Создание базы данных начинается не с написания SQL-команд, а с понимания того, какие данные будут храниться, в каком объёме и для каких операций. Например, база для интернет-магазина требует раздельного хранения товаров, заказов, пользователей и платежей, тогда как учёт складских остатков может ограничиться несколькими связанными таблицами. Ошибки на этом этапе приводят к дублированию данных, сложным запросам и проблемам с обновлением информации.
При разработке базы данных важно заранее определить тип СУБД: реляционная (MySQL, PostgreSQL) подойдёт для структурированных данных и строгих связей, а документная (MongoDB) – для гибких схем и часто меняющейся структуры. Выбор напрямую влияет на синтаксис запросов, способы хранения данных и правила проектирования таблиц или коллекций.
Практическая работа с базой данных включает проектирование таблиц, настройку первичных и внешних ключей, определение ограничений целостности и подготовку тестовых данных. Например, поле email в таблице пользователей должно иметь уникальное ограничение, а числовые значения – заданный диапазон. Такие детали определяют стабильность работы базы при реальной нагрузке.
В этой статье процесс создания базы данных разобран пошагово: от постановки задачи и построения структуры до выполнения запросов и проверки корректности данных. Каждый шаг сопровождается примерами, которые можно адаптировать под учебный проект, корпоративную систему или личное приложение.
Как создать базу данных с нуля: шаги и примеры
Работа над базой данных начинается с фиксации конкретной задачи. Нужно определить, какие сущности будут храниться и как они связаны. Для системы учёта заказов это пользователи, товары, заказы и позиции заказов. Каждая сущность в дальнейшем станет отдельной таблицей с чётко заданным назначением.
После определения сущностей формируется перечень полей для каждой таблицы. Для пользователя это идентификатор, имя, адрес электронной почты, дата регистрации. Для заказа – номер, дата создания, статус, ссылка на пользователя. На этом этапе важно задать типы данных и допустимые значения, чтобы исключить некорректный ввод.
- Определить основную цель базы данных и сценарии использования.
- Выделить сущности и преобразовать их в таблицы.
- Задать поля, типы данных и обязательность заполнения.
- Назначить первичные ключи для каждой таблицы.
- Создать внешние ключи для связи данных между таблицами.
После проектирования структуры выбирается система управления базами данных. Для учебных и малых проектов часто используют MySQL или PostgreSQL, так как они поддерживают строгие связи и стандартный SQL. Выбор СУБД определяет доступные типы данных, ограничения и инструменты администрирования.
Создание базы данных выполняется через консоль или графический интерфейс. Сначала создаётся сама база, затем таблицы в нужном порядке, чтобы зависимости между ними не вызывали ошибок. После этого добавляются ограничения: уникальность для логинов, проверки диапазонов чисел, запрет на удаление связанных записей.
- Создание базы данных с указанием кодировки.
- Добавление таблиц с первичными ключами.
- Настройка связей между таблицами.
- Добавление ограничений целостности данных.
Завершающий шаг – заполнение базы тестовыми данными и выполнение запросов выборки, обновления и удаления. Это позволяет проверить, корректно ли работают связи и ограничения. Если запросы становятся сложными или возвращают дублирующиеся данные, структура требует доработки до начала использования базы в рабочем проекте.
Определение задач и типов данных для будущей базы
Первый шаг – точное описание задач, которые должна решать база данных. Нужно зафиксировать операции: хранение записей, поиск по параметрам, обновление статусов, удаление устаревших данных. Например, если система должна отслеживать историю заказов, требуется сохранение изменений статусов и дат, а не только текущего состояния.
После формулировки задач определяется набор данных. Каждая запись должна отвечать на конкретный вопрос системы. Для базы клиентов это идентификатор, контактные данные, источник регистрации; для товаров – артикул, цена, остаток, категория. Исключаются поля, которые не используются в запросах или отчётах.
- Составить список операций, которые выполняются с данными.
- Определить сущности, участвующие в этих операциях.
- Зафиксировать минимально необходимый набор полей для каждой сущности.
- Определить, какие данные должны храниться постоянно, а какие вычисляются на лету.
Выбор типов данных выполняется с учётом назначения поля. Идентификаторы задаются числовыми типами с автоинкрементом, даты и время – специализированными типами, строки ограничиваются длиной. Для денежных значений используется фиксированная точность, чтобы избежать ошибок округления.
- Числовые типы для идентификаторов и количественных показателей.
- Строковые типы с ограничением длины для текстовых полей.
- Типы даты и времени для событий и изменений.
- Логические значения для флагов и состояний.
На этом этапе также определяются требования к обязательности данных. Поля, без которых запись теряет смысл, помечаются как обязательные. Например, заказ не может существовать без пользователя, а товар – без цены. Такие ограничения формируют основу целостности будущей базы.
