Содержание статьи

При работе с массивами в программировании важно понимать, где именно происходит выделение памяти для их хранения. Это напрямую влияет на производительность, безопасность программы и управление памятью. Массивы могут выделяться в разных сегментах памяти, таких как стек, куча или даже в статическом сегменте, в зависимости от типа данных и особенностей языка программирования.
Стек используется для хранения массивов с фиксированным размером, определённым во время компиляции. Это быстрый способ выделения памяти, так как память под массивы на стеке автоматически освобождается, когда выходит из области видимости функция, в которой был создан массив. Однако стек ограничен по объему, и попытка выделить слишком большой массив может привести к переполнению стека.
Если размер массива известен только во время выполнения программы, память под него выделяется в куче. Это позволяет гибко работать с массивами переменной длины. Куча предоставляет значительно больше памяти, но выделение и освобождение памяти здесь происходит медленнее, чем на стеке. Языки, такие как C и C++, требуют явного управления выделением и освобождением памяти, что может привести к ошибкам, таким как утечки памяти.
Для статических и глобальных массивов память выделяется в статическом сегменте программы. Эти массивы существуют на протяжении всего времени работы программы и их размер задается во время компиляции. Память для таких массивов выделяется один раз, и она не освобождается, пока программа не завершит свою работу.
Важно учитывать, что выбор сегмента памяти влияет на работу с массивами. Например, динамическое выделение памяти в куче подходит для массивов, размер которых меняется во время работы программы, но требует контроля за её освобождением. Стек же более эффективен в случае, когда размер массива известен заранее и не меняется.
Как операционная система управляет памятью для массивов
Операционная система играет ключевую роль в управлении памятью при выделении под массивы. Она отвечает за распределение и освобождение памяти, обеспечение изоляции процессов и предотвращение конфликтов при доступе к памяти. В зависимости от типа массива и его размещения в памяти, операционная система использует различные механизмы для эффективного использования доступных ресурсов.
Когда программа запрашивает память для массива, операционная система может использовать один из нескольких подходов. Для массивов, размер которых известен заранее, система выделяет память на стеке. Это происходит быстро, так как стек работает по принципу LIFO (последний вошел – первый вышел), и память автоматически освобождается, когда функция завершает выполнение. Стек ограничен по размеру, поэтому операционная система ограничивает объём памяти, который может быть выделен на стеке, чтобы избежать переполнения.
Для динамических массивов, размер которых зависит от данных, операционная система обращается к куче. При выделении памяти для такого массива, система ищет свободные участки в куче, где могут быть размещены данные. В отличие от стека, память в куче не освобождается автоматически, и программист или сборщик мусора должен явно освободить её. Операционная система отслеживает фрагментацию памяти в куче, что может повлиять на производительность при частом выделении и освобождении памяти.
При работе с массивами операционная система использует таблицы страниц и механизмы виртуальной памяти для управления доступом к памяти. Это позволяет процессам работать с большими объёмами данных, чем доступно физической памяти, эффективно используя диск как расширение оперативной памяти. Виртуальная память обеспечивает изоляцию процессов, так что каждый процесс может работать со своим собственным пространством памяти, не влияя на другие.
Кроме того, операционная система активно управляет пулом памяти, перераспределяя её между процессами по мере необходимости. В случае дефицита памяти система может применять механизмы свопинга, перемещая данные между оперативной памятью и файловой системой, что может повлиять на производительность при работе с массивами большого размера.
Память под массивы в стеке и её особенности
Когда память для массива выделяется в стеке, она занимает фиксированное пространство, которое определяется на момент компиляции программы. Стек работает по принципу LIFO (последний вошел – первый вышел), что означает автоматическое освобождение памяти, когда функция, в которой был объявлен массив, завершает выполнение. Это делает работу с массивами на стеке быстрой и предсказуемой.
