Содержание статьи

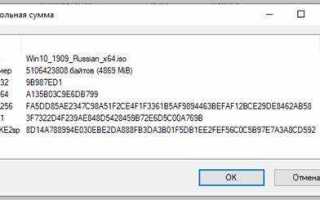
Контрольная сумма на процессоре м86 вычисляется напрямую через регистры и команды процессора, что позволяет проверять целостность данных без дополнительных библиотек. Наиболее распространённый подход использует алгоритм сложения байт с учётом переносов в 16- или 32-битных регистрах.
Для расчёта контрольной суммы важно заранее выбрать подходящий регистр: AX удобен для 16-битных блоков, а EAX – для 32-битных. Чтение данных следует организовать последовательными блоками по размеру регистра, чтобы минимизировать количество обращений к памяти и исключить пропуски или повторное считывание.
При суммировании необходимо учитывать перенос через флаг CF процессора. Игнорирование этого шага приведёт к неверной контрольной сумме при обработке больших объёмов данных. Для проверки корректности можно использовать эталонные массивы с заранее известными суммами.
Выбор алгоритма и правильная настройка регистров на процессоре м86 позволяют получить контрольную сумму за минимальное число тактов, что особенно важно при обработке потоковых данных или встроенных систем с ограниченными ресурсами.
Выбор алгоритма контрольной суммы для x86
На процессоре x86 чаще всего применяют простое сложение байт с учётом переноса (add с флагом CF) или алгоритм CRC-16/CRC-32 для более высокой надёжности. Суммирование байт подходит для небольших массивов до 64 КБ, где важно быстрое выполнение и минимальная нагрузка на кэш.
Алгоритм CRC-32 предпочтителен при проверке больших объёмов данных, так как он обнаруживает одиночные и множественные ошибки в блоках до 4 ГБ. Для x86 можно реализовать CRC с использованием инструкций SHL, SHR, XOR и предвычисленной таблицы на 256 элементов для ускорения вычислений.
При выборе алгоритма следует учитывать разрядность процессора: для 16-битных регистров лучше использовать CRC-16 или простую сумму слов по 2 байта, для 32-битных регистров – CRC-32 с обработкой DWORD-блоков. Это сокращает количество команд и уменьшает количество обращений к памяти.
Встроенные инструкции процессоров современных серий, включая SSE4.2, поддерживают прямой расчёт CRC32 через инструкцию crc32, что значительно ускоряет вычисления и уменьшает вероятность ошибок при ручной реализации.
Настройка регистров и сегментов для расчёта
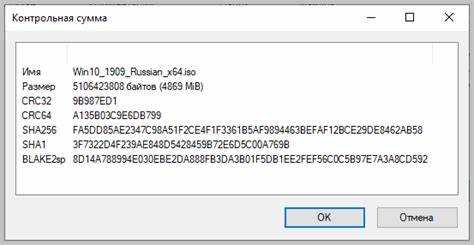
Для вычисления контрольной суммы на м86 необходимо корректно инициализировать регистры и сегменты. Суммирование байт или слов удобно выполнять через регистры AX, BX, CX и DX, при этом использование EAX, EBX, ECX и EDX ускоряет обработку 32-битных блоков. Регистры SI и DI применяются для адресации исходного и результирующего массивов, а регистра BP – для хранения смещений внутри стека.
Сегменты данных должны быть настроены на прямой доступ к массивам. Чаще всего используется сегмент DS для чтения исходных данных и ES для записи результата. Правильная установка сегментных регистров предотвращает ошибки при обработке больших блоков памяти.
| Регистры | Назначение | Примечание |
|---|---|---|
| AX / EAX | Суммирование блоков данных | 16/32-битные операции |
| BX / EBX | Буфер промежуточной суммы | Сохраняет результат между итерациями |
| SI / ESI | Адрес исходного массива | Инкремент для последовательного чтения |
| DI / EDI | Адрес результирующего массива | Используется для записи или проверки контрольной суммы |
| BP / EBP | Смещения и работа со стеком | Обеспечивает доступ к локальным переменным |
| DS / ES | Сегменты данных | DS для чтения, ES для записи |
Перед началом расчёта необходимо загрузить адрес массива в SI и инициализировать AX нулём. После каждой операции сложения проверять флаг CF для учёта переполнения. Такая настройка регистров и сегментов гарантирует корректное суммирование и минимизирует ошибки доступа к памяти.
