Содержание статьи

При разработке проектов на Python ключевым фактором становится правильный выбор базы данных. Выбор напрямую зависит от объема и структуры данных: для приложений с таблицами фиксированной структуры оптимальны реляционные СУБД, такие как PostgreSQL или MySQL, тогда как для хранения документов, JSON-структур или событий лучше подходят NoSQL решения, например MongoDB или Redis.
Для небольших проектов или прототипов SQLite предлагает минимальные настройки и встроенную поддержку в стандартной библиотеке Python, что снижает время запуска и упрощает тестирование. В средних и крупных приложениях PostgreSQL обеспечивает надежные механизмы транзакций, поддержку индексов GIN и JSONB, а также удобные инструменты масштабирования через репликацию.
NoSQL базы данных особенно полезны, когда требуется высокая скорость чтения и записи, горизонтальное масштабирование и хранение полуструктурированных данных. MongoDB позволяет использовать Python-библиотеку PyMongo для работы с коллекциями документов, а Redis подходит для кэширования, очередей задач и хранения временных данных с низкой задержкой.
Использование ORM, таких как SQLAlchemy или Django ORM, упрощает взаимодействие с различными СУБД, но требует внимательного подхода к производительности: сложные запросы или массовые вставки данных могут потребовать оптимизации через нативные SQL-запросы или индексирование. При выборе базы данных важно заранее оценивать ожидаемую нагрузку, объем данных и требования к резервному копированию.
Как определить требования к данным перед выбором СУБД

Определение требований к данным – ключевой шаг перед выбором базы данных для Python-проекта. Это позволяет выбрать СУБД с нужными характеристиками и избежать проблем с производительностью и масштабированием.
Основные аспекты анализа данных:
- Структура данных: фиксированные таблицы указывают на реляционные СУБД, JSON и документ-ориентированные данные – на NoSQL.
- Объем и рост данных: прогнозируйте размер базы на 1–3 года. SQLite подходит до 10 ГБ, PostgreSQL и MySQL справятся с сотнями гигабайт, масштабируемые NoSQL решения – для терабайт данных.
- Частота операций: высокая интенсивность чтения и записи требует in-memory решений, таких как Redis, или распределенных NoSQL баз.
- Транзакции и консистентность: ACID критичны для финансовых и критичных систем. Eventual consistency допустима для аналитики и кэшей.
- Запросы и фильтрация: сложные JOIN и агрегаты лучше выполнять в реляционных базах, полнотекстовый поиск и гибкие индексы – в NoSQL.
- Масштабируемость: оцените горизонтальное расширение. MongoDB и PostgreSQL с репликацией позволяют увеличить нагрузку без полной миграции данных.
- Резервное копирование и восстановление: определите частоту бэкапов и допустимое время восстановления. NoSQL часто предоставляет моментальные снимки, реляционные базы – через WAL и репликацию.
Анализ этих параметров позволяет выбрать СУБД, соответствующую конкретным потребностям проекта на Python, с оптимальной производительностью и готовностью к росту данных.
Сравнение реляционных баз данных для Python-проектов
Для Python-проектов чаще всего рассматриваются PostgreSQL, MySQL и SQLite. Выбор зависит от объема данных, требований к транзакциям и необходимости масштабирования.
Основные характеристики и различия:
| СУБД | Максимальный объем данных | Поддержка транзакций ACID | Особенности для Python | Типичный сценарий использования |
|---|---|---|---|---|
| PostgreSQL | До нескольких ТБ на одном сервере, поддержка шардирования | Полная | Библиотеки psycopg2, asyncpg; поддержка JSONB, индексы GIN | Сложные приложения, аналитика, веб-сервисы с большим количеством данных |
| MySQL | Десятки ТБ при правильной настройке | ACID через InnoDB | Библиотеки mysql-connector-python, PyMySQL; ограниченная поддержка JSON | Веб-приложения с умеренной нагрузкой, прототипы, сайты |
| SQLite | До 140 ТБ, но производительность падает выше 10–20 ГБ | Полная, но только локальная | Встроенная в стандартную библиотеку Python, нет сетевой поддержки | Малые проекты, тестирование, мобильные приложения |
PostgreSQL предпочтителен для проектов с аналитикой и сложными связями между таблицами. MySQL подходит для классических веб-приложений с умеренной нагрузкой. SQLite идеален для прототипов и локальных приложений без высоких требований к масштабированию и одновременным подключениям.
