Содержание статьи

Задача приведения первой буквы строки к верхнему регистру регулярно возникает при работе с пользовательскими данными: именами, названиями городов, товарами или категориями. В SQL для этого не существует универсальной команды, поскольку разные СУБД предлагают собственные функции обработки строк. Поэтому корректное решение всегда зависит от конкретного диалекта SQL и структуры данных.
На практике изменение первой буквы требует комбинирования нескольких строковых функций: выделения первого символа, изменения его регистра и последующей склейки с оставшейся частью строки. При этом важно учитывать NULL-значения, пустые строки, пробелы в начале текста и различия в поддержке Unicode. Ошибка в одном из этих пунктов может привести к некорректному обновлению данных или неожиданному результату запроса.
Отдельного внимания заслуживает работа с кириллицей и другими нелатинскими алфавитами. В одних СУБД функции UPPER и LOWER зависят от коллации, в других – от кодировки базы данных. Это напрямую влияет на то, будет ли корректно преобразована первая буква, особенно при использовании UPDATE-запросов к уже существующим данным.
В рамках статьи рассматриваются прикладные способы изменения первой буквы в популярных СУБД: MySQL, PostgreSQL и SQL Server. Все примеры ориентированы на реальные сценарии – выборку данных, обновление таблиц и обработку строк без потери остального содержимого.
Приведение первой буквы к верхнему регистру через UPPER и SUBSTRING
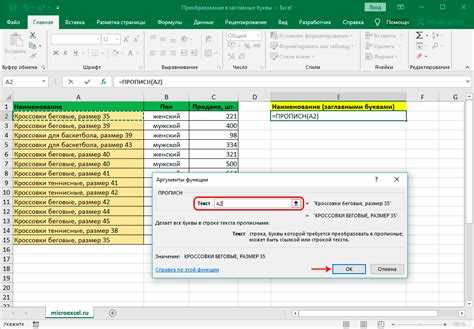
Базовый способ сделать первую букву строки заглавной в SQL основан на разбиении строки на две части: первый символ и остальной текст. Для этого используются функции UPPER и SUBSTRING (или SUBSTR – в зависимости от СУБД). Такой подход поддерживается практически всеми популярными СУБД и не требует специализированных функций.
Логика обработки выглядит следующим образом:
- извлечь первый символ строки;
- преобразовать его к верхнему регистру;
- получить оставшуюся часть строки без изменений;
- объединить части в одно значение.
Пример универсального выражения для выборки данных:
UPPER(SUBSTRING(column_name, 1, 1)) ||
SUBSTRING(column_name, 2)В MySQL и SQL Server для объединения строк используется CONCAT или оператор +:
CONCAT(
UPPER(SUBSTRING(column_name, 1, 1)),
SUBSTRING(column_name, 2)
)При работе с реальными данными важно учитывать граничные случаи:
- пустые строки возвращают пустой результат без ошибок;
- значения NULL требуют явной обработки через COALESCE или CASE;
- строки длиной в один символ корректно преобразуются без дополнительной логики.
Для обновления данных в таблице выражение используется напрямую в UPDATE:
UPDATE users
SET name = CONCAT(
UPPER(SUBSTRING(name, 1, 1)),
SUBSTRING(name, 2)
);Такой подход подходит для латиницы и кириллицы при корректно заданной кодировке и коллации базы данных. Если регистр первой буквы не меняется, причина чаще всего связана не с функциями, а с настройками сравнения строк.
Пример для MySQL с использованием CONCAT, UPPER и LOWER
В MySQL преобразование первой буквы строки к верхнему регистру чаще всего выполняется через комбинацию функций CONCAT, UPPER и LOWER. Такой подход позволяет не только изменить первую букву, но и привести остальную часть строки к нижнему регистру, что полезно при нормализации пользовательского ввода.
Типовое выражение для выборки данных выглядит так:
CONCAT(
UPPER(SUBSTRING(name, 1, 1)),
LOWER(SUBSTRING(name, 2))
)Здесь первый символ извлекается с помощью SUBSTRING и преобразуется функцией UPPER, а оставшаяся часть строки обрабатывается через LOWER. Это предотвращает ситуацию, когда после первой заглавной буквы сохраняется произвольный регистр.