Оптимизация чтения памяти при обработке данных
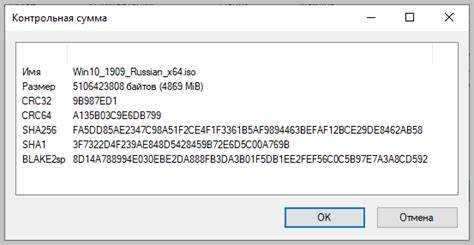
При вычислении контрольной суммы на м86 скорость чтения памяти напрямую влияет на производительность. Чтение данных блоками по размеру регистра уменьшает количество инструкций и обращений к памяти. Для 16-битных регистров AX или BX оптимально обрабатывать слова по 2 байта, для 32-битных EAX или EBX – DWORD-блоки по 4 байта.
Использование указателей SI и DI с постинкрементом позволяет последовательно считывать массив без лишних операций. Прямой доступ через сегмент DS ускоряет обработку, избегая дополнительных инструкций для вычисления адреса. При работе с большими массивами целесообразно выравнивать данные по границе 4 или 8 байт, чтобы уменьшить количество циклов и кеш-промахов.
Рекомендуется минимизировать использование стековых операций внутри цикла суммирования, заменяя PUSH/POP на регистры общего назначения. Для массивов свыше 64 КБ стоит использовать циклы с предзагрузкой данных в регистры, чтобы перекрыть задержки памяти и сократить влияние времени доступа к оперативной памяти.
При последовательной обработке блоков данных проверка конца массива должна выполняться один раз перед циклом, чтобы не добавлять лишние условные переходы внутри основного цикла суммирования.
Использование команд процессора для суммирования байт
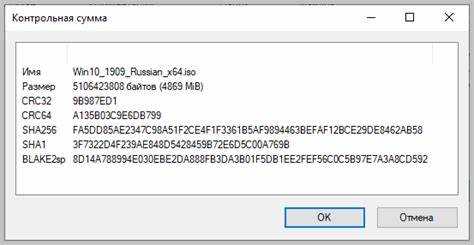
На процессоре м86 суммирование байт выполняется через инструкции ADD и ADC. Инструкция ADD складывает два операнда и обновляет флаги процессора. Для учёта переноса используется ADC, которая добавляет к результату значение флага CF.
- Инициализация регистра суммы: MOV AX, 0 или MOV EAX, 0 для 32-битных операций.
- Чтение байта из памяти: MOV AL, [SI] или MOV AX, [SI] для слова.
- Сложение с аккумулятором: ADD AX, AL для 16-бит, ADD EAX, [ESI] для 32-бит.
- Учёт переноса: ADC AX, 0 после каждой итерации или при переходе на следующий блок.
- Инкремент указателя: INC SI или ADD SI, 2/4 в зависимости от размера блока.
Для массивов с большим объёмом данных целесообразно применять циклы с предзагрузкой нескольких байт в регистры, чтобы сократить количество обращений к памяти. Использование LODSB/LODSW ускоряет последовательное чтение, а STOSB/STOSW может применяться для записи промежуточных сумм.
- Инициализация аккумулятора и указателей.
- Загрузка блока данных в регистр.
- Сложение через ADD.
- Обработка переноса через ADC.
- Повторение до конца массива.
Обработка переполнения и переносов в сумме
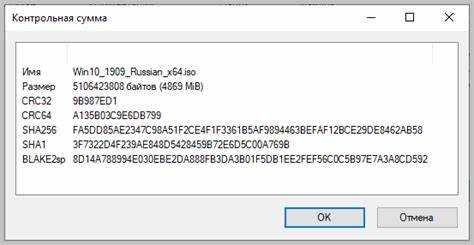
На процессоре м86 флаг CF указывает на перенос при сложении, что критично для правильного вычисления контрольной суммы. Если игнорировать перенос, сумма больших массивов данных окажется неверной.
Для 16-битных сумм регистр AX используется как аккумулятор. После сложения байта или слова с AX необходимо проверять CF и добавлять его к следующей итерации через команду ADC. Для 32-битных сумм аналогично используется EAX и ADC с учётом CF.
Рекомендуется последовательность действий:
- Инициализация аккумулятора: MOV AX, 0 или MOV EAX, 0.
- Сложение текущего блока данных: ADD AX, [SI].
- Добавление переноса с предыдущего сложения: ADC AX, 0.
- Инкремент указателя для следующего блока: INC SI или ADD SI, 2/4.
- Повторение до конца массива.
