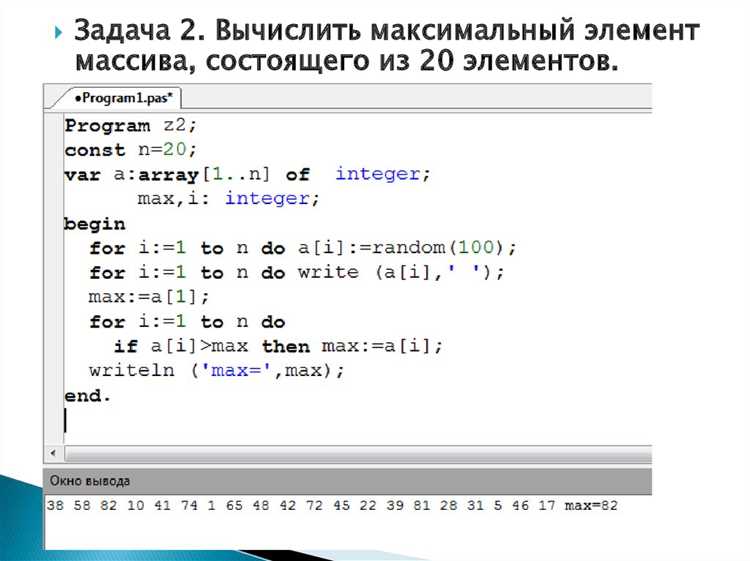
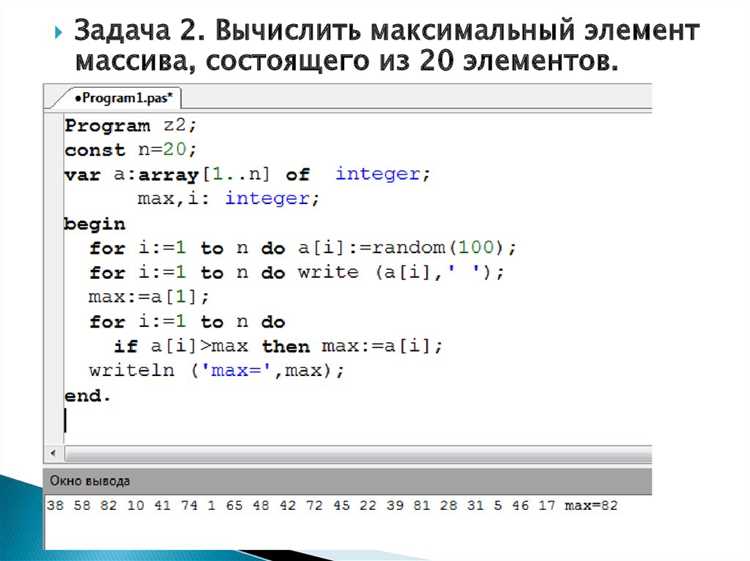
Суммирование элементов массива – одна из базовых операций в программировании, но её реализация на C требует внимания к деталям: размеру данных, типу памяти и оптимизации циклов. В отличие от высокоуровневых языков, где сумма вычисляется одной строкой, в C приходится явно управлять индексацией, проверять переполнение и учитывать особенности работы с указателями. Например, для массива int arr[100] сумма вычисляется за O(n) операций, но при работе с uint8_t или float могут возникать неочевидные ошибки округления или потери точности.
