Кодировка UTF-8 используется для корректного хранения и отображения текста на разных устройствах и в разных операционных системах. Она поддерживает кириллицу, латиницу, иероглифы, специальные символы и знаки валют без искажений. Если файл сохранён в другой кодировке, пользователь может столкнуться с «кракозябрами», ошибками при импорте данных или некорректной работой программ.
Чаще всего проблемы возникают при работе с текстовыми файлами, CSV-документами, исходным кодом сайтов и конфигурационными файлами. Например, веб-сервер может неправильно обработать страницу, а база данных – сохранить текст с повреждёнными символами. Поэтому важно не только выбрать UTF-8, но и убедиться, что файл сохранён без скрытых меток и лишних преобразований.
Разные редакторы используют собственные интерфейсы для выбора кодировки. В одних случаях параметр задаётся при сохранении файла, в других – через меню преобразования или строку состояния. Ошибка на этом этапе приводит к тому, что файл выглядит нормально на одном компьютере, но ломается при передаче или публикации.
В этой статье разобраны конкретные действия для популярных текстовых редакторов и офисных программ, а также способы проверки кодировки после сохранения. Отдельное внимание уделено типовым ситуациям, когда файл уже создан, но его требуется привести к UTF-8 без потери данных.
Как выбрать кодировку UTF-8 при сохранении файла в Блокноте Windows
В стандартном Блокноте Windows кодировка задаётся только в момент сохранения файла. После ввода или вставки текста нажмите «Файл» → «Сохранить как». В открывшемся окне в нижней части расположен выпадающий список «Кодировка», который по умолчанию может быть установлен в значение ANSI.
Из списка необходимо выбрать вариант UTF-8. В версиях Windows 10 и Windows 11 также доступен пункт «UTF-8 с сигнатурой». Для веб-страниц, скриптов и файлов конфигурации рекомендуется выбирать именно «UTF-8», а не вариант с сигнатурой, так как скрытая метка BOM может вызвать ошибки при обработке файла сторонними программами.
Перед нажатием кнопки «Сохранить» проверьте поле «Тип файла». Если оставить значение «Текстовые документы (*.txt)», Блокнот автоматически добавит расширение .txt. Для файлов .csv, .json, .html или .php следует выбрать «Все файлы» и указать расширение вручную, заключив имя файла в кавычки.
Если файл уже был сохранён ранее в другой кодировке, простое повторное сохранение не изменит формат. В этом случае файл нужно открыть, выбрать «Сохранить как», задать кодировку UTF-8 и сохранить под новым именем, после чего заменить старый файл. Такой порядок позволяет сохранить все символы без искажений.
Как сохранить текстовый файл в UTF-8 в Notepad++
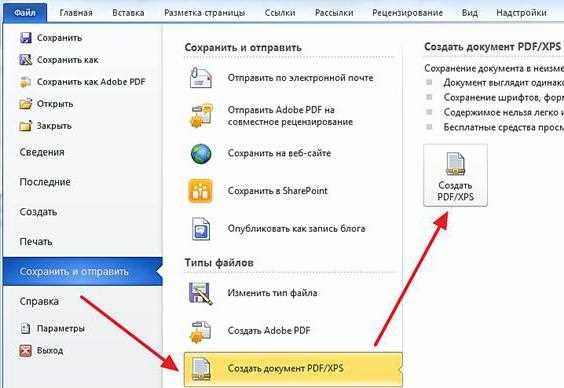
Notepad++ позволяет управлять кодировкой как для новых, так и для уже существующих файлов. Текущая кодировка отображается в строке состояния в правом нижнем углу окна. Если там указано ANSI или другая кодировка, файл необходимо преобразовать перед сохранением.
Для изменения кодировки откройте меню «Кодировки» и выберите пункт Преобразовать в UTF-8 без BOM. Именно этот вариант подходит для текстовых файлов, исходного кода и данных, предназначенных для обработки сторонними программами. Пункт «Кодировать в UTF-8» использовать не следует, так как он не меняет байтовое представление уже открытого файла.
