Содержание статьи

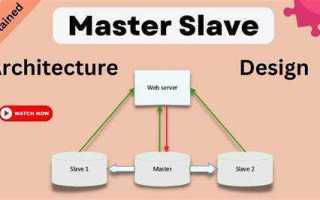
Master-slave – это архитектурная модель распределённых систем, в которой один узел выполняет роль управляющего центра, а остальные – роль подчинённых исполнителей. Мастер принимает запросы на изменение данных, назначает задачи, контролирует их выполнение и определяет порядок синхронизации. Слейвы получают инструкции, выполняют вычисления, хранят копии данных и возвращают результаты. Такая схема применяется в базах данных, кластерах приложений, системах очередей и распределённых файловых хранилищах.
В системах управления базами данных мастер обслуживает операции записи и фиксирует изменения в журнале транзакций, а слейвы получают эти изменения по каналу репликации и применяют их у себя с заданной задержкой. Для MySQL и PostgreSQL это означает необходимость отдельного сетевого соединения, выделенного пользователя репликации и контроля параметров задержки, чтобы отчётные и аналитические запросы направлялись только на слейвы, не влияя на операции записи.
При проектировании master-slave важно заранее определить сценарии отказа. В кластере должно быть настроено автоматическое назначение нового мастера, обновление точек подключения и защита от расхождения данных. На практике это реализуется через менеджеры кластера, проверку состояния узлов по тайм-аутам и запрет прямой записи на слейвы. Без этих мер архитектура перестаёт выполнять свою задачу – разгружать основной узел и поддерживать непрерывную работу сервисов.
Master-Slave: что это и как работает
Архитектура master-slave применяется для разделения потоков записи и чтения между узлами кластера. Мастер принимает все операции изменения данных, формирует журнал транзакций и управляет порядком их применения. Слейвы получают копии этих журналов и воспроизводят изменения у себя, создавая синхронизированные реплики. Такая модель используется в СУБД, распределённых очередях, кэш-системах и файловых хранилищах.
Процесс работы строится вокруг постоянного канала репликации. Для его стабильности на практике настраивают отдельный сетевой интерфейс, увеличенный размер буферов и лимиты на задержку, после превышения которых слейв считается отставшим и временно исключается из пула чтения.
- Мастер принимает запросы INSERT, UPDATE, DELETE и фиксирует изменения в журнале транзакций.
- Слейвы получают журнал по TCP-соединению и применяют операции в исходном порядке.
- Приложение направляет запросы чтения на слейвы через балансировщик.
- Задержка между мастером и слейвами контролируется метриками lag.
- Создать отдельного пользователя репликации с правами только на чтение журналов.
- Включить бинарное логирование и задать уникальные идентификаторы узлов.
- Настроить контроль задержки и автоматическое исключение отставших реплик.
- Реализовать механизм назначения нового мастера при сбое.
При корректной настройке master-slave позволяет перераспределить нагрузку, снизить время ответа на чтение и сохранить целостность данных при отказах отдельных узлов.
Роль мастера в управлении узлами и распределении задач

Мастер – центральный узел, через который проходят все операции изменения состояния системы. Он принимает запросы на запись, присваивает транзакциям последовательные идентификаторы и формирует журналы изменений, по которым слейвы синхронизируют свои копии данных. Любая потеря порядка операций на этом этапе приводит к рассинхронизации, поэтому на мастере обязательно включают бинарное или WAL-логирование и контроль целостности журналов.
В задачи мастера входит учёт доступных слейвов и распределение потоков чтения. Он хранит метаданные о задержке репликации, состоянии сетевых соединений и объёме обработанных журналов. Эти данные используются балансировщиками для исключения узлов с превышенным replication lag и перенаправления запросов на актуальные реплики.
Мастер управляет жизненным циклом узлов: регистрирует новые реплики, инициирует первичную синхронизацию, запускает повторное копирование данных при сбоях и передаёт параметры конфигурации. Для этого применяются служебные каналы управления, отличные от каналов передачи пользовательских данных, чтобы нагрузка от администрирования не влияла на операции записи.
При проектировании кластера рекомендуется выделять для мастера отдельный сервер с приоритетом по ресурсам процессора и дисковой подсистемы, настраивать резервное копирование журналов в реальном времени и включать мониторинг задержек. Эти меры позволяют сохранить управляемость кластера и предотвратить накопление несогласованных данных на подчинённых узлах.
Функции слейва при обработке и хранении данных

Слейв – узел, предназначенный для приёма журналов изменений от мастера и воспроизведения операций в строгой последовательности. Он не принимает прямые операции записи, а применяет только те транзакции, которые поступили по каналу репликации. Для этого на слейве настраиваются отдельные потоки чтения журналов и рабочие процессы применения, что позволяет параллелить обновления и удерживать задержку в заданных пределах.
Основная нагрузка слейва связана с обслуживанием запросов чтения. Отчётные выборки, аналитические расчёты и экспорт данных направляются именно на эти узлы. Чтобы избежать влияния тяжёлых запросов на скорость синхронизации, практикуется ограничение ресурсов по процессору и памяти для пользовательских сессий и выделение приоритета процессам репликации.