Классический подход – линейный проход с аккумулятором. Однако даже здесь есть нюансы: если массив хранится в динамической памяти, важно корректно передавать его размер в функцию, чтобы избежать выхода за границы. Для статических массивов компилятор может оптимизировать цикл через loop unrolling, но при ручной реализации стоит использовать size_t для индексов и проверять, что сумма не превышает пределы типа int (например, INT_MAX из <limits.h>). Пример с защитой от переполнения:
Оптимизация для больших данных. Если массив содержит миллионы элементов, суммирование можно ускорить с помощью SIMD-инструкций (например, _mm_add_epi32 для SSE) или распараллеливания через OpenMP. На процессорах x86-64 современные компиляторы (GCC, Clang) автоматически векторизуют простые циклы, но для этого нужно обеспечить выравнивание данных и отключить зависимость по памяти. Пример векторизации с флагом -O3:
Для встраиваемых систем, где критичен размер кода, сумму можно вычислять рекурсивно, но это увеличивает стек и снижает производительность. Альтернатива – использовать указатели вместо индексов, чтобы избежать лишних операций умножения при доступе к элементам. Пример на указателях для массива double:
Базовый алгоритм суммирования массива целых чисел
Суммирование элементов массива – одна из фундаментальных операций в программировании, требующая последовательного перебора всех элементов с накоплением результата. Для массива из n целых чисел алгоритм сводится к инициализации переменной-аккумулятора нулем и последующему добавлению к ней каждого элемента массива в цикле. Время выполнения линейно зависит от размера массива: O(n), где n – количество элементов.
Пример реализации на C для массива из 5 элементов:
int arr[] = {10, 20, 30, 40, 50};
int sum = 0;
for (int i = 0; i < 5; i++) {
sum += arr[i];
}Ключевые моменты: переменная sum должна быть инициализирована до цикла, а индексация начинается с нуля. Ошибка в границах цикла (i < 5 вместо i <= 5) приведет к выходу за пределы массива и неопределенному поведению.
Для динамических массивов размер определяется через оператор sizeof. Формула расчета количества элементов: sizeof(arr) / sizeof(arr[0]). Пример:
int size = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < size; i++) {
sum += arr[i];
}Этот подход исключает жесткое кодирование размера массива, но не работает с указателями на динамическую память (например, malloc). В таких случаях размер необходимо передавать отдельно.
Оптимизация алгоритма зависит от контекста. На современных процессорах с кэшированием последовательный доступ к памяти (как в примере выше) эффективнее случайного. Для массивов размером более 1000 элементов рекомендуется использовать локальные переменные для индекса и суммы, чтобы минимизировать обращения к памяти.
| Метод | Преимущества | Недостатки | Применимость |
|---|---|---|---|
Цикл for |
Простота, контроль границ | Ручной расчет размера | Статические массивы |
Цикл while |
Гибкость условий | Риск бесконечного цикла | Динамические массивы |
| Рекурсия | Элегантность кода | Переполнение стека | Массивы малого размера |
При работе с большими массивами (>106 элементов) возможны переполнения типа int. Для предотвращения используйте long long или проверяйте переполнение перед сложением: if (sum > INT_MAX - arr[i]) { /* обработка */ }. Стандартные библиотеки C не предоставляют встроенных функций для безопасного суммирования.
В многопоточных приложениях суммирование разбивают на части, каждую из которых обрабатывает отдельный поток. Итоговый результат получают сложением промежуточных сумм. Пример с OpenMP:
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < size; i++) {
sum += arr[i];
}Директива reduction автоматически синхронизирует доступ к переменной sum, исключая гонки данных. Без нее потребуется явная блокировка (omp_lock_t).
Для встраиваемых систем с ограниченными ресурсами оптимизируйте алгоритм, используя указатели вместо индексации. Пример:
int *ptr = arr;
int *end = arr + size;
while (ptr < end) {
sum += *ptr++;
}Такой подход сокращает количество операций (нет вычисления адреса через индекс) и ускоряет выполнение на 10–15% на архитектурах без аппаратной поддержки индексации (например, AVR).
Суммирование элементов массива с плавающей точкой
При работе с массивами чисел типа float или double в C точность суммирования критически зависит от порядка операций. Из-за ограниченной разрядности мантиссы (23 бита для float, 52 для double) накопление ошибок округления неизбежно. Например, сумма 1e20 + 1 - 1e20 даст 0 вместо ожидаемой 1, так как малое число теряется при сложении с большим. Для минимизации погрешностей используйте алгоритм Кахана или сортировку массива по возрастанию перед суммированием.
