Содержание статьи

При формировании текстов для веба или документации Python чаще используется как генератор разметки. В этом случае выделение достигается через вставку HTML-тегов или Markdown-синтаксиса в строки. Такой подход требует аккуратной работы со строками, экранированием символов и понимания того, где именно будет интерпретироваться результат – браузером, парсером Markdown или сторонним рендерером.
Отдельную категорию составляют графические интерфейсы и текстовые виджеты, например Tkinter Text, где выделение фрагментов реализуется через систему тегов и диапазонов символов. Здесь важно учитывать индексацию, обновление состояния текста и влияние форматирования на пользовательский ввод. В статье рассматриваются прикладные способы выделения текста в Python с привязкой к конкретным средам и задачам, а не абстрактные примеры «для демонстрации возможностей».
Выделение текста цветом в терминале через ANSI escape-последовательности
Современные терминалы поддерживают расширенную палитру из 256 цветов и режим true color. Для 256-цветного режима используется формат \033[38;5;N m, где N – индекс цвета от 0 до 255. Для точного задания оттенка через RGB применяется последовательность \033[38;2;R;G;B m. Такой подход подходит для визуального кодирования состояний, но требует проверки поддержки терминалом, иначе текст будет выведен без форматирования.
Оформление текста в консоли с помощью библиотеки colorama
Для форматирования текста используются перечисления Fore, Back и Style, которые содержат предопределённые значения цветов и атрибутов. Например, Fore.RED изменяет цвет текста, Back.YELLOW задаёт фон, а Style.BRIGHT усиливает визуальный контраст. Все значения представлены строками, поэтому их можно свободно комбинировать и вставлять в f-строки или шаблоны форматирования.
Colorama не расширяет стандарт ANSI-возможности и не поддерживает 256-цветную палитру или RGB-режим. Библиотека ориентирована на простое выделение: ошибки, предупреждения, статусы выполнения. Для логирования её удобно сочетать с модулем logging, формируя цветные сообщения на уровне форматтера, не вмешиваясь в бизнес-логику приложения.
Использование разметки и стилей текста в консоли через библиотеку rich
- выделение фрагментов через теги [bold], [underline], [italic]
- задание цвета текста и фона с помощью [red], [on blue], [#ff8800]
- вложенные стили без риска нарушения форматирования
Для программного управления стилями применяется класс Text, позволяющий добавлять стили к диапазонам символов. Такой подход удобен при обработке строк, где форматирование зависит от позиции или содержимого, например при подсветке ошибок или совпадений поиска.
- создание объекта Text из исходной строки
- применение стилей к срезам через метод stylize
Rich автоматически определяет возможности терминала и отключает расширенное оформление при отсутствии поддержки. Для консольных утилит, ориентированных на читаемость и сложное форматирование, рекомендуется использовать rich вместо прямой работы с ANSI-кодами или минималистичных библиотек.
Формирование выделенного текста в Markdown при генерации строк в Python
Базовые элементы выделения представлены простыми маркерами, которые легко комбинируются со строковыми операциями Python. При генерации текста важно учитывать экранирование символов, если содержимое формируется из пользовательских данных или внешних источников.
- жирное начертание через оборачивание в текст
- курсив с помощью *текст* или _текст_
- встроенный код через одиночные обратные кавычки
- блоки кода с использованием тройных обратных кавычек
Для структурированного формирования Markdown в Python удобно использовать шаблоны строк и f-строки, вынося разметку в константы. Это снижает риск ошибок и упрощает изменение формата без переработки логики генерации.
- подготовка шаблона Markdown с плейсхолдерами
- подстановка значений через форматирование строк
- проверка результата в целевом рендерере Markdown
Оборачивание текста в HTML-теги средствами Python
В Python формирование HTML-разметки выполняется через конкатенацию строк, шаблоны или специализированные библиотеки. Для выделения текста применяются теги <strong>, <em>, <span> с атрибутами стиля. Важно корректно закрывать теги и экранировать специальные символы, чтобы результат не ломал структуру документа.
Простейший способ – использовать f-строки или метод format:
- оборачивание фрагмента в <strong> для жирного начертания: f»<strong>{text}</strong>»
- добавление курсива через <em>: f»<em>{text}</em>»
- индивидуальная настройка цвета и шрифта через <span style="color:#ff0000;"> и другие CSS-свойства
Для динамического контента рекомендуется экранировать HTML-символы с помощью html.escape(), чтобы избежать нежелательной интерпретации пользовательских данных. Это особенно актуально при генерации отчётов, писем и веб-страниц из внешних источников.
При работе с большими документами удобнее использовать библиотеки yattag или lxml.etree, которые позволяют создавать структуру HTML через методы и контекстные менеджеры. Такой подход минимизирует ошибки закрытия тегов, упрощает добавление атрибутов и делает код более читаемым по сравнению с ручной конкатенацией строк.
Выделение фрагментов текста в виджете Tkinter Text с помощью тегов
В Tkinter виджет Text позволяет управлять форматированием отдельных фрагментов текста через систему тегов. Каждый тег задаётся методом text_widget.tag_configure() с параметрами: цвет текста, фон, шрифт, начертание и другие атрибуты. Теги затем применяются к диапазонам символов методом text_widget.tag_add().
