Cuneiform – это программа оптического распознавания символов (OCR), предназначенная для перевода изображений с текстом в редактируемый цифровой формат. Она работает со сканами бумажных документов, фотографиями страниц, а также файлами PDF, полученными без текстового слоя. Основная задача Cuneiform – извлечь буквенно-цифровые данные из графики и сохранить их в виде обычного текста, пригодного для правки, поиска и архивирования.
Программа ориентирована на практическое использование в ситуациях, где требуется обработка большого объёма бумажных материалов: договоров, инструкций, отчетов, учебных пособий. Cuneiform поддерживает распознавание многостраничных документов, учитывает структуру страницы и различает текстовые блоки, таблицы и изображения. Для повышения точности рекомендуется использовать сканы с разрешением не ниже 300 dpi и предварительно выравнивать перекошенные страницы.
Отдельного внимания заслуживает языковая поддержка. Cuneiform позволяет работать с кириллицей и латиницей, включая русский, английский, немецкий и французский языки, а также комбинировать их в одном документе. Это удобно при обработке технической документации и деловой переписки. Перед запуском распознавания важно явно указать нужные языки – это снижает количество ошибок в результатах.
Программа подходит пользователям, которым требуется локальное решение без привязки к облачным сервисам. Cuneiform устанавливается на компьютер и обрабатывает данные автономно, что актуально при работе с конфиденциальными материалами. Для получения корректного результата рекомендуется проверять итоговый текст вручную, особенно в местах с нестандартными шрифтами, печатями и помехами на изображении.
Какие задачи распознавания текста решает Cuneiform

Cuneiform предназначена для преобразования печатного текста с бумажных носителей в цифровой вид с сохранением логики расположения блоков на странице. Программа распознаёт абзацы, заголовки, колонки и простые таблицы, что позволяет получить результат, пригодный для дальнейшего редактирования в текстовых редакторах. Наиболее стабильные результаты достигаются при работе с документами, набранными стандартными шрифтами без декоративных искажений.
Одной из ключевых задач является обработка сканированных архивов: договоров, счетов, методических материалов, технических описаний. Cuneiform умеет извлекать текст из многостраничных PDF-файлов без текстового слоя, объединяя результат в единый документ. Для снижения количества ошибок рекомендуется заранее удалить фоновые элементы и привести изображение к чёрно-белому или оттенкам серого.
Программа решает задачу распознавания документов с несколькими языками в пределах одной страницы. Пользователь может задать комбинацию языков, например русский и английский, что актуально для инструкций, спецификаций и деловой переписки. При работе с цифрами и кодами стоит отключать лишние языки, чтобы избежать подмены символов.
Cuneiform также применяется для переноса текстового содержимого из растровых изображений, полученных с фотоаппарата или мобильного телефона. В таких случаях важно корректно выровнять перспективу и повысить контраст до запуска распознавания. Программа справляется с задачами извлечения текста из чеков, бланков и форм, если поля не перекрыты штампами и рукописными пометками.
Отдельная область применения – подготовка материалов для поиска и индексирования. После распознавания текст становится доступным для копирования, полнотекстового поиска и анализа. Это позволяет использовать Cuneiform при оцифровке библиотек, учебных архивов и внутренней документации организаций.
С какими форматами изображений и документов работает Cuneiform
Cuneiform принимает на вход как отдельные графические файлы, так и составные документы, созданные в процессе сканирования. Программа ориентирована на работу с растровыми изображениями, где текст представлен в виде пикселей, а не встроенного текстового слоя. Перед загрузкой файлов важно убедиться, что изображение не содержит сильного сжатия и артефактов.
Поддерживаемые форматы изображений включают наиболее распространённые типы файлов, используемые сканерами и камерами:
- TIFF – предпочтителен для архивной обработки и многостраничных документов
- JPEG – подходит для фотографий страниц при высоком качестве съёмки
- BMP – используется для необработанных сканов без потери данных
- PNG – сохраняет чёткие контуры текста и минимальный уровень шума
Для документов Cuneiform работает с файлами PDF, в которых отсутствует текстовый слой. Такие файлы часто формируются офисными МФУ и требуют предварительного распознавания. При импорте PDF рекомендуется отключать автоматическое масштабирование страниц, чтобы сохранить исходное разрешение.
Программа поддерживает загрузку многостраничных файлов, что упрощает обработку книг, отчетов и договоров. Страницы можно упорядочивать, удалять и заменять до запуска распознавания. Это особенно полезно при работе с документами, где часть страниц содержит иллюстрации или пустые листы.