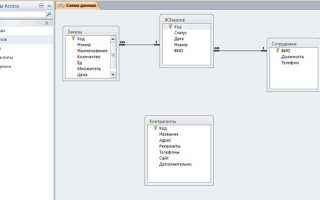
Выбор модели данных: таблицы, связи и ключи
Модель данных определяет, как информация будет организована и связана внутри базы. Для большинства прикладных систем используется реляционная модель, где каждая сущность представлена отдельной таблицей. Например, пользователи, заказы и товары хранятся раздельно, что позволяет обновлять данные без затрагивания связанных записей.
При проектировании таблиц важно придерживаться правила: одна таблица – одна логическая сущность. Если в одной структуре появляются данные разного назначения, это усложняет запросы и контроль целостности. Повторяющиеся значения выносятся в отдельные таблицы, а связь между ними создаётся через идентификаторы.
Связи между таблицами задаются на основе бизнес-логики. Связь один-к-одному применяется редко, чаще используются один-ко-многим и многие-ко-многим. Например, один пользователь может иметь несколько заказов, а заказ может включать несколько товаров через промежуточную таблицу позиций заказа.
Ключи обеспечивают однозначность и связность данных. Первичный ключ идентифицирует запись внутри таблицы и не должен изменяться. Обычно используется числовое поле с автоинкрементом. Внешние ключи ссылаются на первичные ключи других таблиц и контролируют допустимые связи между записями.
При выборе ключей важно учитывать будущие операции. Если данные часто используются в фильтрации или объединении таблиц, соответствующие поля должны быть индексированы. Это особенно актуально для внешних ключей, так как они участвуют в большинстве соединений при выполнении запросов.
Корректно выбранная модель данных упрощает добавление новых сущностей и изменение существующих связей. Если структура изначально отражает реальные отношения между данными, дальнейшее развитие базы не требует полного пересмотра схемы.
Проектирование структуры таблиц и полей
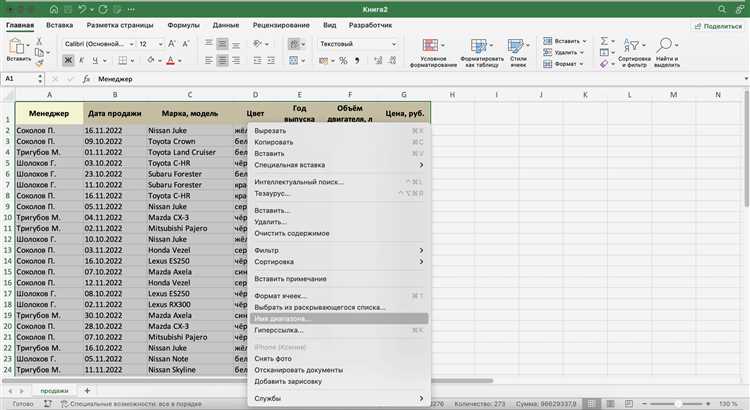
Проектирование структуры начинается с точного определения состава таблиц и их назначения. Каждая таблица должна хранить данные одного типа: пользователи, заказы, товары, категории. Смешивание разнородных данных в одной структуре усложняет обновление записей и контроль связей.
Для каждой таблицы формируется перечень полей с фиксированным смыслом. Названия должны однозначно отражать содержимое: user_id, order_date, product_price. Не допускается хранение нескольких значений в одном поле, например списка товаров в текстовом виде. Такие данные выносятся в отдельные таблицы.
| Поле | Назначение | Тип данных |
|---|---|---|
| id | Уникальный идентификатор записи | INTEGER |
| created_at | Дата и время создания | DATETIME |
| status | Состояние записи | VARCHAR |
Типы данных подбираются с учётом объёма и характера информации. Для идентификаторов используются числовые типы, для дат – специализированные форматы, для текстовых значений задаётся максимальная длина. Это снижает риск ошибок при вводе и упрощает проверку данных.
Каждое поле оценивается с точки зрения обязательности. Если значение необходимо для корректной работы системы, оно должно быть задано как обязательное. Например, запись заказа без ссылки на пользователя теряет смысл и должна блокироваться на уровне структуры таблицы.
Итоговая структура проверяется на избыточность. Если одно и то же значение повторяется в разных таблицах, оно выносится в отдельную сущность. Такой подход упрощает изменение данных и снижает вероятность расхождений между связанными записями.
Выбор СУБД и подготовка рабочей среды
Выбор системы управления базами данных зависит от структуры данных и предполагаемых операций. Для проектов со строгими связями между сущностями и поддержкой транзакций подходят PostgreSQL и MySQL. Если данные хранятся в виде документов с переменной структурой, рассматриваются нереляционные решения, такие как MongoDB, но это меняет подход к проектированию.