Одним из главных ограничений памяти в стеке является её размер. Операционные системы обычно задают ограничения на размер стека для каждого потока, что может вызвать переполнение стека, если массив окажется слишком большим. Например, в большинстве систем размер стека для одного потока ограничен несколькими мегабайтами, что является достаточным для небольших массивов. Однако при попытке выделить массивы большого размера на стеке может произойти ошибка переполнения стека (stack overflow).
Массивы на стеке могут быть как одномерными, так и многомерными, однако важно, что их размер должен быть известен заранее. Это делает стек подходящим для использования в случаях, когда размер массива не меняется во время выполнения программы. В случае многомерных массивов в стеке операционная система выделяет память для всех элементов массива в одном блоке, что упрощает управление памятью, но накладывает ограничения на гибкость.
Использование стека для массивов предпочтительно, когда требуется высокая скорость выделения и освобождения памяти, поскольку этот процесс происходит автоматически, без необходимости дополнительного управления. Однако, если массив слишком велик, то предпочтительнее использовать динамическое выделение памяти в куче, чтобы избежать проблем с переполнением стека и ограничениями на размер.
Для работы с массивами на стеке важно учитывать специфику операционной системы и конфигурацию стека. В некоторых случаях может быть полезно настроить размер стека для потоков программы, если это возможно, чтобы избежать ошибок переполнения при работе с большими массивами. Также следует помнить, что память стека ограничена размером процесса и может повлиять на общую производительность, если программы активно используют много стека для хранения данных.
Выделение памяти под массивы в куче: когда это нужно

Выделение памяти под массивы в куче необходимо, когда размер массива не известен на момент компиляции или когда массив должен изменять свой размер во время выполнения программы. В отличие от стека, куча предоставляет гораздо больше пространства и позволяет динамически изменять размеры массивов, что особенно важно для работы с большими объёмами данных.
Основные случаи, когда нужно выделять память в куче:
- Динамическое изменение размера массива – когда размер массива зависит от данных, получаемых во время выполнения программы. Например, если массив формируется в результате пользовательского ввода или обработки больших файлов.
- Большие массивы – если размер массива превышает ограничения стека. Массивы, требующие много памяти, часто лучше хранить в куче, чтобы избежать переполнения стека.
- Передача массивов между функциями – если массив должен быть доступен в нескольких функциях или потоках. Куча позволяет передавать указатели на массивы, не копируя их содержимое.
- Управление памятью через сборщик мусора – в языках с автоматическим управлением памятью (например, Java, Python) массивы чаще всего размещаются в куче. Сборщик мусора автоматически освобождает память, что снижает риск утечек памяти.
Одним из преимуществ кучи является её гибкость: память для массива можно выделить в любой момент времени, а его размер можно изменять в процессе работы программы. Однако, это требует дополнительных затрат на управление памятью, таких как выделение и освобождение памяти, что делает работу с кучей более медленной по сравнению с памятью стека.
Кроме того, куча более подвержена фрагментации памяти, что может ухудшить производительность при частых операциях выделения и освобождения памяти. Чтобы минимизировать этот эффект, важно следить за эффективностью использования памяти и избегать ненужного выделения памяти.
Таким образом, выделение памяти в куче нужно в случаях, когда требуется гибкость в управлении памятью и работа с большими или изменяющимися массивами, но важно учитывать, что это может повлиять на производительность из-за дополнительных затрат на управление памятью.
Как использование динамических массивов влияет на распределение памяти
Использование динамических массивов существенно меняет подход к управлению памятью в программе. В отличие от статических массивов, которые имеют фиксированный размер, динамические массивы позволяют выделять память в процессе выполнения программы. Это предоставляет гибкость, но также влечёт за собой некоторые особенности распределения памяти и управления ею.
Основное отличие динамических массивов от статических заключается в том, что они выделяются в куче, а не на стеке. Это означает, что размер массива может изменяться в процессе работы программы. Для этого операционная система выделяет блок памяти, который может быть перераспределён при необходимости, что важно при работе с массивами, чьё количество элементов заранее неизвестно или меняется.
