовые, строковые и логические столбцы требуют разных подходов к фильтрации. Грамотно составленные условия WHERE позволяют избежать лишних проверок на уровне приложения и сделать SQL-запросы предсказуемыми по результату.
Использование условия WHERE для отбора значений больше нуля
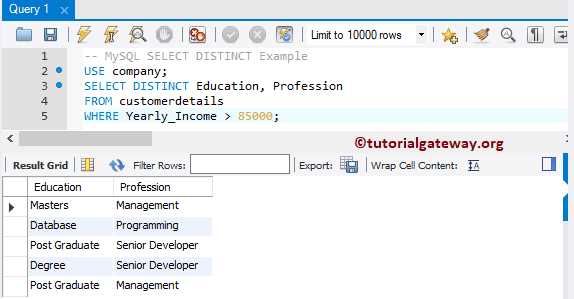
Условие WHERE с оператором сравнения > 0 применяется для отбора строк, в которых числовое поле содержит положительное значение. Такой подход подходит для колонок с количественными показателями: суммы платежей, количество товаров, начисленные баллы, длительность операций. Запрос вида WHERE amount > 0 исключает как нулевые значения, так и отрицательные, если они допустимы на уровне данных.
Важно учитывать, что сравнение с нулем автоматически исключает строки с NULL, так как любые операции сравнения с NULL возвращают неопределенный результат. Если требуется явно контролировать это поведение, условие можно расширить проверкой IS NOT NULL. Это упрощает анализ запросов и делает намерение разработчика очевидным при поддержке кода.
Для столбцов с типами INTEGER, DECIMAL и NUMERIC сравнение с нулем выполняется напрямую. Для полей с плавающей точкой рекомендуется учитывать возможные погрешности хранения значений. В таких случаях допустимо использовать пороговое значение, например проверку на > 0.0001, если данные получены в результате вычислений.
При фильтрации данных из связанных таблиц условие WHERE column > 0 влияет на результат объединений. В запросах с LEFT JOIN такое условие может превратить выборку в аналог INNER JOIN, так как строки без совпадений будут отброшены. Чтобы сохранить строки из основной таблицы, проверку на положительное значение следует переносить в условие соединения или обрабатывать отдельно.
Использование сравнения с нулем оправдано только тогда, когда бизнес-логика явно отделяет нулевое значение от положительного. Если ноль используется как маркер отсутствия данных, корректнее хранить такие записи как NULL и фильтровать их соответствующими условиями, избегая неоднозначной интерпретации результатов запроса.
Фильтрация строк с учетом NULL и ненулевых числовых данных
Корректная фильтрация данных требует явного разделения строк с NULL и строк с числовыми значениями. В SQL проверка вида column <> 0 не возвращает записи, где значение отсутствует, поэтому такие строки выпадают из выборки неявно. Если отсутствие данных имеет смысловую нагрузку, это поведение необходимо контролировать.
Для явного отбора строк с заданными числами используется сочетание условий IS NOT NULL и сравнения с нулем. Конструкция WHERE column IS NOT NULL AND column <> 0 гарантирует, что в результате останутся только строки с заполненными и отличными от нуля значениями. Такой подход особенно важен при формировании отчетов и расчетах, где пропущенные данные не должны маскироваться под нулевые.
При необходимости включить строки с NULL в результат, но исключить нули, применяются логические операторы. Пример WHERE column IS NULL OR column > 0 позволяет сохранить записи без значения и одновременно отфильтровать строки с нулевыми показателями. Это полезно при анализе неполных наборов данных или проверке заполненности колонок.
Использование функций подстановки значений, таких как COALESCE, требует осторожности. Замена NULL на 0 упрощает фильтрацию, но лишает возможности отличить отсутствие данных от реального нулевого значения. В большинстве сценариев предпочтительнее выполнять фильтрацию до применения таких функций.