После преобразования сохраните файл сочетанием клавиш Ctrl+S или через меню «Файл». Notepad++ зафиксирует кодировку UTF-8, и при повторном открытии она будет отображаться в строке состояния без дополнительных действий.
Для новых файлов рекомендуется заранее задать кодировку по умолчанию. Откройте «Настройки» → «Параметры» → вкладка «Новые документы» и установите значение «UTF-8 без BOM». Это исключает ситуацию, когда текст создаётся в ANSI и требует ручного преобразования.
Перед передачей файла другому пользователю или загрузкой на сервер полезно повторно проверить кодировку через меню «Кодировки». Это позволяет убедиться, что файл сохранён именно в UTF-8, а не отображается корректно лишь внутри редактора.
Как задать UTF-8 при сохранении файла в Microsoft Word

В окне сохранения необходимо:
- выбрать тип файла «Обычный текст (*.txt)»;
- указать имя файла и место сохранения;
- нажать кнопку «Сохранить».
После этого Word откроет дополнительное окно «Преобразование файла». В нём задаётся кодировка будущего файла. В списке доступных вариантов нужно выбрать UTF-8, а не системную или региональную кодировку.
При экспорте текста следует учитывать особенности форматирования:
- все стили, шрифты и цвета будут удалены;
- переносы строк сохраняются как стандартные символы конца строки;
- таблицы преобразуются в текст с разделителями.
Если файл предназначен для загрузки в систему учёта, базу данных или веб-приложение, рекомендуется сразу проверить его в текстовом редакторе. Это позволяет убедиться, что кириллица и специальные символы сохранены корректно и кодировка действительно соответствует UTF-8.
Как сохранить файл в UTF-8 в редакторах VS Code и Sublime Text

Оба редактора по умолчанию ориентированы на UTF-8, однако при работе с файлами из внешних источников кодировка может отличаться. Перед сохранением важно проверить текущий формат, чтобы избежать искажений текста после передачи или публикации.
В Visual Studio Code текущая кодировка отображается в правой части строки состояния. При нажатии на неё открывается меню управления кодировками, где можно выбрать преобразование файла.
В Sublime Text информация о кодировке также доступна в строке состояния. Изменение выполняется через главное меню без открытия дополнительных окон сохранения.
| Редактор | Действие для сохранения в UTF-8 |
| VS Code | Нажать на кодировку в строке состояния → «Save with Encoding» → «UTF-8» |
| Sublime Text | Меню «File» → «Save with Encoding» → «UTF-8» |
Для файлов исходного кода и конфигураций следует использовать UTF-8 без BOM. В VS Code reminder о BOM отображается отдельно, что позволяет сразу определить наличие скрытой сигнатуры. В Sublime Text вариант с BOM выделяется отдельным пунктом, и его выбирать не требуется.
Чтобы исключить ошибки при создании новых файлов, рекомендуется установить UTF-8 как кодировку по умолчанию в настройках редактора. Это гарантирует, что весь новый контент будет сохранён в нужном формате без дополнительных действий.
Как проверить, что файл действительно сохранён в кодировке UTF-8
Самый быстрый способ проверки – открыть файл в текстовом редакторе с поддержкой отображения кодировки. В Notepad++ и VS Code информация о формате отображается в строке состояния. Если указано «UTF-8» или «UTF-8 without BOM», файл сохранён корректно и не содержит системных ограничений.
Дополнительную проверку можно выполнить путём повторного открытия файла в другом редакторе или на другом компьютере. Если кириллица, спецсимволы и знаки пунктуации отображаются одинаково, это подтверждает, что текст хранится в универсальном формате.
Для файлов данных полезно использовать просмотр в браузере. Откройте HTML-, JSON- или CSV-файл напрямую через Chrome или Firefox. При корректной кодировке текст отобразится без искажений, а консоль разработчика не покажет ошибок, связанных с символами.
Если есть доступ к командной строке, файл можно проверить системными утилитами. В Linux и macOS команда file показывает предполагаемую кодировку. В Windows PowerShell можно использовать командлеты для чтения содержимого с указанием формата, чтобы выявить несовпадения.