При выборе СУБД учитываются поддерживаемые типы данных, механизмы ограничений, возможности индексации и инструменты резервного копирования. Например, PostgreSQL предоставляет расширенные типы и проверки, что упрощает контроль целостности, а MySQL часто используется в веб-проектах благодаря широкой поддержке хостингами.
Подготовка рабочей среды начинается с установки СУБД и настройки пользователя с ограниченными правами. Работа под отдельной учётной записью снижает риск случайного удаления данных и позволяет разграничить доступ между разработкой и эксплуатацией.
Для управления базой данных используются консольные клиенты или графические инструменты. Консоль удобна для автоматизации и точного контроля команд, графические интерфейсы упрощают визуальный анализ структуры и выполнение запросов на этапе разработки.
На этапе подготовки также задаётся кодировка базы данных и параметры локали. Это важно для корректного хранения текстовых данных и сортировки строк. Неверно выбранная кодировка приводит к искажению символов и проблемам при поиске.
Завершает настройку создание отдельной базы для разработки. В ней отрабатываются изменения структуры и запросы, не затрагивая рабочие данные. Такой подход позволяет безопасно вносить корректировки до переноса схемы в основную среду.
Создание базы данных и таблиц с помощью SQL-команд
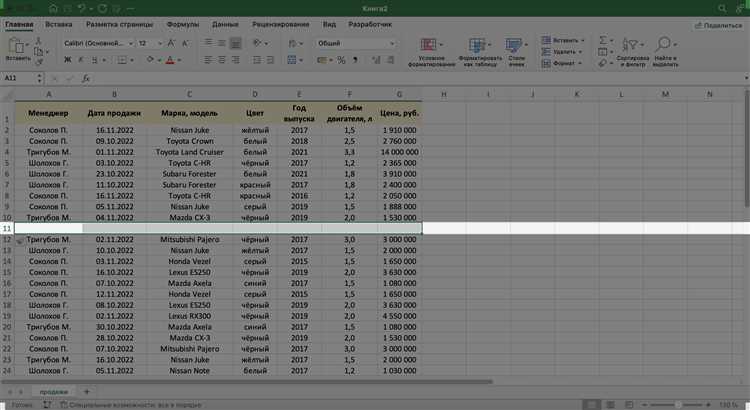
После подготовки среды работа переходит к SQL. Сначала создаётся база данных с указанием кодировки и правил сортировки строк. Это задаёт основу для корректного хранения текстовых значений, особенно если используются кириллические данные и поиск без учёта регистра.
Далее последовательно создаются таблицы. Начинают с независимых сущностей, которые не содержат внешних ссылок, например таблицы пользователей или категорий. Для каждой таблицы задаётся первичный ключ, обычно числовой идентификатор, который однозначно определяет запись и используется в связях.
При описании таблицы в SQL перечисляются поля, их типы данных и ограничения. Для обязательных значений указывается запрет на пустые данные, для уникальных – соответствующее ограничение. Например, адрес электронной почты пользователя должен быть уникальным, а дата создания записи – заполняться автоматически.
После создания базовых таблиц добавляются структуры, зависящие от них. Таблицы заказов, позиций заказов или логов содержат внешние ключи, которые ссылаются на уже существующие записи. Эти связи задаются на уровне SQL, чтобы база блокировала добавление некорректных данных.
Важно соблюдать порядок выполнения команд. Если попытаться создать таблицу с внешним ключом до существования связанной таблицы, СУБД вернёт ошибку. Поэтому структура продумывается заранее и реализуется поэтапно.
Завершающий шаг – проверка созданных таблиц через системные запросы. Просматривается список таблиц, структура полей и заданные ограничения. Это позволяет убедиться, что схема соответствует проекту и готова к заполнению данными.
Настройка связей между таблицами и ограничений данных
Связи между таблицами формируют целостную структуру базы данных и задаются через внешние ключи. Каждый внешний ключ указывает на первичный ключ другой таблицы и запрещает появление ссылок на несуществующие записи. Например, поле user_id в таблице заказов должно ссылаться на идентификатор пользователя, иначе заказ не имеет логического смысла.
При создании связей важно определить поведение данных при изменении или удалении записей. Для справочников обычно запрещается удаление используемых записей, а для зависимых данных допускается каскадное удаление. Такой выбор влияет на сохранность истории и корректность отчётов.
Ограничения данных контролируют допустимые значения полей. Обязательные поля блокируют вставку неполных записей, уникальные ограничения предотвращают дублирование логинов, номеров документов или артикулов. Проверки диапазонов применяются для числовых значений, таких как количество или сумма.