Фильтрация с учетом NULL напрямую влияет на агрегатные вычисления. Например, предварительное исключение строк с отсутствующими значениями позволяет получить предсказуемые результаты при использовании SUM и AVG, а также избежать искажений, связанных с разной интерпретацией пустых и нулевых данных в отчетах.
Различие между проверкой на 0 и проверкой на NULL в запросах
Попытка использовать операторы = или <> для проверки NULL приводит к пустым результатам. Конструкции вида column <> NULL или column = NULL всегда дают неопределенный результат и не отбирают ни одной строки. Для работы с отсутствующими значениями применяются только выражения IS NULL и IS NOT NULL.
Различие особенно заметно в фильтрации данных для расчетов. Условие WHERE column > 0 исключает и нулевые, и NULL значения, но делает это неявно. Если требуется отделить строки с отсутствующими данными от строк с нулевым результатом, проверки должны быть разделены. Это позволяет точно контролировать логику выборки и избегать скрытых потерь данных.
В агрегатных функциях различие усиливается. SUM и AVG пропускают NULL, но учитывают нули, тогда как COUNT(column) не считает строки с отсутствующим значением, а COUNT(*) учитывает их. Непонимание этой разницы приводит к расхождениям между числом строк и фактическими значениями показателей.
Рекомендуется определять смысл нулевого значения на уровне модели данных. Если ноль обозначает результат расчета, его следует хранить явно и проверять отдельным условием. Если ноль используется как замена отсутствующих данных, корректнее хранить NULL и выполнять фильтрацию с помощью специализированных операторов, сохраняя однозначность логики запросов.
Выборка ненулевых значений в агрегатных функциях SQL

Агрегатные функции в SQL по-разному обрабатывают нулевые значения и NULL, поэтому предварительная фильтрация данных напрямую влияет на итоговые расчеты. Функции SUM и AVG игнорируют NULL, но учитывают нули, что может искажать показатели при анализе объемов, сумм или средних значений. Для исключения нулей требуется явное условие в WHERE или HAVING.
При подсчете строк различие становится критичным. COUNT(column) считает только строки с ненулевым значением столбца, тогда как COUNT(*) учитывает все строки, включая записи с NULL. Если задача состоит в подсчете только строк с заполненными и отличными от нуля данными, фильтрация должна выполняться до агрегации.
| Функция | Поведение с NULL | Поведение с 0 |
|---|---|---|
| SUM | Игнорируется | Учитывается |
| AVG | Игнорируется | Учитывается |
| COUNT(column) | Не учитывается | Учитывается |
| COUNT(*) | Учитывается | Учитывается |
Для получения корректных агрегатов рекомендуется использовать условия вида WHERE column IS NOT NULL AND column <> 0. Это гарантирует, что в вычисления попадут только осмысленные числовые значения, а отсутствие данных не будет маскироваться под допустимый результат.
В группировках с GROUP BY фильтрацию ненулевых значений следует выполнять до агрегации, если требуется исключить строки целиком. Использование HAVING оправдано только тогда, когда необходимо отфильтровать группы по результату агрегатной функции, а не по исходным данным.
Примеры выборки ненулевых значений в SELECT с JOIN
При объединении таблиц фильтрация ненулевых значений требует учета типа соединения. В запросе с INNER JOIN условие WHERE orders.amount > 0 отбирает только те строки, где связанная запись существует и содержит положительное значение. Строки без совпадений автоматически исключаются, что упрощает логику выборки для связанных данных.
В случае использования LEFT JOIN размещение условий критично. Проверка WHERE payments.sum > 0 отбрасывает строки, где в правой таблице нет данных, так как результат соединения содержит NULL. Чтобы сохранить строки из основной таблицы, фильтрацию ненулевых значений следует переносить в условие соединения, например в часть ON payments.sum > 0.
Если требуется получить все строки из основной таблицы и отдельно определить наличие ненулевого значения в связанной таблице, используется комбинированная проверка. Условие вида WHERE payments.sum IS NULL OR payments.sum > 0 позволяет сохранить записи без связанных данных и одновременно исключить нулевые показатели.