Пример поведения выражения на разных входных данных:
| Исходное значение | Результат |
|---|---|
| иван | Иван |
| иВаН | Иван |
| ИВАН | Иван |
Для изменения данных в таблице используется аналогичное выражение в UPDATE:
UPDATE users
SET name = CONCAT(
UPPER(SUBSTRING(name, 1, 1)),
LOWER(SUBSTRING(name, 2))
)
WHERE name IS NOT NULL;Условие WHERE name IS NOT NULL защищает запрос от непредсказуемого результата при работе с NULL. Для строк длиной в один символ MySQL корректно применяет UPPER, а SUBSTRING возвращает пустую строку без ошибки.
Корректная обработка кириллицы возможна только при использовании кодировки utf8mb4 и подходящей коллации. При неправильных настройках первая буква может остаться без изменений, даже если синтаксис запроса верный.
Решение для PostgreSQL: INITCAP и альтернатива для одной буквы
PostgreSQL предоставляет встроенную функцию INITCAP, которая преобразует первую букву каждого слова в строке к верхнему регистру. Для задач форматирования имен, названий или адресов это удобный инструмент, так как он сразу обрабатывает пробелы и разделители слов без дополнительной логики.
Пример использования INITCAP в запросе выборки:
SELECT INITCAP(name) FROM users;Результатом будет строка, где каждая часть, разделенная пробелом или символом пунктуации, начинается с заглавной буквы. Это важно учитывать, если требуется изменить регистр только первого символа всей строки, а не каждого слова.
Когда необходимо преобразовать исключительно первую букву, используется комбинация стандартных строковых функций PostgreSQL:
UPPER(SUBSTRING(name FROM 1 FOR 1)) ||
SUBSTRING(name FROM 2)Такое выражение дает полный контроль над результатом и не затрагивает остальные слова в строке. При необходимости можно дополнительно привести хвост строки к нижнему регистру:
UPPER(SUBSTRING(name FROM 1 FOR 1)) ||
LOWER(SUBSTRING(name FROM 2))Для обновления данных в таблице выражение применяется напрямую в UPDATE:
UPDATE users
SET name =
UPPER(SUBSTRING(name FROM 1 FOR 1)) ||
LOWER(SUBSTRING(name FROM 2))
WHERE name IS NOT NULL;PostgreSQL корректно работает с кириллицей при использовании кодировки UTF-8. Если преобразование не происходит, следует проверить коллацию базы данных, так как именно она определяет правила изменения регистра для нелатинских символов.
Пример для SQL Server с функцией STUFF и UPPER
В SQL Server для замены первого символа строки удобно использовать функцию STUFF. Она позволяет удалить часть строки и вставить новое значение в заданную позицию, что избавляет от явной конкатенации и делает выражение компактным.
Базовый вариант преобразования первой буквы к верхнему регистру выглядит так:
STUFF(name, 1, 1, UPPER(LEFT(name, 1)))Здесь используются сразу две функции:
- LEFT(name, 1) – извлекает первый символ строки;
- UPPER – переводит его в верхний регистр;
- STUFF – заменяет первый символ исходной строки на преобразованный.
Если требуется дополнительно привести остальную часть строки к нижнему регистру, применяется более строгий вариант:
STUFF(
LOWER(name),
1,
1,
UPPER(LEFT(name, 1))
)Такой подход полезен при обработке данных, введенных в произвольном регистре, например имен пользователей или названий.
Для массового обновления значений в таблице используется стандартный UPDATE:
UPDATE users
SET name = STUFF(
LOWER(name),
1,
1,
UPPER(LEFT(name, 1))
)
WHERE name IS NOT NULL;При работе с SQL Server стоит учитывать следующие моменты:
- пустые строки не вызывают ошибок и остаются пустыми;
- значения NULL необходимо исключать через условие WHERE;
- поддержка кириллицы зависит от коллации столбца, а не от синтаксиса запроса.
