Содержание статьи

SQL Server 2019 предоставляет расширенные возможности управления данными, включая поддержку больших объемов информации, встроенные инструменты для интеграции с Python и R, а также оптимизированные механизмы хранения для NVMe и SSD. Этот гид поможет быстро развернуть сервер, настроить экземпляр и подготовить рабочее окружение для обработки данных с минимальными рисками.
Мы рассмотрим практические шаги по созданию и настройке баз данных, управлению пользователями и правами доступа, а также по работе с T-SQL для выборки, обновления и анализа данных. Особое внимание уделено инструментам импорта и экспорта, что позволяет быстро перенести данные между SQL Server, Excel и другими источниками без потери целостности.
В руководстве описаны методы организации индексов для ускорения запросов, настройки резервного копирования и восстановления, а также рекомендации по мониторингу производительности через встроенные средства SQL Server. Каждая инструкция сопровождается конкретными примерами команд и последовательностью действий, чтобы даже пользователь с минимальным опытом мог выполнить операции без ошибок.
Следуя этому пошаговому подходу, вы сможете не только развернуть рабочий SQL Server 2019, но и поддерживать базы данных в актуальном состоянии, обеспечивать безопасность и целостность данных, а также оптимизировать запросы для повышения скорости обработки информации.
Установка SQL Server 2019 и настройка базового экземпляра
Скачайте установочный пакет SQL Server 2019 с официального сайта Microsoft, выбрав версию Developer или Standard в зависимости от задач. Для установки на Windows Server 2019 или Windows 10 рекомендуется использовать режим «Basic» для быстрого развёртывания или «Custom» для точной настройки компонентов.
Запустите установщик и выберите «New SQL Server stand-alone installation». На этапе проверки системы убедитесь, что установлены .NET Framework 4.8 и последние обновления безопасности Windows. Установщик автоматически проверит наличие необходимых библиотек и служб.
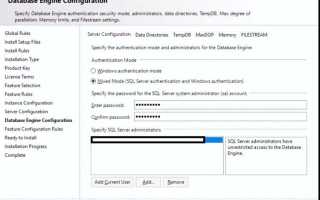
При выборе типа экземпляра оставьте «Default» для базовой установки или создайте «Named Instance», если планируется несколько экземпляров на одном сервере. Для производственных серверов рекомендуется включить режим Mixed Mode и задать сложный пароль для учетной записи sa.
На этапе выбора компонентов отметьте Database Engine Services, SQL Server Replication и Full-Text Search. Для минимизации проблем с производительностью укажите отдельный диск для файлов данных (.mdf) и журналов транзакций (.ldf). Размер начального файла данных лучше установить на 10 ГБ с автоприращением по 1 ГБ, журналов транзакций – 2 ГБ с приростом по 512 МБ.
После завершения установки откройте SQL Server Management Studio и подключитесь к экземпляру. Проверьте работу служб SQL Server и SQL Server Agent, а также корректность настроек сети через TCP/IP. Включите протокол TCP в SQL Server Configuration Manager и установите статический порт, чтобы обеспечить стабильное подключение клиентов.
Создание и управление базами данных через SQL Server Management Studio
Откройте SQL Server Management Studio (SSMS) и подключитесь к нужному экземпляру SQL Server 2019. Для создания новой базы данных используйте контекстное меню на узле «Databases» или выполните T-SQL команду CREATE DATABASE.
Рекомендуется придерживаться следующих настроек при создании базы данных:
- Укажите имя базы данных, которое отражает содержание данных.
- Для файлов данных (.mdf) выберите отдельный диск с минимальным размером 10 ГБ и приростом 1 ГБ.
- Для журналов транзакций (.ldf) используйте отдельный диск, размер 2 ГБ с приростом 512 МБ.
- Включите опцию «Auto Shrink» только для тестовых баз, на производственных серверах её лучше отключить.
- Настройте колlation в соответствии с требованиями приложений, чаще всего SQL_Latin1_General_CP1_CI_AS.
Для управления базой данных через SSMS выполняйте следующие действия:
- Используйте «Properties» базы данных для изменения файлов, настроек совместимости и recovery model.
- Настройте роли и пользователей через узел «Security» внутри базы данных, назначая только необходимые права.
- Регулярно проверяйте состояние базы через «Tasks» → «Check Database Integrity» для предотвращения повреждений данных.
- Используйте «Tasks» → «Shrink» или «Export Data» для оптимизации или перемещения данных между серверами.
- Создавайте схемы и таблицы через SSMS или T-SQL, соблюдая принципы нормализации и индексации для ускорения запросов.
Для баз данных с высокой нагрузкой рекомендуется включить опцию «Auto Close» только для тестовых экземпляров и использовать «Recovery Model: Full» при необходимости точного восстановления данных. SSMS позволяет комбинировать графический интерфейс и T-SQL, что упрощает как разовую настройку, так и регулярное администрирование баз.