Одним из первых последствий такого подхода является необходимость дополнительного контроля за памятью. В случае с динамическими массивами программист или сборщик мусора должен вручную управлять процессом выделения и освобождения памяти. Если не освободить память вовремя, это может привести к утечкам памяти. В языках без автоматического управления памятью, таких как C или C++, ошибки в освобождении памяти могут стать причиной серьёзных проблем в работе программы.
Другим аспектом использования динамических массивов является их фрагментация. Когда массив увеличивается или уменьшается, операционная система может быть вынуждена перемещать его в другой участок памяти. Это может приводить к фрагментации кучи – процессу, когда свободные участки памяти разбросаны по всему доступному пространству, что ухудшает производительность при частых операциях выделения и освобождения памяти.
Кроме того, чтобы избежать излишнего расхода памяти, многие системы выделяют дополнительное пространство при увеличении размера динамического массива. Например, вместо того, чтобы выделять точный размер массива, система может удваивать его размер каждый раз, когда массив переполняется. Это позволяет уменьшить количество операций перераспределения памяти, но приводит к дополнительным расходам памяти, так как часть пространства остаётся неиспользованной.
Таким образом, использование динамических массивов даёт гибкость в управлении памятью, но требует более тщательного контроля, чтобы избежать утечек памяти и фрагментации. Важно учитывать как особенности работы операционной системы, так и особенности конкретного языка программирования, чтобы эффективно управлять памятью и минимизировать потери производительности.
Роль системы управления памятью в языках программирования

Система управления памятью играет ключевую роль в эффективном выделении и освобождении памяти под массивы и другие структуры данных. В зависимости от особенностей языка программирования, управление памятью может осуществляться как вручную, так и автоматически, что влияет на производительность, безопасность и удобство разработки.
В языках программирования с ручным управлением памятью, таких как C и C++, программист сам отвечает за выделение и освобождение памяти. Это предоставляет большую гибкость, но также требует внимательности, поскольку ошибки, такие как утечка памяти или доступ к уже освобождённым участкам, могут привести к сбоям программы или её нестабильной работе. В таких языках операционная система не вмешивается в процессы выделения памяти, предоставляя низкоуровневые функции для работы с памятью, например, malloc и free в C.
В языках с автоматическим управлением памятью, таких как Java или Python, система управления памятью заботится о выделении и освобождении памяти. Эти языки используют сборщик мусора, который периодически сканирует память, находит объекты, больше не используемые программой, и освобождает их. Это снижает вероятность ошибок, связанных с утечками памяти, но может повлиять на производительность, так как сборщик мусора работает асинхронно, иногда вызывая паузы в выполнении программы.
Механизмы управления памятью зависят от особенностей реализации операционной системы и используемого языка программирования. Например, в C++ динамическое выделение памяти для массивов часто происходит через операторы new и delete, в то время как в более высокоуровневых языках, таких как Java, выделение памяти происходит автоматически, а программист взаимодействует с памятью только через объекты и ссылки.
Также стоит отметить важность системы управления памятью при работе с массивами переменной длины. В языках, поддерживающих динамическое выделение памяти, таких как Python и JavaScript, массивы могут расти и сокращаться по мере необходимости. Однако за этими операциями стоит сложная работа системы управления памятью, которая должна минимизировать фрагментацию и обеспечивать эффективное перераспределение памяти.
Таким образом, система управления памятью определяет, как будет происходить выделение, перераспределение и освобождение памяти для массивов, что напрямую влияет на производительность и безопасность программы. Важно понимать, какой подход используется в конкретном языке, чтобы оптимизировать использование памяти и избежать проблем, связанных с её управлением.