Когда использовать NoSQL базы данных в Python-приложениях
NoSQL базы данных применяются в Python-проектах, когда традиционные реляционные СУБД не обеспечивают нужной гибкости или производительности. Основные сценарии использования:
- Хранение полуструктурированных данных: документы JSON, XML или динамические схемы лучше сохранять в MongoDB, CouchDB или Firestore, так как реляционные таблицы потребуют частых изменений схем.
- Высокая частота операций записи и чтения: Redis, Cassandra и Aerospike позволяют обрабатывать десятки тысяч операций в секунду благодаря хранению данных в памяти или распределенной архитектуре.
- Горизонтальное масштабирование: если проект растет по числу пользователей и объему данных, NoSQL базы с шардированием, как MongoDB и Cassandra, упрощают распределение нагрузки без сложной миграции.
- Кэширование и очереди задач: Redis и RabbitMQ используются для временного хранения с быстрым доступом, снижают нагрузку на основную СУБД и ускоряют обработку фоновых задач.
- Аналитика больших данных: базы типа Cassandra и HBase эффективны для хранения временных рядов и больших массивов событий, обеспечивая быстрый агрегационный доступ без сложных JOIN.
Для Python-проектов интеграция с NoSQL базами осуществляется через специализированные библиотеки: PyMongo для MongoDB, redis-py для Redis и cassandra-driver для Cassandra. Выбор конкретной базы зависит от структуры данных, требуемой скорости доступа и возможности масштабирования без простоев.
Особенности работы с SQLite для небольших проектов
SQLite подходит для небольших Python-проектов благодаря минимальной настройке и встроенной поддержке в стандартной библиотеке. База хранится в одном файле, что упрощает перенос и резервное копирование данных.
Основные характеристики и рекомендации при работе с SQLite:
1. Ограничение объема данных: производительность начинает снижаться при размерах файла более 10–20 ГБ. Для проектов с большим количеством записей лучше рассматривать PostgreSQL или MySQL.
2. Поддержка транзакций: SQLite полностью поддерживает ACID, что позволяет безопасно выполнять множественные операции INSERT, UPDATE и DELETE даже при аварийном завершении приложения.
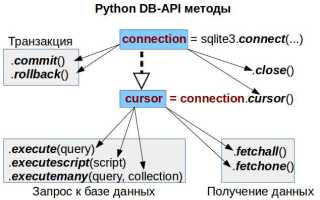
3. Совместимость с Python: встроенный модуль sqlite3 обеспечивает синхронный доступ к базе без дополнительных библиотек. Для асинхронного доступа можно использовать aiosqlite.
4. Ограничения многопользовательского доступа: SQLite поддерживает несколько процессов на чтение, но только один на запись. Для одновременных операций записи рекомендуется использовать серверные СУБД.
5. Индексы и оптимизация запросов: для ускорения поиска данных используйте CREATE INDEX на полях с частыми фильтрациями. Без индексов SELECT-запросы на больших таблицах замедляются.
SQLite эффективен для прототипов, локальных утилит, мобильных приложений и небольших веб-проектов, где нет высокой нагрузки на запись и нет необходимости в сложной архитектуре масштабирования.
Интеграция PostgreSQL с Python: что важно учитывать

PostgreSQL предоставляет расширенные возможности для хранения и обработки данных, но эффективная интеграция с Python требует внимания к ряду технических аспектов.
1. Выбор библиотеки для подключения: psycopg2 – стандартная синхронная библиотека, поддерживающая полный функционал PostgreSQL. Для асинхронных приложений подходят asyncpg и databases.
2. Работа с транзакциями: PostgreSQL обеспечивает полную поддержку ACID. При использовании Python важно контролировать открытые транзакции, чтобы избежать блокировок и утечек соединений.
3. Типы данных и JSONB: PostgreSQL поддерживает сложные типы данных, включая массивы, JSON и JSONB. Для хранения структурированных данных, которые часто меняются, JSONB обеспечивает быстрый поиск и индексацию внутри документов.