Для практического использования рекомендуется:
- создавать отдельные теги для каждого типа выделения, например highlight, error, bold;
- использовать индексную систему Tkinter: строки и символы указываются как «1.0» для начала и «1.5» для конца диапазона;
- удалять или изменять тег динамически через tag_remove или повторный вызов tag_configure для обновления стиля;
- комбинировать несколько тегов на одном фрагменте текста – визуальные эффекты суммируются, если нет конфликтующих свойств.
Теги в Tkinter удобны для подсветки результатов поиска, ошибок ввода, синтаксиса кода и других визуальных акцентов. Для больших текстовых областей рекомендуется группировать операции изменения тегов в блоки, чтобы минимизировать мерцание и снизить нагрузку на рендеринг виджета.
Поиск и выделение частей текста регулярными выражениями с последующей разметкой
Регулярные выражения в Python позволяют находить фрагменты текста по сложным шаблонам с помощью модуля re. Для выделения таких фрагментов создаются новые строки, где совпадения оборачиваются в теги или специальные маркеры, применимые в консоли, HTML или Markdown. Это удобно при подсветке ключевых слов, ссылок, числовых значений или ошибок.
Пример алгоритма выделения с разметкой:
- компиляция шаблона через re.compile(pattern) для повторного использования;
- поиск всех совпадений с помощью finditer, чтобы получить позиции начала и конца каждого фрагмента;
- формирование новой строки с оборачиванием совпадений в теги или маркеры, сохраняя остальной текст;
Для систематизации часто применяются таблицы, которые связывают регулярные выражения и стиль выделения. Пример:
| Шаблон | Назначение | Маркер/Тег |
|---|---|---|
| \bERROR\b | Подсветка ошибок | <strong>ERROR</strong> |
| \b\d{4}-\d{2}-\d{2}\b | Выделение дат | <em>\1</em> |
| https?://[^\s]+ | Ссылки | <a href=»\1″>\1</a> |
При работе с регулярными выражениями важно экранировать специальные символы и проверять корректность диапазонов. Для больших текстов рекомендуется применять re.sub с функцией обратного вызова, чтобы динамически формировать теги, не нарушая структуру исходного текста.
Вопрос-ответ:
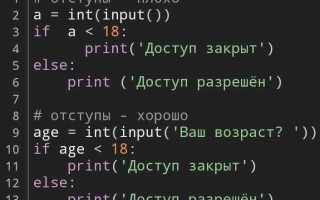
Как правильно использовать ANSI escape-последовательности для изменения цвета текста в Python на Windows и Linux?
ANSI escape-последовательности работают в Linux-консолях без дополнительных настроек, достаточно выводить строку вида \033[31mТекст\033[0m для красного цвета. В Windows старых версий стандартная консоль их не обрабатывает, поэтому рекомендуется использовать библиотеку colorama. После вызова colorama.init() управляющие коды автоматически преобразуются для Windows, и цветной вывод работает одинаково на всех системах.
В чём преимущество использования библиотеки rich для оформления текста по сравнению с обычными ANSI-кодами?
Rich предоставляет декларативный способ задания стилей и поддерживает вложенные разметки. Например, можно одновременно применить цвет, фон и жирное начертание к одному фрагменту текста без риска забыть сбросить предыдущие стили. Кроме того, библиотека автоматически определяет, поддерживает ли терминал расширенные цвета и сложные эффекты, и корректно отключает их, если терминал не умеет их отображать.
Как выделять отдельные слова или диапазоны текста в Tkinter Text?
Виджет Text использует систему тегов для форматирования. Сначала создаётся тег с нужными параметрами через tag_configure, например: text_widget.tag_configure(«highlight», background=»yellow»). Затем тег применяется к диапазону символов через tag_add, например: text_widget.tag_add(«highlight», «1.0», «1.5»). Несколько тегов можно накладывать на один фрагмент, эффекты суммируются.
Какие ошибки чаще всего возникают при генерации Markdown с выделением текста в Python?
Основные проблемы связаны с неправильным экранированием символов и некорректной вставкой управляющих маркеров. Например, если текст содержит символы * или _ внутри выделяемого фрагмента, Markdown интерпретирует их как часть форматирования. Для предотвращения таких ситуаций рекомендуется использовать экранирование или проверять содержимое перед вставкой в шаблон, а также тестировать результат в целевом рендерере.
Как сочетать регулярные выражения с выделением текста для формирования HTML-отчётов?
Сначала через re.compile создаются шаблоны для поиска нужных фрагментов, затем с помощью finditer получаются позиции совпадений. После этого формируется новая строка, где совпадения оборачиваются в HTML-теги, например: <strong> или <em>. Для нескольких совпадений можно использовать re.sub с функцией, которая динамически вставляет тег, сохраняя остальной текст без изменений. Такой подход удобен для подсветки ошибок, ссылок и ключевых слов.
Как правильно комбинировать несколько стилей текста в библиотеке rich для консоли, чтобы они не конфликтовали?
В библиотеке rich каждый фрагмент текста можно оформить через объект Text или через разметку с тегами, такими как [bold], [red], [underline]. Чтобы стили не конфликтовали, нужно применять их последовательно и использовать вложенные теги корректно: более внешний тег задаёт общий стиль, внутренние уточняют его для подфрагментов. Также полезно использовать методы stylize с указанием диапазонов символов, а не просто вставлять несколько тегов подряд, так как при этом rich аккуратно объединяет атрибуты и предотвращает сброс предыдущих стилей. Для динамического текста можно формировать объект Text, добавлять диапазоны с разными стилями и выводить через console.print, что гарантирует корректное отображение независимо от длины строки и количества вложенных эффектов.