Слейв выполняет роль дополнительного хранилища копий данных. Его дисковая подсистема должна быть рассчитана на постоянное последовательное чтение журналов и параллельную запись обновлений. Для ускорения восстановления после сбоя настраивается периодическая проверка контрольных сумм и автоматический перезапуск репликации при потере соединения.
При эксплуатации рекомендуется задавать пороги допустимой задержки, после которых слейв временно исключается из пула чтения, и использовать мониторинг объёма неприменённых журналов. Эти меры позволяют поддерживать согласованность данных и не допускать возврата пользователям устаревших результатов.
Схема обмена сообщениями между мастером и слейвами
Обмен данными строится на постоянном двустороннем соединении, где мастер выступает источником потоков изменений, а слейвы – их потребителями. После установления соединения слейв передаёт мастеру последнюю применённую позицию журнала транзакций. На основе этого значения мастер начинает передачу только новых записей, что исключает повторную обработку уже синхронизированных операций.
Пакеты с журналами отправляются последовательно, с сохранением точного порядка транзакций. Каждое сообщение содержит смещение в журнале, контрольную сумму и маркер завершения транзакции. Слейв проверяет целостность пакета, записывает его в локальный буфер и только после успешной валидации применяет изменения к своей копии данных.
В обратном направлении слейвы регулярно отправляют служебные ответы с информацией о текущем смещении, объёме неприменённых записей и времени последнего подтверждения. Эти данные используются мастером и системами мониторинга для вычисления replication lag и принятия решений об исключении узла из обслуживания запросов чтения.
Для повышения устойчивости рекомендуется разделять каналы пользовательских запросов и репликации, включать шифрование служебных соединений и задавать тайм-ауты подтверждений. При превышении тайм-аута мастер помечает слейв как недоступный и приостанавливает передачу данных до восстановления стабильного канала связи.
Как происходит переключение на резервного мастера при сбое
Переключение на резервного мастера начинается с обнаружения недоступности текущего мастера. Для этого настраиваются регулярные проверки состояния узла по тайм-аутам соединения и объёму неприменённых журналов на слейвах. Если мастер не отвечает или отставание реплик превышает допустимый порог, система инициирует процесс failover.
Выбор нового мастера осуществляется на основе актуальности данных: слейв с минимальной задержкой репликации и полной синхронизацией получает приоритет. Для этого на слейвах поддерживаются метаданные о последней применённой позиции журнала и времени последнего подтверждения транзакций.
После выбора резервного мастера выполняются следующие действия:
- Поднятие слейва в режим мастера с включением возможности записи.
- Перенастройка остальных слейвов на получение изменений от нового мастера.
- Обновление конфигураций подключений приложений и балансировщиков на новый мастер.
- Включение мониторинга задержек и контроль целостности журналов для нового мастера.
Для ускорения восстановления рекомендуется использовать автоматизированные инструменты failover, предварительно протестированные на идентичных стендовых кластерах. Дополнительно важно ограничить одновременные операции записи на старых слейвах до завершения переключения, чтобы избежать конфликтов данных и рассинхронизации.
Применение master-slave в базах данных MySQL и PostgreSQL
В MySQL и PostgreSQL master-slave репликация используется для разгрузки мастера, ускорения чтения и повышения отказоустойчивости. Мастер принимает все операции записи, ведёт бинарные или WAL-журналы, а слейвы синхронизируют свои копии, применяя изменения с минимальной задержкой.
В MySQL настройка репликации включает включение binary log, создание пользователя репликации и настройку server-id для каждого узла. В PostgreSQL используется WAL-логирование, параметр primary_conninfo на слейвах и контроль состояния репликации через системные представления pg_stat_replication.
Для выбора узла, на который направлять операции чтения, часто применяются балансировщики и специальные метрики lag. При проектировании кластера важно задавать ограничения на максимальную задержку реплик и проверять контрольные суммы данных на всех узлах.
| Параметр | MySQL | PostgreSQL |
|---|---|---|
| Тип журнала | Binary log | WAL |
| Идентификатор узла | server-id | Системный ID слейва |
| Пользователь для репликации | Только чтение binary log | Указанный в primary_conninfo |
| Мониторинг задержки | SHOW SLAVE STATUS | pg_stat_replication |
| Автоматическое переключение мастера | Сторонние инструменты (MHA, Orchestrator) | Patroni, repmgr |
Использование master-slave в этих СУБД позволяет масштабировать чтение, уменьшить нагрузку на основной сервер и обеспечить быстрый отклик приложений при пиковых нагрузках, при условии правильной настройки репликации и мониторинга узлов.
Ограничения записи и чтения в системах с master-slave
В архитектуре master-slave запись разрешена только на мастер. Любая попытка напрямую изменить данные на слейве приводит к рассинхронизации и потере целостности. Поэтому на слейвах включают режим только для чтения, а административные операции должны выполняться через мастера или с временным снятием ограничений под контролем администратора.