Для повышения точности данных используются проверки формата. Например, поле со статусом заказа ограничивается фиксированным набором значений, что исключает появление произвольных состояний и упрощает обработку данных в приложении.
Настройка связей сопровождается добавлением индексов на внешние ключи. Это ускоряет объединение таблиц в запросах и снижает нагрузку при выборке связанных данных. Без индексов даже корректно спроектированная схема начинает работать медленно при росте объёма записей.
После настройки всех ограничений выполняется тестирование. Добавляются корректные и заведомо ошибочные данные, чтобы убедиться, что база блокирует нарушения и принимает только допустимые значения. Такой контроль выявляет проблемы до начала использования базы в рабочей системе.
Заполнение базы тестовыми данными и проверка запросов
После настройки структуры база наполняется тестовыми данными, которые имитируют реальные сценарии использования. Количество записей должно быть достаточным для проверки связей и выборок: несколько десятков пользователей, сотни заказов, разные статусы и даты. Случайные данные без логики не подходят, так как они не отражают реальные цепочки операций.
Заполнение выполняется поэтапно. Сначала добавляются записи в справочные таблицы, затем в основные, и только после этого – в зависимые. Такой порядок исключает ошибки внешних ключей и позволяет сразу увидеть, корректно ли работают ограничения.
Проверка начинается с простых запросов выборки. Необходимо убедиться, что данные корректно извлекаются по идентификаторам, датам и статусам. Особое внимание уделяется соединениям таблиц, так как именно они выявляют ошибки в настройке связей.
Далее тестируются запросы изменения данных. Обновление статусов, пересчёт сумм, удаление записей проверяются на соблюдение ограничений. Попытки нарушить правила, например удалить запись, на которую есть ссылки, должны завершаться ошибкой со стороны СУБД.
Отдельно проверяются граничные случаи: пустые результаты выборки, максимальные значения полей, отсутствие связанных данных. Это позволяет выявить проблемы в логике запросов до подключения приложения.
Завершающий этап – анализ скорости выполнения запросов. При заметных задержках пересматриваются условия фильтрации и наличие индексов. Тестовые данные служат основой для доработки схемы и запросов перед переходом к рабочему использованию базы.
Вопрос-ответ:
С чего начать создание базы данных, если есть только идея проекта?
Начать стоит с фиксации задач, которые должна решать база данных. Нужно описать действия пользователей, операции с данными и ожидаемые отчёты. После этого выделяются сущности, например пользователи, заказы, товары, и определяется, какие данные по каждой из них реально используются. Только затем имеет смысл переходить к проектированию таблиц и выбору СУБД.
Как понять, какие данные хранить в базе, а какие рассчитывать в запросах?
В базе сохраняются значения, которые имеют самостоятельный смысл и используются повторно: цены, даты, статусы, связи между объектами. Производные данные, такие как итоговая сумма заказа или количество позиций, удобнее вычислять в запросах. Это снижает риск расхождений при обновлении исходных значений.
Нужно ли сразу настраивать внешние ключи и ограничения?
Да, настройка ограничений на этапе создания структуры позволяет отсеять некорректные данные ещё до появления приложения. Внешние ключи предотвращают появление «висячих» ссылок, а ограничения уникальности и обязательности блокируют дубли и неполные записи. Без них ошибки будут накапливаться и проявятся позже.
Какие ошибки чаще всего допускают при проектировании таблиц?
Частая ошибка — хранение нескольких значений в одном поле, например списка товаров через запятую. Также встречается дублирование данных в разных таблицах и отсутствие чётких первичных ключей. Такие решения усложняют запросы и приводят к несогласованным данным при обновлениях.
Зачем заполнять базу тестовыми данными до подключения приложения?
Тестовые данные позволяют проверить структуру, связи и запросы без риска для рабочих записей. На этом этапе легко увидеть ошибки в логике объединения таблиц, неверные ограничения и проблемы с выборкой. Исправления на ранней стадии занимают меньше времени, чем переделка базы после запуска проекта.
Можно ли сначала создать таблицы, а потом продумать связи между ними?
Такой подход возможен, но он часто приводит к переработке структуры. Если связи не учтены заранее, появляются лишние поля, дублирующиеся данные и сложности с объединением таблиц. Гораздо практичнее заранее определить, какие таблицы зависят друг от друга, и уже с учётом этого создавать их структуру и ключи.
Нужно ли сразу закладывать рост объёма данных при создании базы?
Да, это влияет на выбор типов данных, ключей и индексов. Например, для идентификаторов лучше использовать типы с запасом по диапазону, а для часто используемых полей сразу предусмотреть индексацию. Если база создаётся без учёта увеличения числа записей, со временем запросы усложняются, а структура перестаёт соответствовать реальным нагрузкам.