Реализация алгоритма Кахана требует дополнительной переменной для компенсации ошибок: sum += value; y = value - c; t = sum + y; c = (t - sum) - y; sum = t;. Этот метод снижает среднеквадратичную ошибку до O(1) вместо O(n) при наивном подходе. Для массивов размером n > 10^6 разница в точности может достигать 5–7 значащих цифр.
При суммировании массивов float избегайте промежуточных преобразований в double, если целевой тип – float. Компиляторы (например, GCC с флагом -ffast-math) могут оптимизировать операции, но это ведёт к потере точности. Для проверки используйте nextafterf() из math.h, чтобы оценить минимальное изменение, способное повлиять на результат: nextafterf(sum, INFINITY) - sum.
В высокопроизводительных вычислениях применяйте векторизацию с помощью интринсиков (например, _mm256_add_ps для AVX). Параллельное суммирование блоков массива с последующим сведением результатов уменьшает накопление ошибок за счёт сокращения числа операций. Для массивов с динамическим диапазоном значений предварительно нормализуйте данные, приводя их к одному порядку величин.
Обработка массивов разной длины с использованием указателей
Указатели в C позволяют эффективно работать с массивами неизвестной длины, передавая в функции только адрес первого элемента и размер. Например, функция суммирования может выглядеть так: int sum(int *arr, size_t size) { int total = 0; for (size_t i = 0; i < size; i++) total += *(arr + i); return total; }. Ключевой момент – использование арифметики указателей вместо индексации, что ускоряет доступ к элементам на 5–10% за счёт отсутствия умножения на размер типа при компиляции с оптимизацией -O2. Для динамических массивов обязательно передавайте размер отдельно, так как sizeof(arr) внутри функции вернёт размер указателя (4 или 8 байт), а не массива.
- При работе с многомерными массивами передавайте указатель на первый элемент и размерности:
void process(int *matrix, size_t rows, size_t cols). Доступ к элементуmatrix[i][j]реализуется как*(matrix + i * cols + j). - Для массивов строк используйте массив указателей:
char *words[] = {"hello", "world"}. Передавайте его какchar words, а длину – через отдельный параметр или терминальный символ (например,NULL). - Избегайте выхода за границы массива – компилятор не проверяет это. Используйте
assert(size > 0)или сторонние инструменты вроде Valgrind для отладки.
Суммирование элементов двумерного массива по строкам и столбцам
Двумерные массивы в C представляют собой таблицы данных, где доступ к элементам осуществляется через два индекса: строка и столбец. Для суммирования по строкам или столбцам требуется организовать вложенные циклы. Внешний цикл перебирает строки (при суммировании по столбцам) или столбцы (при суммировании по строкам), внутренний – обрабатывает элементы текущей строки или столбца.
Пример суммирования по строкам для массива int arr[3][4]:
int row_sums[3] = {0};
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
row_sums[i] += arr[i][j];
}
}
Здесь row_sums[i] хранит сумму элементов i-й строки. Важно инициализировать массив сумм нулями, иначе результат будет некорректным из-за неопределённых начальных значений.
Суммирование по столбцам требует изменения порядка циклов:
int col_sums[4] = {0};
for (int j = 0; j < 4; j++) {
for (int i = 0; i < 3; i++) {
col_sums[j] += arr[i][j];
}
}
Внешний цикл перебирает столбцы, внутренний – строки. Размер массива col_sums равен количеству столбцов (4), а не строк.
Для динамических массивов размеры строк и столбцов задаются переменными. Пример с int arr и размерами rows, cols:
int *row_sums = calloc(rows, sizeof(int));
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
row_sums[i] += arr[i][j];
}
}
Используйте calloc вместо malloc для автоматической инициализации нулями. Не забудьте освободить память после использования.