Особенности выделения памяти под многомерные массивы
При выделении памяти под многомерные массивы важно учитывать, что они могут быть реализованы разными способами в зависимости от языка программирования и подхода к управлению памятью. Многомерные массивы могут быть представлены как массивы массивов (для языков с динамическим выделением памяти) или как единственный блок памяти (для языков с фиксированными размерами массивов). В обоих случаях особенности выделения памяти значительно различаются.
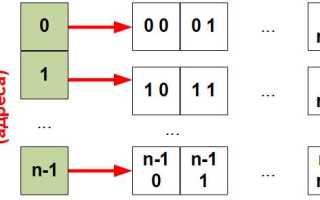
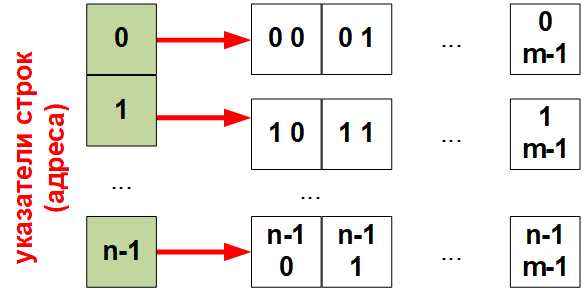
В языках с низким уровнем, таких как C, многомерные массивы часто реализуются как массивы массивов. В этом случае первый указатель указывает на массив указателей, каждый из которых в свою очередь указывает на одномерные массивы. Такое распределение памяти приводит к тому, что строки многомерного массива могут быть расположены в разных местах памяти, что может вызывать проблемы с производительностью из-за кэширования данных и фрагментации памяти. В отличие от этого, многомерные массивы в языках с высоким уровнем, таких как Python или Java, могут быть реализованы как единственный блок памяти, где элементы массива идут подряд.
В языках, поддерживающих динамическое выделение памяти, например, в C++, многомерный массив может быть создан с помощью динамической аллокации памяти с учётом размера каждого измерения. Примером этого является выделение памяти для двумерного массива через массив указателей на строки. Хотя такой подход даёт гибкость, он также требует более тщательного управления памятью, поскольку каждый уровень массивов выделяется отдельно, и необходимо следить за освобождением памяти каждого массива.
При выделении памяти для многомерных массивов важно учитывать и размерность массива. Для двумерных массивов размер каждого измерения может быть фиксированным или переменным. В случае фиксированного размера массивы могут быть размещены в одном блоке памяти, что позволяет использовать более эффективное распределение и доступ к данным. Однако для массивов с переменным размером, как например, для массива строк или таблицы данных, может потребоваться использование указателей и динамическое выделение памяти для каждого измерения.
В языках с автоматическим управлением памятью, таких как Java, многомерные массивы создаются как массивы ссылок на другие массивы. Например, двумерный массив будет представлять собой массив, каждый элемент которого является ссылкой на одномерный массив. Это упрощает управление памятью, но увеличивает накладные расходы на работу с указателями и добавляет дополнительные шаги в обработку данных. Также важно отметить, что такой подход может привести к меньшей плотности данных в памяти, что иногда снижает производительность при обработке больших массивов.
Как избежать утечек памяти при работе с массивами

Утечки памяти при работе с массивами могут возникать, когда выделенная память не освобождается после того, как она перестала быть необходимой. Это может привести к значительному снижению производительности программы и в конечном итоге к её сбоям. Чтобы избежать утечек, важно соблюдать несколько ключевых принципов и рекомендаций.
1. Правильное освобождение памяти – в языках с ручным управлением памятью, таких как C и C++, необходимо явно освобождать память после её использования. Для массивов, выделенных с помощью malloc или new, всегда вызывайте соответствующие функции для освобождения памяти, такие как free или delete. Не оставляйте массивы без освобождения, даже если они больше не используются, иначе это приведёт к утечке.