Использование STUFF особенно удобно в SQL Server, так как функция оптимизирована для строковых операций и хорошо читается в UPDATE-запросах.
Обработка NULL и пустых строк при изменении регистра
При приведении первой буквы к верхнему регистру особое внимание требуется значениям NULL и пустым строкам. Большинство строковых функций SQL не вызывают ошибок, но возвращают NULL, что может привести к непреднамеренному перезаписыванию данных при выполнении UPDATE.
Если столбец допускает NULL, безопаснее явно исключать такие строки из обработки. Универсальный прием – использование условия в WHERE:
WHERE column_name IS NOT NULLАльтернативный вариант – подстановка пустой строки через COALESCE, если требуется получить гарантированный строковый результат:
UPPER(SUBSTRING(COALESCE(column_name, ''), 1, 1)) ||
SUBSTRING(COALESCE(column_name, ''), 2)Пустые строки обрабатываются иначе. Функции SUBSTRING, LEFT и аналогичные возвращают пустое значение без ошибок, поэтому дополнительная логика обычно не требуется. Однако при использовании LOWER и UPPER в UPDATE-запросах важно понимать, что пустая строка будет перезаписана как пустая, даже если это нежелательно.
Для точного контроля результата применяется конструкция CASE, которая разделяет обработку по длине строки:
CASE
WHEN column_name IS NULL THEN NULL
WHEN column_name = '' THEN ''
ELSE
UPPER(SUBSTRING(column_name, 1, 1)) ||
SUBSTRING(column_name, 2)
ENDТакой подход позволяет сохранить исходные NULL и пустые значения без изменений, одновременно корректно обрабатывая строки с реальным содержимым. Это особенно важно при обновлении данных в production-базах, где потеря различий между NULL и пустой строкой может повлиять на логику приложения.
Учет пробелов и ведущих символов в строке
При работе с реальными строковыми данными первая буква не всегда находится в первой позиции. Часто значения содержат ведущие пробелы, табуляцию или служебные символы, из-за чего стандартное выражение с SUBSTRING и UPPER изменяет не букву, а пробел, оставляя текст без видимых изменений.
Для устранения этой проблемы применяется предварительная очистка строки. Наиболее распространенный вариант – использование TRIM, LTRIM или RTRIM:
UPPER(SUBSTRING(LTRIM(name), 1, 1)) ||
SUBSTRING(LTRIM(name), 2)Такое выражение удаляет пробелы слева и гарантирует, что преобразование применяется именно к первому символу текста. Если требуется сохранить исходное количество пробелов, предварительная обрезка не подходит, и логика усложняется.
В случаях, когда строка начинается с символов пунктуации, цифр или специальных знаков, важно определить, что именно считается «первой буквой». SQL не умеет находить буквенные символы без регулярных выражений, поэтому используются функции поиска позиции:
SUBSTRING(name, PATINDEX('%[A-Za-zА-Яа-я]%', name), 1)В SQL Server такой подход позволяет найти первую букву в строке и изменить регистр именно у нее. В PostgreSQL и MySQL аналогичное поведение достигается через REGEXP или SIMILAR TO, но выражения становятся более громоздкими.
Если данные поступают из внешних источников, рекомендуется нормализовать строки до сохранения в таблицу. Очистка ведущих пробелов и символов на этапе вставки упрощает последующую работу с регистром и снижает риск некорректных обновлений.
Работа с Unicode и настройками кодировок
Корректное преобразование первой буквы к верхнему регистру напрямую зависит от поддержки Unicode и настроек кодировки в базе данных. Даже при правильном SQL-выражении функции UPPER и LOWER могут не изменить кириллические символы, если столбец или база используют неподходящую кодировку.
В MySQL рекомендуется использовать utf8mb4 как для базы данных, так и для отдельных столбцов. При старых кодировках, таких как latin1, изменение регистра работает только для латиницы. Проверить текущие настройки можно через SHOW CREATE TABLE или SHOW VARIABLES LIKE ‘character_set%’.