4. Индексы и производительность: используйте индексы GIN для поиска по JSONB, B-tree для стандартных полей и BRIN для больших временных рядов. Неоптимизированные индексы замедляют вставку и обновление данных.
5. Масштабирование и репликация: для увеличения нагрузки стоит использовать потоковую репликацию или Pgpool-II. Python-приложение должно корректно распределять запросы на чтение между репликами.
6. Поддержка ORM: SQLAlchemy и Django ORM упрощают работу с PostgreSQL, но для сложных операций стоит использовать нативные SQL-запросы, чтобы избежать избыточных JOIN и медленных агрегатов.
Соблюдение этих рекомендаций позволяет использовать PostgreSQL в Python-проектах с высокой нагрузкой, сложными структурами данных и требованиями к надежности хранения информации.
Выбор между MongoDB и Redis для хранения нестандартных данных
При хранении нестандартных данных в Python-проектах важно учитывать структуру, объем и скорость доступа к данным. MongoDB и Redis решают разные задачи, несмотря на общую категорию NoSQL.
MongoDB подходит для документов с динамическими схемами, JSON-подобных структур и вложенных объектов. Использование PyMongo позволяет эффективно выполнять запросы с фильтрацией, агрегацией и индексированием полей JSON. MongoDB подходит для приложений с аналитикой, контент-менеджментом и гибкой структурой данных, где важна долговременная сохранность и масштабирование.
Redis ориентирован на быстрый доступ к данным в памяти. Он идеально подходит для кэширования, очередей задач, хранения сессий и временных данных. Библиотека redis-py обеспечивает простую интеграцию с Python и работу с различными структурами данных: строки, списки, множества, хэш-таблицы и отсортированные множества. Redis эффективен для задач с высокой частотой чтения и записи, но не предназначен для долговременного хранения больших объемов данных без резервного копирования.
Выбор между MongoDB и Redis зависит от цели хранения: если требуется гибкая долговременная база документов – MongoDB, если критична скорость доступа и временные данные – Redis. В крупных Python-приложениях часто используют комбинацию: MongoDB для основной информации и Redis для кэша и быстрого доступа к активно используемым данным.
Инструменты ORM для Python и их влияние на производительность

ORM (Object-Relational Mapping) упрощает работу с базами данных в Python, но может оказывать существенное влияние на производительность при неправильном использовании.
SQLAlchemy обеспечивает гибкую работу с реляционными базами, поддерживает как синхронный, так и асинхронный режимы через asyncpg. Преимущество – контроль над SQL-запросами, риск – неэффективные JOIN и массовые операции могут замедлять вставку и выборку данных.
Django ORM интегрирован в веб-фреймворк и автоматизирует создание моделей и миграций. Он упрощает разработку CRUD-функционала, но при сложных запросах с множеством связанных таблиц генерирует большое количество SQL-запросов, что повышает нагрузку на базу.
Peewee легковесный ORM, оптимизированный для небольших и средних проектов. Он быстрее Django ORM в простых запросах, но ограничен функционалом для сложных агрегатов и масштабируемых схем.
Для снижения влияния ORM на производительность рекомендуется:
- Использовать select_related или joinedload для объединения связанных таблиц за один запрос.
- Применять пакетную вставку (bulk insert) вместо одиночных INSERT для больших объемов данных.
- Контролировать индексы на часто фильтруемых полях, чтобы ускорить SELECT-запросы.
- При сложных аналитических запросах использовать нативный SQL вместо автоматической генерации ORM.
Правильное сочетание ORM и ручной оптимизации запросов позволяет поддерживать удобство разработки без потери производительности в Python-проектах.
Как масштабируемость и нагрузка влияют на выбор СУБД
При выборе СУБД для Python-проекта важно учитывать ожидаемую нагрузку и возможности масштабирования. Неправильный выбор может привести к замедлению работы приложения или сложной миграции в будущем.