После обработки Cuneiform позволяет сохранять результат в нескольких выходных форматах, ориентированных на дальнейшую работу:
- TXT – для хранения чистого текста без оформления
- RTF – для редактирования с сохранением базовой структуры
- DOC – для работы в текстовых редакторах
- HTML – для публикации и последующей верстки
Выбор исходного и выходного формата напрямую влияет на качество результата, поэтому при регулярной работе рекомендуется использовать единый стандарт сканирования и сохранения файлов.
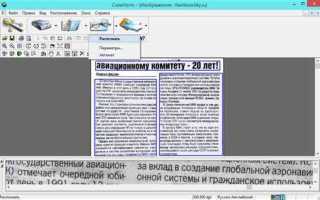
Как происходит преобразование сканов в редактируемый текст
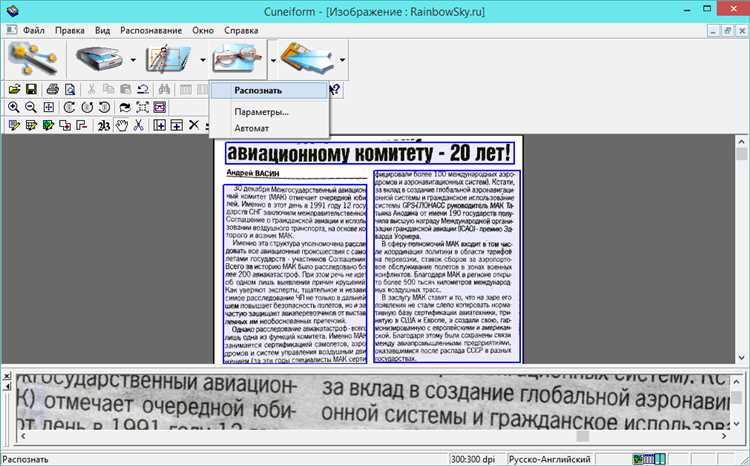
Процесс начинается с загрузки сканированных страниц или изображений в рабочую область Cuneiform. На этом этапе важно проверить разрешение: для стандартных документов рекомендуется не менее 300 dpi, для мелкого шрифта – выше. Программа анализирует геометрию страницы, определяет границы полей и выравнивает изображение, если скан выполнен с перекосом.
Далее выполняется сегментация: Cuneiform разделяет страницу на текстовые блоки, графику и таблицы. Этот шаг критичен при работе с многострочными колонками и формами. Пользователь может вручную скорректировать зоны распознавания, исключив логотипы, подписи и декоративные элементы, которые не требуется переводить в текст.
После разметки запускается распознавание символов. Программа сопоставляет фрагменты изображения с внутренними моделями шрифтов и языков. Для повышения точности следует заранее указать конкретные языки документа и отключить лишние. При наличии цифр, артикулов и кодов полезно активировать режим распознавания числовых последовательностей.
На следующем этапе формируется структура выходного документа. Cuneiform восстанавливает абзацы, переносы строк и базовое форматирование. Таблицы преобразуются в упорядоченные блоки текста, пригодные для последующей ручной правки. Важно проверить места с нестандартными шрифтами и плотной версткой – именно там чаще всего появляются ошибки.
Завершающий шаг – сохранение результата в выбранном формате. Перед экспортом рекомендуется выполнить визуальную проверку и исправить замену похожих символов, таких как «О» и «0» или «l» и «1». Такой подход позволяет получить текст, готовый для редактирования, поиска и дальнейшего использования без повторного распознавания.
Какие языки поддерживает Cuneiform и как выбрать нужный

Cuneiform поддерживает распознавание текстов на нескольких десятках языков, включая русский, украинский, английский, немецкий, французский, испанский и итальянский. Отдельное внимание уделено кириллическим и латинским алфавитам, что позволяет работать с деловой документацией, техническими инструкциями и учебными материалами без переключения между разными программами.
Программа допускает одновременное использование нескольких языков в одном проекте. Это актуально для документов, где основной текст написан на русском языке, а термины, названия моделей или фрагменты интерфейсов приведены на английском. При этом важно учитывать, что увеличение количества активных языков повышает риск подмены похожих символов.
Выбор языков выполняется до запуска распознавания в настройках проекта. Рекомендуется отмечать только те языки, которые реально присутствуют в документе. Например, при обработке финансовых отчётов или актов стоит оставить один язык и отключить остальные, чтобы избежать ошибок в цифрах и сокращениях.
Для текстов с преобладанием числовых данных, кодов и артикулов полезно использовать режимы, ориентированные на распознавание символов без лингвистического анализа. Это снижает вероятность замены цифр буквами и упрощает последующую проверку результата.
При работе с редкими языками или нестандартными шрифтами рекомендуется выполнять пробное распознавание одной страницы. Такой подход позволяет заранее оценить качество результата и скорректировать набор языков до обработки всего документа.