Чтение в таких системах допускается как на мастере, так и на слейвах, но нагрузку рекомендуется распределять преимущественно на слейвы. Это снижает задержку обработки транзакций и уменьшает риск блокировок. Для этого используют балансировщики запросов и маршрутизацию на основе метрик replication lag, исключая узлы с критическим отставанием.
Необходимо учитывать, что слейвы могут иметь небольшую задержку по сравнению с мастером. Запросы, требующие актуальных данных для критических операций, должны выполняться только на мастере. Для аналитических и отчётных задач слейвы подходят лучше, но при превышении допустимого lag их следует временно исключать из пула чтения.
Рекомендации по эксплуатации включают мониторинг задержки репликации, настройку автоматического исключения отставших слейвов, ограничение ресурсов для операций чтения и регулярную проверку целостности данных между мастером и слейвами. Эти меры предотвращают появление рассинхронизированных или устаревших данных в приложениях.
Типовые ошибки конфигурации и способы их обнаружения
Другой распространённый сбой – неправильная инициализация слейва. Если слейв стартует с несогласованной копией данных или без указания позиции журнала, он либо не применяет новые транзакции, либо создаёт конфликт. Проверка контрольных сумм и сравнение состояния таблиц между мастером и слейвом позволяет обнаружить рассинхронизацию.
Неправильные настройки сетевых тайм-аутов и буферов также приводят к разрывам репликации и накоплению неприменённых транзакций. Для выявления проблемы используют мониторинг replication lag и отчёты о состоянии соединения с мастером.
Часто встречается превышение прав пользователя репликации: если узел получает больше привилегий, чем требуется, это создаёт риск случайной записи на слейве. Обнаруживается через аудит пользователей и проверку прав на выполнение DML-команд.
Для предотвращения ошибок рекомендуется вести журнал изменений конфигурации, настраивать автоматический контроль задержки и целостности данных, а также проводить регулярное тестирование failover на тестовом кластере. Это позволяет выявить сбои до их влияния на рабочую систему и обеспечить стабильную работу архитектуры master-slave.
Вопрос-ответ:
Что делает мастер в системе master-slave и почему все записи проходят через него?
Мастер контролирует порядок выполнения операций записи и создаёт журналы изменений, которые слейвы получают для синхронизации. Все изменения данных проходят через него, чтобы сохранить согласованность между узлами и избежать конфликтов при параллельной работе нескольких слейвов. Если запись производилась бы на слейвы напрямую, данные могли бы рассинхронизироваться и потерять правильный порядок транзакций.
Как слейвы обрабатывают данные и чем они отличаются от мастера?
Слейвы получают журнал изменений от мастера и применяют эти операции к своей копии базы. Они не принимают прямые записи от приложений. Основная их задача — обслуживать запросы на чтение и хранить актуальные копии данных. Это разгружает мастер, снижает нагрузку на основной узел и позволяет масштабировать чтение для большого числа пользователей без риска изменения исходных данных.
Что такое задержка репликации и как она влияет на работу системы?
Задержка репликации — это разница во времени между моментом, когда мастер применяет транзакцию, и моментом, когда слейв её воспроизводит. Большая задержка может привести к тому, что запросы чтения на слейвах будут получать устаревшие данные. Для контроля используют метрики lag и исключают узлы с превышением допустимого времени из пула чтения, чтобы приложения всегда получали актуальные результаты.
Какие ошибки чаще всего возникают при настройке репликации master-slave?
Типичные ошибки включают одинаковые идентификаторы узлов на мастере и слейвах, неправильную инициализацию слейва с несогласованной копией данных, превышение прав пользователя репликации и некорректные тайм-ауты сетевых соединений. Эти проблемы проявляются в разрывах репликации, накоплении неприменённых транзакций или рассинхронизации данных. Выявить их помогают логи, команды контроля состояния и проверка контрольных сумм между узлами.
Как происходит переключение на резервного мастера при сбое и что нужно учесть?
При сбое текущего мастера система выбирает слейв с минимальной задержкой и полной синхронизацией, который становится новым мастером. Остальные слейвы перенастраиваются на него. При этом важно ограничить одновременные записи на старых слейвах до завершения переключения, чтобы не возникли конфликты данных. Автоматизированные инструменты failover помогают ускорить процесс и снизить вероятность ошибок.
Можно ли направлять операции записи на слейвы в системе master-slave?
Нет, запись на слейвы запрещена, так как это нарушает последовательность транзакций и может вызвать рассинхронизацию данных. Все изменения должны проходить через мастер, который формирует журнал транзакций для синхронизации слейвов. Исключения возможны только при аварийной ситуации, когда слейв временно становится мастером после failover, но это требует контроля целостности данных и перенастройки остальных узлов.
Как контролировать актуальность данных на слейвах и не допустить использования устаревшей информации?
Для контроля актуальности на слейвах отслеживают replication lag — задержку между применением транзакций мастером и их воспроизведением на слейве. Если задержка превышает заданный порог, узел временно исключают из пула чтения. Дополнительно используют проверку контрольных сумм данных и мониторинг объёма неприменённых транзакций. Эти меры позволяют направлять запросы на слейвы только тогда, когда их данные синхронизированы с мастером.