2. Использование умных указателей – в C++ рекомендуется использовать умные указатели, такие как std::unique_ptr или std::shared_ptr, которые автоматически управляют памятью. Это позволяет избежать утечек памяти при динамическом выделении массивов, так как память будет автоматически освобождена, когда указатель выйдет из области видимости.
3. Отслеживание выделений памяти – важно тщательно отслеживать, где и сколько памяти выделяется. Использование инструментов профилирования, таких как valgrind или AddressSanitizer, позволяет выявлять утечки памяти в процессе выполнения программы. Эти инструменты могут показать, какие участки программы не освобождают память должным образом.
4. Применение автоматического управления памятью – в языках с автоматическим сборщиком мусора, таких как Java или Python, управление памятью упрощено, но ошибки всё равно могут возникать. Например, если массив больше не используется, но на него всё ещё существуют ссылки, сборщик мусора не сможет освободить память. В таких случаях важно следить за правильностью удаления ссылок на массивы, когда они больше не нужны.
5. Осторожность при использовании массивов в многозадачных приложениях – при работе с многозадачностью и многопоточностью важно убедиться, что массивы не остаются заблокированными или не освобождаются в одном потоке, когда другой поток ещё может работать с ними. Это может привести к утечкам и сбоям, если несколько потоков пытаются управлять памятью одновременно. Для таких случаев используйте синхронизацию или соответствующие механизмы управления доступом к памяти.
6. Минимизация динамического выделения памяти – когда это возможно, старайтесь использовать статические или фиксированные массивы. Это минимизирует необходимость в динамическом выделении и освобождении памяти, а значит, и риск утечек. Однако если динамическое выделение неизбежно, старайтесь заранее определить возможные размеры массивов, чтобы избежать частых перераспределений памяти.
Следуя этим рекомендациям и применяя правильные методы управления памятью, можно значительно снизить вероятность утечек и улучшить стабильность и производительность программы.
Вопрос-ответ:
Где выделяется память под массивы в C++?
В C++ память для массивов может выделяться в разных местах в зависимости от того, как и где создаётся массив. Если массив объявляется внутри функции без использования динамической памяти, то его память будет выделяться на стеке. В случае, если массив создаётся с помощью оператора new, память выделяется в куче, и программист должен сам заботиться о её освобождении с помощью delete.
Что происходит, когда в языке с ручным управлением памятью не освободить память под массив?
Когда память, выделенная под массив, не освобождается, это приводит к утечке памяти. В результате этого освобождённые участки памяти не могут быть использованы для других задач, что постепенно приводит к дефициту доступной памяти и может привести к сбоям программы или её замедлению. В языках с ручным управлением памятью, таких как C или C++, программист должен самостоятельно следить за выделением и освобождением памяти.
Как операционная система управляет памятью под массивы в стеке?
Когда массив создаётся на стеке, операционная система автоматически выделяет и освобождает память при входе и выходе из области видимости функции. Стек работает по принципу LIFO (последний вошел — первый вышел), что означает, что память под массивы освобождается автоматически, когда функция завершает выполнение. Однако стек ограничен по объёму, и попытка выделить слишком большой массив на стеке может привести к переполнению.
Когда следует использовать динамическое выделение памяти для массивов?
Динамическое выделение памяти нужно использовать, когда размер массива заранее неизвестен или когда массив должен изменяться в процессе выполнения программы. Это удобно, например, при работе с данными, которые поступают от пользователя или из внешних источников. В таких случаях массив может быть расширен или уменьшен в зависимости от потребностей, а память для него выделяется в куче с помощью оператора new или функции malloc.
Могут ли многомерные массивы быть выделены в стеке?
Да, многомерные массивы могут быть выделены в стеке, но при этом их размер должен быть известен на момент компиляции. В этом случае многомерный массив будет представлять собой массив указателей на другие одномерные массивы, и память для каждого из них будет выделяться на стеке. Однако, если массив слишком велик или его размер меняется во время работы программы, его следует выделять в куче для более гибкого управления памятью.