При сомнениях в результате стоит выполнить преобразование файла в UTF-8 заново через редактор с явным выбором кодировки. Это позволяет устранить скрытые ошибки, которые не проявляются при обычном просмотре, но вызывают проблемы при импорте или обработке.
Какие ошибки возникают при неправильной кодировке и как их исправить
Самая распространённая проблема – появление нечитаемых символов вместо букв. Такое происходит, когда файл сохранён в ANSI или другой локальной кодировке, а программа пытается интерпретировать его как UTF-8. Исправление выполняется путём открытия файла в редакторе с поддержкой преобразования и выбора пункта преобразовать в UTF-8, а не простого изменения отображения.
Отдельный тип ошибок связан с наличием BOM. Некоторые интерпретаторы, библиотеки и системы импорта воспринимают скрытую сигнатуру как часть данных. В результате возникают сбои при чтении CSV, ошибки парсинга JSON или некорректная обработка заголовков. Решение – сохранить файл в формате UTF-8 без BOM и заново загрузить его в систему.
При работе с веб-страницами неправильная кодировка приводит к искажению текста в браузере, даже если файл сохранён в UTF-8. Причина часто кроется в отсутствии или несоответствии мета-описания кодировки. Файл необходимо пересохранить и убедиться, что используемая кодировка совпадает с той, которую ожидает среда выполнения.
В базах данных и системах учёта ошибки кодировки проявляются при импорте: строки обрываются, символы заменяются вопросительными знаками, данные теряют смысл. В таких случаях файл следует сначала открыть в текстовом редакторе, проверить кодировку, затем сохранить в UTF-8 и только после этого повторить загрузку.
Если текст уже повреждён, простое пересохранение не восстановит символы. Необходимо определить исходную кодировку, открыть файл с её указанием и только затем выполнить преобразование в UTF-8. Такой подход позволяет сохранить исходные данные без ручного редактирования.
Вопрос-ответ:
Почему файл с кириллицей выглядит нормально в одном редакторе, но ломается при открытии в другом?
Чаще всего это связано с тем, что файл сохранён в локальной кодировке, а второй редактор пытается прочитать его как UTF-8. Первый редактор автоматически подставляет системные настройки и показывает текст без искажений, но при передаче файла эти подсказки теряются. Решение — открыть файл в редакторе с явным выбором кодировки и преобразовать его в UTF-8, после чего сохранить заново.
Чем отличается UTF-8 от UTF-8 с BOM и какой вариант выбирать?
UTF-8 с BOM содержит скрытую сигнатуру в начале файла, которая указывает на используемую кодировку. Некоторые программы игнорируют её, а другие воспринимают как часть данных, из-за чего возникают ошибки. Для сайтов, скриптов, CSV и файлов конфигурации подходит UTF-8 без BOM. Вариант с BOM допустим для офисных документов и некоторых редакторов, где эта метка не мешает обработке.
Можно ли сохранить файл в UTF-8, если он уже создан в другой кодировке?
Да, но нужно выполнять именно преобразование, а не смену отображения. Файл следует открыть в редакторе, который умеет работать с кодировками, указать текущий формат, затем выбрать преобразование в UTF-8 и сохранить результат. Такой порядок сохраняет все символы без подмены и потерь.
Почему после сохранения CSV в UTF-8 Excel всё равно показывает искажённый текст?
Excel часто открывает CSV, ориентируясь на региональные параметры, а не на фактическую кодировку файла. Даже если файл сохранён в UTF-8, программа может интерпретировать его иначе. Для корректного отображения нужно импортировать файл через мастер данных с ручным выбором UTF-8 либо открыть CSV в текстовом редакторе и проверить кодировку перед загрузкой.
Как убедиться, что сервер или приложение принимает файл именно в UTF-8?
После загрузки файла следует проверить результат обработки: корректность отображения кириллицы, отсутствие ошибок парсинга и предупреждений. Полезно открыть файл напрямую на сервере или выгрузить его обратно и сравнить содержимое. Если текст совпадает и не содержит заменённых символов, значит формат принят правильно.