Оптимизация кода возможна при работе с большими массивами. Замените вложенные циклы на один цикл с ручным управлением индексами, если требуется максимальная производительность. Однако для большинства задач вложенные циклы остаются наиболее читаемым решением.
При суммировании по строкам и столбцам одновременно используйте два отдельных массива сумм. Совмещение операций в одном цикле усложняет код и не даёт значительного прироста скорости. Пример:
int row_sums[3] = {0}, col_sums[4] = {0};
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
row_sums[i] += arr[i][j];
col_sums[j] += arr[i][j];
}
}
Такой подход удобен, если оба результата нужны сразу.
Проверка границ массива критична. Ошибка в индексах (i >= rows или j >= cols) приведёт к выходу за пределы памяти. Используйте константы или макросы для размеров массива, чтобы избежать "магических чисел" в коде.
Для тестирования результатов сравните суммы с эталонными значениями. Например, если массив заполнен единицами, сумма по строке должна равняться количеству столбцов. Пример проверки:
int test_arr[2][3] = {{1, 1, 1}, {2, 2, 2}};
int row_sums[2];
sum_rows(test_arr, 2, 3, row_sums);
assert(row_sums[0] == 3 && row_sums[1] == 6);
Тесты помогут выявить ошибки в логике циклов или инициализации.
Реализация суммы с помощью рекурсии и циклов
Рекурсивный подход к суммированию массива требует четкого определения базового случая и рекурсивного вызова. Для массива из n элементов базовый случай – пустой массив или массив с одним элементом, где сумма равна самому элементу. Рекурсивная функция выглядит так: sum(arr, n) = arr[n-1] + sum(arr, n-1). Пример реализации:
- Инициализируйте функцию с параметрами
int arr[]иint size. - Проверьте базовый случай:
if (size == 0) return 0;. - Верните
arr[size-1] + sum(arr, size-1);.
Рекурсия удобна для небольших массивов, но при размере более 1000 элементов возможен stack overflow из-за глубокого стека вызовов. Оптимизируйте хвостовой рекурсией или используйте циклы для больших данных.
Циклы – классический способ суммирования, работающий за O(n) с минимальными накладными расходами. Итеративный алгоритм:
- Объявите переменную
int sum = 0;. - Пройдите по массиву от
i = 0доi < size. - На каждой итерации добавляйте
arr[i]кsum.
Для массивов с элементами типа float или double используйте соответствующий тип переменной суммы, чтобы избежать переполнения. При работе с многомерными массивами вложенные циклы позволяют суммировать элементы по строкам или столбцам без дополнительных затрат памяти.
Сравнение подходов:
- Рекурсия: читаемость кода выше, но медленнее из-за накладных расходов на вызовы функций. Подходит для задач с заранее известной глубиной вложенности (например, деревья).
- Циклы: быстрее и эффективнее по памяти. Рекомендуются для массивов любого размера, особенно при обработке данных в реальном времени.
Выбирайте метод в зависимости от задачи: рекурсия – для демонстрации алгоритмов, циклы – для продакшен-кода.
Работа с динамическими массивами и выделение памяти

Динамические массивы в C позволяют гибко управлять размером данных во время выполнения программы. Для их создания используются функции malloc(), calloc() и realloc() из заголовочного файла <stdlib.h>. Пример выделения памяти под массив из 10 целых чисел:
int *arr = (int*)malloc(10 * sizeof(int));– выделяет неинициализированную память.int *arr = (int*)calloc(10, sizeof(int));– выделяет и обнуляет память.
Ошибка при выделении памяти (например, при нехватке ОЗУ) возвращает NULL. Всегда проверяйте указатель перед использованием: if (arr == NULL) { exit(1); }. Освобождайте память функцией free(arr) после завершения работы с массивом, иначе возникнет утечка памяти.