PostgreSQL по умолчанию работает с UTF-8, но результат функций изменения регистра определяется LC_COLLATE и LC_CTYPE. Если база создана с некорректной локалью, кириллица может не распознаваться как буквенный символ, что влияет на UPPER, LOWER и INITCAP.
В SQL Server ключевую роль играет коллация столбца. Для работы с Unicode необходимо использовать типы NVARCHAR и NCHAR, а также коллации с поддержкой нужного языка. При использовании VARCHAR часть символов может обрабатываться как однобайтовые, что приводит к некорректному изменению регистра.
Перед массовым обновлением данных рекомендуется протестировать выражение на выборке с разными алфавитами. Это позволяет выявить проблемы с кодировкой до выполнения UPDATE и избежать повреждения текстовых значений, особенно в многоязычных проектах.
Обновление значений в таблице без изменения остальных символов

При изменении первой буквы в существующих данных ключевая задача – не затронуть остальные символы строки. Это особенно важно, если текст уже содержит корректный регистр, спецсимволы или данные, чувствительные к формату, например артикулы и идентификаторы.
Для безопасного обновления используется замена строго одного символа без применения LOWER ко всей строке. Универсальная логика сводится к извлечению первого символа, его преобразованию и объединению с неизмененной частью строки:
UPPER(SUBSTRING(name, 1, 1)) || SUBSTRING(name, 2)Такой подход сохраняет исходный регистр всех символов, начиная со второго. Это критично, если строка содержит аббревиатуры, смешанный регистр или пользовательские обозначения.
При выполнении UPDATE рекомендуется ограничивать выборку строк, которые действительно требуют изменения. Пример условия для PostgreSQL:
WHERE name IS NOT NULL
AND SUBSTRING(name FROM 1 FOR 1) <> UPPER(SUBSTRING(name FROM 1 FOR 1))В MySQL и SQL Server аналогичное сравнение выполняется через LEFT или SUBSTRING. Такое условие снижает количество обновляемых строк и уменьшает риск блокировок при работе с большими таблицами.
Если данные содержат ведущие пробелы, их следует обработать заранее, иначе будет изменен не буквенный символ. При этом важно не применять глобальную очистку строки, если пробелы имеют смысл в бизнес-логике.
Перед выполнением обновления на production-данных рекомендуется выполнить SELECT с тем же выражением. Это позволяет визуально проверить результат и убедиться, что изменяется только первая буква, а остальное содержимое остается без изменений.
Вопрос-ответ:
Почему UPPER и LOWER не меняют первую букву кириллической строки?
Чаще всего причина связана с кодировкой или коллацией столбца. В MySQL это происходит при использовании latin1 вместо utf8mb4, а в SQL Server — при работе с VARCHAR и неподходящей коллацией. Функции изменения регистра выполняются, но не распознают кириллические символы как буквенные.
Можно ли сделать первую букву заглавной только у первого слова, а не у всей строки?
Да. Для этого не подходит INITCAP в PostgreSQL, так как он обрабатывает каждое слово. Нужно использовать извлечение первого символа всей строки через SUBSTRING или LEFT, преобразовать его функцией UPPER и объединить с оставшейся частью строки без изменений.
Как обработать строки, которые начинаются с пробелов?
Если пробелы не имеют смысловой нагрузки, применяется LTRIM или TRIM перед извлечением первого символа. Если пробелы нужно сохранить, потребуется определить позицию первой буквы через функции поиска или регулярные выражения и заменить символ именно в этой позиции.
Что произойдет при UPDATE, если в столбце есть NULL и пустые строки?
NULL останется NULL, если он не обработан явно, а пустая строка перезапишется как пустая. Чтобы сохранить различия между этими значениями, в запрос добавляют WHERE с проверкой на NULL или используют CASE, разделяя логику обработки.
Как изменить первую букву, не затрагивая остальной регистр строки?
Не следует применять LOWER ко всей строке. Используется замена только первого символа: UPPER(SUBSTRING(col, 1, 1)) и объединение с SUBSTRING(col, 2). Такой подход сохраняет исходный регистр остальных символов, включая аббревиатуры и смешанные форматы.