Настройка пользователей, ролей и прав доступа
Для управления доступом в SQL Server 2019 используйте SQL Server Management Studio (SSMS) и раздел «Security» на уровне сервера и баз данных. Создавайте учетные записи пользователей через «Logins», задавая тип аутентификации: Windows Authentication для интеграции с AD или SQL Server Authentication с надежным паролем.
Рекомендуется следовать таким шагам для настройки прав доступа:
- Создайте логины на сервере и сопоставьте их с пользователями внутри каждой базы данных через «User Mapping».
- Используйте предопределенные роли сервера (sysadmin, serveradmin, securityadmin) и базы данных (db_owner, db_datareader, db_datawriter) вместо назначения отдельных разрешений, чтобы упростить администрирование.
- Назначайте права минимально необходимыми для выполнения задач пользователя, например, роль db_datareader позволяет только чтение данных, а db_datawriter – только запись.
- Для специальных операций создавайте кастомные роли с набором нужных разрешений через T-SQL команду CREATE ROLE и GRANT.
- Регулярно проверяйте и удаляйте неиспользуемые логины и пользователей, чтобы снизить риск несанкционированного доступа.
Для обеспечения безопасности рекомендуется включить проверку сложности паролей, настроить периодическую смену паролей и аудит действий через SQL Server Audit. Также полезно ограничить доступ по IP и использовать схемы внутри баз данных для разграничения таблиц и процедур между ролями.
Импорт и экспорт данных с помощью встроенных инструментов
SQL Server 2019 включает инструменты для импорта и экспорта данных, которые позволяют переносить информацию между базами, файлами Excel, CSV и другими источниками без стороннего ПО. Основные инструменты – SQL Server Management Studio (SSMS) и SQL Server Import and Export Wizard.
Для импорта данных используйте следующие шаги:
- Откройте SSMS, выберите базу данных, кликните правой кнопкой на «Tasks» → «Import Data».
- Выберите источник данных (Excel, CSV, OLE DB, ODBC) и убедитесь, что выбран правильный тип файла и кодировка.
- Настройте сопоставление столбцов источника и таблицы назначения, включая преобразование типов данных при необходимости.
- Включите проверку на дубликаты и обработку ошибок: пропускать строки с ошибками или записывать их в лог.
- Запустите процесс и проверьте количество вставленных записей через SELECT COUNT(*) в целевой таблице.
Для экспорта данных действуйте аналогично через «Tasks» → «Export Data»:
- Выберите таблицу или результат запроса для экспорта.
- Настройте формат и расположение файла назначения.
- При необходимости включите фильтры и сортировку прямо в мастере.
- Проверяйте итоговые файлы на соответствие типам данных и кодировке.
Для регулярной миграции данных рекомендуется использовать Integration Services (SSIS), создавая пакеты с автоматическим расписанием. При больших объемах данных включайте пакетную загрузку (batch) и отключайте индексы на время импорта, чтобы ускорить процесс и снизить нагрузку на сервер.
Написание и выполнение запросов T-SQL для выборки и обновления данных

Для работы с данными в SQL Server 2019 используется язык T-SQL. Начните с базовых SELECT-запросов для выборки данных из таблиц и представлений. Для ускорения разработки используйте фильтры WHERE и сортировку ORDER BY, ограничивая выборку через TOP или OFFSET-FETCH для больших таблиц.
Примеры эффективных операций выборки и обновления:
| Операция | Пример | Рекомендации |
|---|---|---|
| Выборка с фильтром | SELECT CustomerID, Name FROM Customers WHERE Country=’Russia’; | Использовать индексы по столбцам в WHERE для ускорения выборки. |
| Обновление данных | UPDATE Orders SET Status=’Shipped’ WHERE OrderDate < '2025-01-01'; | Перед UPDATE выполнять SELECT с тем же условием, чтобы проверить количество строк. |
| Добавление данных | INSERT INTO Products (Name, Price) VALUES (‘Keyboard’, 2500); | Проверять уникальные ключи и ограничения перед вставкой. |
| Удаление данных | DELETE FROM Logs WHERE LogDate < '2024-01-01'; | Рекомендуется делать резервное копирование или использовать транзакцию BEGIN TRANSACTION / ROLLBACK. |
| Агрегатные функции | SELECT COUNT(*), AVG(Price) FROM Products WHERE Category=’Electronics’; | Использовать GROUP BY и HAVING для анализа больших наборов данных. |
Для сложных сценариев применяйте подзапросы, JOIN и CTE (Common Table Expressions), что позволяет объединять таблицы, создавать промежуточные результаты и упрощать обновления больших наборов данных. Всегда проверяйте синтаксис и используйте транзакции при массовых изменениях для сохранения целостности базы.
Создание и управление индексами для ускорения запросов

Для повышения производительности запросов в SQL Server 2019 используют индексы. Основные типы индексов – кластерные и некластерные. Кластерный индекс определяет физический порядок строк в таблице и рекомендуется создавать на столбце с уникальными идентификаторами, например, PRIMARY KEY. Некластерные индексы ускоряют поиск по часто используемым столбцам без изменения физического порядка данных.