При объединении нескольких таблиц важно учитывать, что каждая дополнительная проверка на ненулевое значение может изменить итоговый набор данных. Фильтрацию числовых колонок рекомендуется выполнять на том уровне запроса, где значение имеет бизнес-смысл, а не применять универсальные условия ко всем соединениям подряд.
Для аналитических запросов с расчетами после объединения таблиц логично сначала отобрать строки с заполненными и отличными от нуля значениями, а затем выполнять агрегацию. Такой порядок снижает риск появления строк с искажёнными показателями, возникшими из-за NULL, появившихся в результате соединений.
Особенности работы с ненулевыми значениями в разных СУБД
Наиболее заметные особенности связаны с интерпретацией NULL и числовых типов:
- В PostgreSQL строго разделяются NULL и числовые значения, а попытка сравнения с NULL без IS NULL всегда приводит к неопределенному результату. Это снижает риск скрытых ошибок, но требует явных условий в запросах.
- В MySQL режимы SQL (sql_mode) могут влиять на поведение сравнений и агрегаций. Например, при определенных настройках происходит неявное приведение типов, из-за чего строковые значения могут интерпретироваться как 0.
- В SQL Server функции агрегации и сравнения чувствительны к типам данных. Использование ISNULL вместо стандартного COALESCE может изменить логику фильтрации при работе с ненулевыми значениями.
- В Oracle пустые строки в текстовых колонках трактуются как NULL, что требует осторожности при фильтрации данных, поступающих из пользовательского ввода или внешних источников.
Отдельного внимания требуют числовые типы с плавающей точкой:
- В большинстве СУБД сравнение с 0 для FLOAT и DOUBLE может давать непредсказуемые результаты из-за округлений.
- Для финансовых данных рекомендуется использовать DECIMAL или NUMERIC и выполнять явные проверки на ненулевые значения.
- При миграции запросов между СУБД следует пересматривать условия фильтрации, даже если синтаксис остается допустимым.
Практика показывает, что универсальные запросы без учета особенностей конкретной СУБД чаще всего приводят к расхождениям в результатах. Для стабильной выборки ненулевых значений необходимо учитывать типы данных, системные функции и правила обработки NULL в используемой базе данных.
Вопрос-ответ:
Почему условие WHERE column <> 0 не возвращает строки с NULL и как это влияет на результат запроса?
В SQL любое сравнение с NULL возвращает неопределенное значение, а не истину или ложь. Поэтому строки, где поле содержит NULL, не проходят фильтр с оператором <>. Если такие записи должны участвовать в выборке, требуется явная проверка через IS NULL или логическое объединение условий.
Как корректно выбрать строки, где значение заполнено и больше нуля?
Для этого используется составное условие WHERE column IS NOT NULL AND column > 0. Оно исключает записи с отсутствующими данными и одновременно отбрасывает нулевые и отрицательные значения. Такой подход дает предсказуемый результат при расчетах и агрегации.
Почему COUNT(column) и COUNT(*) дают разные числа при работе с ненулевыми значениями?
COUNT(column) считает только строки, где указанный столбец не равен NULL. COUNT(*) учитывает все строки, независимо от заполненности полей. При анализе ненулевых значений выбор функции определяет, будут ли строки с NULL участвовать в подсчете.
Как фильтрация ненулевых значений влияет на LEFT JOIN?
Если условие на ненулевое значение размещено в WHERE, строки без совпадений в правой таблице отбрасываются, так как после соединения там появляется NULL. Чтобы сохранить строки из основной таблицы, проверку следует переносить в условие ON или комбинировать с IS NULL.
Можно ли использовать COALESCE для отбора ненулевых значений?
COALESCE подставляет значение вместо NULL, что стирает различие между отсутствием данных и реальным нулем. Это допустимо в отдельных сценариях, но при анализе и отчетности чаще приводит к искажению логики. Фильтрацию лучше выполнять до подстановки значений.