Для больших массивов полезно группировать сложение по 4 или 8 блоков с промежуточной обработкой CF, чтобы уменьшить количество инструкций ADC и ускорить вычисления.
Сравнение результата с эталонной контрольной суммой
После вычисления контрольной суммы на процессоре м86 результат хранится в регистре AX для 16-битных операций или EAX для 32-битных. Для проверки корректности необходимо сравнить его с эталонным значением.
Сравнение выполняется через инструкцию CMP с последующим условным переходом, например JE или JNE. Если результат совпадает, данные считаются целостными, иначе – зафиксировать ошибку.
Рекомендуется хранить эталонные суммы в статическом сегменте памяти для быстрого доступа. Для массивов, проверяемых многократно, полезно использовать отдельный регистр для промежуточного хранения эталона и избегать лишнего обращения к памяти.
Для автоматизации проверки больших массивов можно реализовать цикл, который сравнивает по 16 или 32 бита за итерацию. Такой подход снижает количество команд CMP и ускоряет обработку, особенно при потоковой передаче данных.
Вопрос-ответ:
Почему при суммировании больших массивов байт на м86 контрольная сумма часто неверная?
Неверный результат обычно связан с игнорированием переноса между сложениями. На процессоре м86 флаг CF указывает на перенос, который необходимо учитывать с помощью инструкции ADC. Если суммирование выполняется только через ADD без учёта CF, при переполнении регистра часть суммы теряется, и итоговая контрольная сумма не совпадает с эталонной.
Как выбрать регистр для хранения промежуточной суммы при работе с разными размерами данных?
Для 16-битных массивов лучше использовать AX, так как он позволяет сложить слова по 2 байта и контролировать перенос через CF. Для 32-битных блоков следует использовать EAX, что сокращает количество итераций цикла. BX или EBX можно применять для хранения промежуточных значений при суммировании нескольких блоков, а SI/ESI и DI/EDI — для адресации исходного и результирующего массива.
Можно ли ускорить вычисление контрольной суммы при обработке больших массивов данных?
Да, ускорение достигается за счёт последовательного чтения блоков данных размером регистра и предзагрузки их в регистры перед суммированием. Использование инструкций LODSB/LODSW или LODSD позволяет обойтись без лишних операций с адресами. Также полезно выравнивать данные по границам 4 или 8 байт, чтобы уменьшить количество обращений к памяти и кеш-промахов.
Как проверить правильность контрольной суммы после её вычисления на м86?
Результат суммы хранится в регистре AX для 16-бит или EAX для 32-бит. Для проверки используется инструкция CMP с эталонным значением, после чего условная команда JE или JNE фиксирует совпадение или расхождение. Для больших массивов можно сравнивать по нескольку байт одновременно, чтобы сократить количество операций сравнения.
Стоит ли использовать CRC вместо простой суммы байт на процессоре м86?
Выбор зависит от целей проверки данных. Простое суммирование байт подходит для небольших массивов и случаев, когда важна скорость. CRC-16 или CRC-32 обеспечивает обнаружение одиночных и множественных ошибок в больших объёмах данных, но требует больше инструкций и памяти для предвычисленной таблицы. На процессорах с поддержкой инструкции CRC32 можно ускорить вычисления, используя её напрямую.
Как правильно использовать флаг переноса при вычислении контрольной суммы на м86?
Флаг переноса CF на процессоре м86 указывает на переполнение при сложении двух чисел. Чтобы сумма оставалась корректной при обработке больших массивов, после каждой операции ADD необходимо использовать команду ADC для добавления переноса к следующему сложению. Это особенно важно при суммировании 16-битных и 32-битных блоков, иначе итоговая контрольная сумма будет неверной. Пример последовательности: инициализация AX или EAX нулём, чтение блока из памяти, сложение через ADD, добавление переноса через ADC и переход к следующему блоку.
Какие приёмы ускоряют суммирование байт при больших объёмах данных на м86?
Ускорение достигается за счёт последовательного чтения блоков данных размером регистра и предзагрузки их в регистры перед суммированием. Для 16-битных блоков используют AX и слова по 2 байта, для 32-битных — EAX и DWORD по 4 байта. Инструкции LODSB, LODSW или LODSD позволяют загружать данные без лишних операций с адресами. Дополнительно выравнивание массивов по границе 4 или 8 байт сокращает количество обращений к памяти и уменьшает задержки. Для массивов свыше 64 КБ можно обрабатывать несколько блоков за одну итерацию с промежуточной обработкой CF, чтобы уменьшить количество циклов и операций ADC.