Ключевые параметры для оценки:
| СУБД | Горизонтальное масштабирование | Вертикальное масштабирование | Поддержка высокой нагрузки | Примеры применения |
|---|---|---|---|---|
| PostgreSQL | Через шардирование или сторонние инструменты (Citus, Pgpool-II) | Увеличение CPU, RAM, SSD на сервере | Высокая, при правильной настройке индексов и репликации | Веб-сервисы, аналитические платформы, финансовые системы |
| MySQL | Реализация шардирования вручную или через MySQL Cluster | Увеличение ресурсов сервера | Средняя, эффективно при оптимизации запросов и кэшировании | Сайты, приложения с умеренным объемом данных |
| MongoDB | Встроенное шардирование, легко масштабируется горизонтально | Увеличение ресурсов отдельных нод | Высокая, оптимально для полуструктурированных данных и больших коллекций | Документоориентированные приложения, аналитика событий |
| Redis | Кластеризация и репликация нод | Увеличение памяти и CPU для ноды | Очень высокая, подходит для кэша и очередей задач | Сессии пользователей, временные данные, очереди сообщений |
При высокой нагрузке критично учитывать не только объем данных, но и количество одновременных подключений, частоту операций записи и чтения. Для Python-проектов комбинация реляционной базы с кэшированием в Redis позволяет распределить нагрузку и обеспечить быстрый отклик приложения.
Вопрос-ответ:
Как выбрать между реляционной и NoSQL базой для проекта на Python?
Решение зависит от структуры и объема данных. Если данные имеют фиксированные поля и сложные связи между таблицами, стоит использовать реляционную СУБД, например PostgreSQL или MySQL. Если структура данных часто меняется, нужны документы JSON или массивы событий, тогда MongoDB или Redis будут предпочтительнее. Также важно учитывать частоту чтения и записи: при высоких нагрузках и кэшировании Redis может значительно ускорить обработку запросов.
Можно ли использовать SQLite для веб-приложения с несколькими сотнями пользователей?
SQLite хранит данные в одном файле и поддерживает несколько процессов на чтение, но только один на запись. Для небольшого трафика или прототипа это допустимо, но при сотнях одновременных пользователей записи будут блокироваться. Для таких случаев лучше использовать PostgreSQL или MySQL с серверной архитектурой, чтобы избежать задержек и конфликтов транзакций.
Влияет ли использование ORM на скорость работы с базой в Python?
Да, ORM упрощает разработку, но добавляет уровень абстракции, который может замедлять операции, особенно при сложных JOIN или массовых вставках. SQLAlchemy и Django ORM удобны для CRUD-операций, но для сложных выборок стоит использовать нативные SQL-запросы или пакетную обработку данных. Также помогает создание индексов на полях, которые часто фильтруются.
Когда имеет смысл использовать Redis вместо MongoDB для хранения данных?
Redis лучше подходит для временных данных, кэша, очередей задач и хранения сессий пользователей благодаря хранению данных в памяти и низкой задержке. MongoDB применим для долговременного хранения документов с динамической структурой. В проектах с Python часто используют комбинацию: MongoDB для основной информации и Redis для быстрого доступа к активно используемым данным.
Какие факторы влияют на выбор базы при высокой нагрузке и масштабировании?
Необходимо учитывать частоту операций чтения и записи, количество одновременных подключений, размер данных и возможность горизонтального расширения. PostgreSQL и MySQL хорошо работают при вертикальном масштабировании, а MongoDB и Redis позволяют распределять нагрузку между несколькими нодами. Также имеет значение поддержка репликации и механизмов резервного копирования, чтобы избежать простоев и потери данных.
Какие базы данных лучше подходят для проектов с динамическими данными в Python?
Для данных с изменяющейся структурой или вложенными JSON-документами лучше подходят NoSQL базы. MongoDB позволяет хранить документы с разной схемой и выполнять фильтрацию и агрегацию внутри коллекций. Redis подходит для быстрого доступа к часто используемым данным, кэшу и временным объектам. Выбор зависит от того, нужно ли долговременное хранение информации или быстрый отклик приложения.
Как оценить нагрузку на базу данных при проектировании Python-приложения?
Следует учитывать объем данных, частоту операций чтения и записи, количество одновременных пользователей и сложность запросов. Для небольших проектов можно использовать SQLite, но при росте числа пользователей и объема данных стоит выбирать серверные СУБД с поддержкой репликации и масштабирования. Также важно предусмотреть индексы и кэширование, чтобы снизить задержки при выборках и обновлениях.