При создании индексов следует учитывать следующие рекомендации:
- Создавайте индекс на колонках, которые часто используются в фильтрах WHERE, JOIN и ORDER BY.
- Для больших таблиц используйте INCLUDE в некластерных индексах, добавляя дополнительные столбцы для покрытия запросов без добавочного чтения таблицы.
- Избегайте создания индексов на колонках с низкой селективностью, таких как булевы значения или категории с малым числом уникальных значений.
- Регулярно выполняйте REBUILD или REORGANIZE индексов для уменьшения фрагментации, особенно после массовых вставок или обновлений.
- Используйте динамическую DMV sys.dm_db_index_usage_stats для анализа использования индексов и удаления неэффективных.
Для создания индекса через T-SQL используйте команду CREATE INDEX с указанием столбцов и типа индекса. При больших объемах данных включайте параметр ONLINE=ON для минимизации блокировок. Некластерные уникальные индексы рекомендуется применять для контроля дублирующихся значений без влияния на основную структуру таблицы.
Оптимальное использование индексов снижает время выполнения выборок и соединений на десятки процентов, особенно на таблицах с миллионами строк, и позволяет SQL Server эффективно использовать ресурсы памяти и процессора при выполнении сложных запросов.
Резервное копирование и восстановление баз данных
В SQL Server 2019 резервное копирование выполняется через SSMS или T-SQL и включает полные, дифференциальные и журнальные копии. Полное резервное копирование сохраняет всю базу, дифференциальное – только изменения с момента последнего полного, а журнальное – транзакции для точечного восстановления.
Рекомендуется следующая стратегия резервного копирования:
- Создавать полное резервное копирование раз в сутки для основных баз данных.
- Дифференциальные копии делать каждые 4–6 часов для сокращения времени восстановления.
- Журнальные копии выполнять каждые 15–30 минут для критичных транзакций.
- Хранить копии на отдельном физическом носителе или в облачном хранилище для защиты от сбоев оборудования.
Для восстановления базы используйте SSMS или команду RESTORE DATABASE. Восстановление можно выполнять полностью или до определенного момента времени с помощью журнала транзакций. Перед восстановлением рекомендуется установить базу в режим SINGLE_USER, чтобы исключить доступ других процессов.
Регулярно проверяйте целостность резервных копий через RESTORE VERIFYONLY и тестовое восстановление на отдельном экземпляре. Для больших баз данных используйте опцию WITH MOVE для переноса файлов данных и журналов на доступные диски и избегайте конфликтов с существующими файлами.
Автоматизация процесса через SQL Server Agent позволяет создавать расписания резервного копирования, отправку уведомлений о сбоях и хранение логов операций. Систематический подход снижает риск потери данных и обеспечивает быстрое восстановление после сбоев или человеческих ошибок.
Вопрос-ответ:
Какие типы резервного копирования в SQL Server 2019 лучше использовать для базы с высокой нагрузкой?
В SQL Server 2019 доступны три основных типа: полное, дифференциальное и резервное копирование журнала транзакций. Для баз с высокой нагрузкой рекомендуется создавать полное резервное копирование раз в сутки, дифференциальные копии каждые несколько часов, а журнальные копии — с интервалом 15–30 минут. Такой подход позволяет сократить время восстановления и минимизировать потерю данных при сбоях или ошибках пользователей.
Как выбрать между кластерными и некластерными индексами для таблицы с миллионами строк?
Кластерный индекс задаёт физический порядок строк и хорошо подходит для столбцов с уникальными значениями, например, первичных ключей. Некластерные индексы создают отдельную структуру для ускорения поиска по часто используемым столбцам без изменения порядка строк. Для больших таблиц лучше использовать кластерный индекс на идентификаторе записи, а дополнительные некластерные индексы на колонках, участвующих в фильтрах и соединениях, с включением INCLUDE для охвата часто запрашиваемых данных.
Какие настройки стоит учитывать при создании новой базы данных через SSMS?
При создании базы данных через SQL Server Management Studio важно указать имя, настроить расположение файлов данных и журналов транзакций на разных дисках, выбрать начальные размеры и приросты файлов. Размер данных рекомендуется устанавливать на 10 ГБ с приростом 1 ГБ, журналов — 2 ГБ с приростом 512 МБ. Также следует задать collation в соответствии с требованиями приложений и выбрать подходящую модель восстановления (Simple, Full или Bulk-Logged) для управления журналом транзакций.
Как правильно настраивать пользователей и роли для ограничения доступа в базе?
Создавайте логины на сервере и сопоставляйте их с пользователями в базах данных через «User Mapping». Для контроля доступа используйте встроенные роли сервера и базы данных: например, db_datareader для чтения и db_datawriter для записи. Если стандартные роли не подходят, создавайте пользовательские роли через CREATE ROLE и назначайте конкретные разрешения через GRANT. Регулярно проверяйте список логинов и удаляйте неиспользуемые, а также включайте проверку сложности паролей и аудит действий через SQL Server Audit.