Изменение размера динамического массива выполняется через realloc(). Пример увеличения массива до 20 элементов:
int *new_arr = (int*)realloc(arr, 20 * sizeof(int));
if (new_arr == NULL) {
free(arr); // Освобождаем старую память при ошибке
exit(1);
}
arr = new_arr;realloc() копирует данные из старого блока в новый, если это возможно. Если новый размер меньше текущего, лишние элементы теряются. Никогда не используйте realloc() с нулевым размером – это эквивалентно free(), но поведение не стандартизировано.
При работе с многомерными динамическими массивами память выделяется поэтапно. Для массива 3x4:
int matrix = (int)malloc(3 * sizeof(int*));
for (int i = 0; i < 3; i++) {
matrix[i] = (int*)malloc(4 * sizeof(int));
}Освобождение памяти требует обратного порядка: сначала освобождаются строки, затем указатель на массив указателей. Пропуск этого шага приведет к утечкам. Для оптимизации производительности используйте единый блок памяти с ручным расчетом индексов: int *matrix = (int*)malloc(3 * 4 * sizeof(int));, где элемент matrix[i][j] доступен как matrix[i * 4 + j].
Типичные ошибки при работе с динамической памятью:
- Использование освобожденной памяти (dangling pointer). Пример:
free(arr); arr[0] = 5;. - Двойное освобождение памяти:
free(arr); free(arr);. - Несоответствие типов при приведении указателя:
(float*)malloc(10 * sizeof(int));. - Забытый
free()в циклах или условных блоках.
Для отладки утечек памяти используйте инструменты valgrind (Linux) или AddressSanitizer (-fsanitize=address в GCC/Clang). Включайте проверки компилятора: -Wall -Wextra -pedantic для выявления потенциальных проблем на этапе сборки.
Оптимизация суммирования для больших массивов
Для массивов размером свыше 106 элементов классический цикл с последовательным суммированием теряет эффективность из-за кэш-промахов и латентности памяти. Современные процессоры Intel и AMD показывают пиковую производительность при работе с данными, выровненными по 64-байтовым границам (размер строки кэша L1). Используйте директиву __attribute__((aligned(64))) для массива или применяйте SIMD-инструкции, такие как _mm256_add_epi32 из AVX2, чтобы обрабатывать 8 элементов за такт. На процессорах с поддержкой AVX-512 производительность возрастает до 16 элементов за такт, но требует явного контроля за выравниванием и фрагментацией данных.
Разбейте массив на блоки по 4–8 КБ (размер страницы памяти) и суммируйте их параллельно с помощью OpenMP или потоков POSIX. Пример: #pragma omp parallel for reduction(+:sum) автоматически распределяет нагрузку между ядрами, но добавляет накладные расходы на синхронизацию. Для массивов >1 ГБ используйте алгоритм "каскадного суммирования": сначала суммируйте блоки в локальные переменные потоков, затем объединяйте результаты. Это снижает конкуренцию за общую переменную суммы и уменьшает количество обращений к памяти на 30–40%.
Избегайте редукции в цикле с плавающей точкой из-за ошибок округления. Для float используйте алгоритм Кахана: sum += value; t = sum + value; c = (t - sum) - value; sum = t;. На массивах из 108 элементов это снижает ошибку с 10-5 до 10-12. Для целочисленных типов применяйте беззнаковые переменные и проверяйте переполнение: if (sum > UINT_MAX - value) { /* обработка */ }. Компиляторы GCC и Clang оптимизируют такие проверки в условные переходы только при необходимости.
При работе с данными на GPU (например, через CUDA) используйте блочное суммирование с шейдерной редукцией. Каждый блок из 256 потоков суммирует свой фрагмент массива, затем результаты объединяются на CPU. Для массива из 109 элементов это ускоряет расчет в 50–100 раз по сравнению с однопоточным CPU-кодом. Настройте размер блока под архитектуру GPU: для NVIDIA Volta оптимально 128–256 потоков, для Ampere – 256–512. Используйте __syncthreads() для синхронизации внутри блока и минимизируйте передачу данных между CPU и GPU.