В каких сценариях Cuneiform применяют дома и в офисе
В домашних условиях Cuneiform используют для перевода бумажных материалов в цифровой архив. Это учебные конспекты, книги, инструкции к технике, квитанции и личные документы. Программа позволяет быстро получить текст для цитирования, поиска нужных фрагментов и хранения без необходимости держать оригиналы под рукой. Для бытовых задач обычно достаточно сканера с разрешением 300 dpi и базовых настроек распознавания.
В офисе Cuneiform применяется при обработке входящего документооборота: договоров, актов, заявлений, отчетов. Распознанные файлы удобно включать в электронные архивы и системы поиска. Программа подходит для ситуаций, когда документы поступают в виде сканов или PDF без текстового слоя и требуют последующего редактирования или анализа.
Типовые сценарии использования различаются по целям и формату документов:
| Среда | Задачи | Рекомендации по использованию |
| Дом | Оцифровка книг, учебных материалов, личных архивов | Использовать TIFF или PNG, проверять текст вручную после распознавания |
| Малый офис | Работа с договорами, счетами, письмами | Ограничивать языки, сохранять результат в DOC или RTF |
| Корпоративная среда | Архивация отчетов и нормативной документации | Применять единые параметры сканирования и именования файлов |
Cuneiform также используют при подготовке материалов для повторного использования: переносе старых инструкций в актуальные шаблоны, обновлении документации и создании поисковых баз. В таких сценариях важно заранее очистить изображения от печатей и пометок, чтобы снизить количество ручных исправлений.
Программа подходит для задач, где требуется автономная обработка данных без передачи файлов в облачные сервисы. Это делает её востребованной при работе с внутренними документами компаний и персональными материалами, доступ к которым должен оставаться локальным.
Какие ограничения и типичные ошибки возникают при работе с Cuneiform
Ошибки часто возникают при распознавании нестандартных шрифтов, декоративных заголовков и мелкого текста. Cuneiform ориентирована на печатные гарнитуры без сложных начертаний, поэтому элементы вроде капители или узких шрифтов могут распознаваться с подменой букв. В таких случаях рекомендуется исключать проблемные зоны из автоматической обработки и править их вручную.
Отдельное ограничение связано с таблицами и формами сложной структуры. Программа корректно выделяет простые таблицы, но при наличии объединённых ячеек и плотной верстки возможен сдвиг данных. Чтобы избежать потери логики, лучше сохранять такие фрагменты как текстовые блоки и восстанавливать структуру уже после распознавания.
Частой причиной ошибок становится неправильный выбор языков. Активирование нескольких алфавитов без необходимости приводит к замене похожих символов, например «Р» и «P» или «С» и «C». Для документов с цифрами и кодами важно минимизировать список языков и отключать словарную коррекцию.
Cuneiform не предназначена для распознавания рукописного текста и документов с сильными повреждениями бумаги. Попытки обработки таких материалов приводят к большому объёму ручной правки. При работе с архивами рекомендуется заранее сортировать документы по качеству и типу, чтобы не тратить время на заведомо проблемные источники.
Вопрос-ответ:
Можно ли использовать Cuneiform для распознавания старых бумажных документов из архива?
Да, Cuneiform подходит для оцифровки архивных материалов, если они напечатаны машинным или типографским способом. Перед распознаванием желательно отсканировать страницы с разрешением не ниже 300 dpi, убрать пыль и затемнения, а также выровнять перекошенные листы. Документы с пожелтевшей бумагой и блеклым текстом часто требуют предварительной обработки изображения в графическом редакторе.
Подходит ли Cuneiform для распознавания PDF-файлов, полученных со сканера?
Программа работает с PDF без текстового слоя, которые создаются МФУ и сканерами. Такие файлы можно загружать целиком, включая многостраничные документы. Для получения корректного результата лучше сохранять исходное разрешение страниц и не использовать автоматическое сжатие при сканировании.
Насколько корректно Cuneiform распознаёт таблицы и формы?
Cuneiform справляется с простыми таблицами, где ячейки имеют чёткие границы и одинаковую структуру. В формах с объединёнными полями и плотной версткой возможны смещения текста. В таких случаях практичнее распознавать документ как обычный текст и восстанавливать структуру вручную в редакторе.
Можно ли обрабатывать документы с русским и английским текстом одновременно?
Да, программа позволяет выбрать несколько языков для одного проекта. Это удобно для инструкций, договоров и технических описаний. Чтобы снизить количество ошибок, рекомендуется отключать языки, которые точно не используются, особенно при наличии большого количества цифр и аббревиатур.
Подходит ли Cuneiform для распознавания фотографий документов со смартфона?
Работа с фотографиями возможна, если изображение чёткое, без сильных искажений и бликов. Перед загрузкой стоит выровнять перспективу, повысить контраст и удалить фоновые тени. Фото с размытым текстом и низким разрешением приводят к большому числу исправлений после распознавания.