Содержание статьи

Перенос текста с фотографии в документ Word – задача, которая решается за минуты, если знать правильные инструменты. Современные OCR-технологии (распознавание символов) позволяют извлекать текст с точностью до 95–99% при хорошем качестве изображения. В этой статье рассмотрим три проверенных способа: использование встроенного инструмента Microsoft Word, бесплатного сервиса Google Диска и специализированного ПО ABBYY FineReader.
Первый метод подойдет для пользователей Windows 10/11 и Office 365 – Word имеет встроенный OCR-модуль, который работает без дополнительных установок. Второй вариант удобен для тех, кто хранит файлы в облаке: Google Диск распознает текст на фотографиях формата JPG, PNG и PDF. Третий способ – для профессионалов, которым нужна максимальная точность и поддержка редких языков.
Для успешного распознавания важно соблюдать требования к исходному изображению: разрешение не ниже 300 DPI, равномерное освещение и отсутствие искажений. Если текст на фото размыт или написан от руки, точность упадет до 60–80%. В таких случаях лучше использовать ABBYY FineReader с настройками предварительной обработки.
Какие инструменты понадобятся для распознавания текста на изображении
Для переноса текста с фото в редактируемый формат нужны специализированные OCR-инструменты (Optical Character Recognition). Выбор зависит от задачи: объема текста, языка, качества изображения и необходимости редактирования результата. Ниже – ключевые решения с их особенностями.
Настольные программы подойдут для работы с большими объемами данных или конфиденциальными документами. Лидеры:
- ABBYY FineReader – поддерживает 200+ языков, распознает таблицы, сохраняет форматирование. Версия FineReader PDF 16 обрабатывает PDF и изображения с точностью до 99,8% для латиницы и кириллицы. Есть пакетная обработка.
- Adobe Acrobat Pro – встроенный OCR-модуль работает с PDF и сканами. Оптимален для офисных документов, но уступает ABBYY в точности при низком разрешении.
- Readiris – распознает 137 языков, включая арабский и иврит. Поддерживает экспорт в Word, Excel, PowerPoint с сохранением стилей.
Онлайн-сервисы удобны для разовых задач без установки ПО. Ограничения: зависимость от интернета, риски конфиденциальности. Популярные варианты:
- New OCR (newocr.com) – бесплатный, без регистрации. Распознает текст с фото и PDF, поддерживает 120 языков. Нет ограничений по количеству файлов, но размер – до 5 МБ.
- OnlineOCR.net – платный (от $9/месяц), но с пробной версией на 15 страниц. Точность выше средней, есть API для интеграции.
- Google Drive – встроенный OCR при загрузке изображений или PDF. Работает с 50+ языками, но форматирование теряется. Доступно только через веб-интерфейс.
Мобильные приложения решают задачу «на ходу». Подойдут для быстрого распознавания чеков, визиток или вывесок. Топ-выбор:
- Microsoft Lens (iOS/Android) – бесплатное, интегрируется с OneNote и Word. Автоматически обрезает фото, улучшает качество текста. Поддерживает 30+ языков.
- Text Fairy (Android) – офлайн-режим, распознает 50 языков. Экспортирует текст в PDF, TXT или отправляет на email.
- CamScanner – платный (от $4,99/месяц), но с расширенными функциями: пакетная обработка, облачное хранилище. Точность выше, чем у бесплатных аналогов.
Для разработчиков и автоматизации процессов подойдут библиотеки и API. Позволяют интегрировать OCR в собственные приложения:
- Tesseract – бесплатный движок от Google с открытым исходным кодом. Поддерживает 100+ языков, но требует предобработки изображений (бинаризация, удаление шумов). Версия Tesseract 5 работает быстрее предшественников.
- Amazon Textract – платный облачный сервис (от $0,0015 за страницу). Распознает текст, таблицы, формы. Интегрируется с AWS Lambda для автоматизации.
- Google Cloud Vision API – точность до 95% для печатного текста. Поддерживает рукописный текст (ограниченно). Цена – $1,50 за 1000 страниц.
При выборе инструмента учитывайте качество исходного изображения. Для четких сканов (300+ DPI) подойдут любые решения. Если текст размыт, с тенями или на цветном фоне, используйте программы с предобработкой: ABBYY FineReader или Adobe Acrobat Pro. Для рукописного текста – только специализированные сервисы вроде MyScript Nebo или Microsoft OneNote.
Языковая поддержка критична для многоязычных документов. ABBYY FineReader и Readiris распознают редкие языки (например, вьетнамский или тайский). Google Drive и Tesseract справляются с европейскими языками, но могут ошибаться с иероглифами. Перед использованием проверьте список поддерживаемых языков в документации.
Для корпоративного использования выбирайте решения с API и пакетной обработкой. Amazon Textract и Google Cloud Vision масштабируются для тысяч документов в день. Настольные программы (FineReader, Readiris) подойдут для локальной обработки без облачных рисков. Бесплатные онлайн-сервисы ограничены по объему и не гарантируют конфиденциальность.
Как выбрать и подготовить фото с текстом для обработки

Качество распознавания текста напрямую зависит от исходного изображения. Оптимальное разрешение – не менее 300 DPI, формат – JPEG или PNG без сжатия с потерями. Избегайте фотографий с низким контрастом, размытием или искажениями перспективы: программы OCR (например, ABBYY FineReader или Tesseract) корректно обрабатывают текст при угле наклона не более 10°. Если документ сфотографирован под углом, используйте инструменты поворота в фоторедакторах (например, «Исправить перспективу» в Adobe Photoshop или «Деформация» в GIMP) до отправки в Word.
Подготовьте изображение по следующим критериям:
| Параметр | Рекомендации | Инструменты коррекции |
|---|---|---|
| Освещение | Равномерное, без бликов и теней. Яркость – 60–80% от максимума | Кривые (Photoshop), «Автотон» (Lightroom) |
| Шрифт | Минимальный размер – 12 пт. Избегайте декоративных и рукописных гарнитур | Увеличение резкости (Unsharp Mask), бинаризация (ImageMagick) |
| Фон | Однотонный, без узоров. Для цветных фото – порог бинаризации 128 (серый) | Удаление фона (Remove.bg), пороговая фильтрация (GIMP) |
Перед загрузкой в Word обрежьте лишние поля: оставьте отступ 5–10 мм от текста. Для многостраничных документов сохраняйте файлы с последовательной нумерацией (page_01.jpg, page_02.jpg) – это упростит автоматическую сборку в единый документ.
Как использовать встроенные средства Word для извлечения текста

В Word 2019 и новее появилась функция «Преобразовать в текст» для изображений, доступная через контекстное меню. Выделите фото в документе, щелкните правой кнопкой мыши и выберите «Копировать текст с рисунка». Программа автоматически распознает текст и вставит его в документ с сохранением исходного форматирования изображения.
Для работы с PDF-файлами, содержащими отсканированные страницы, используйте вкладку «Файл» → «Открыть» → выберите PDF. Word предложит конвертировать его в редактируемый документ. Процесс занимает 10–30 секунд в зависимости от объема текста и разрешения скана. Точность распознавания достигает 95% при разрешении от 300 DPI.
Если текст на фото расположен неровно или под углом, предварительно выровняйте изображение с помощью инструмента «Поворот» в разделе «Формат рисунка». Word лучше распознает текст, когда строки параллельны границам страницы. Для сложных случаев (например, рукописный текст) точность падает до 60–70%.
В Word Online функция распознавания текста отсутствует, но можно использовать десктопную версию или OneNote для извлечения текста, а затем перенести его в Word. OneNote поддерживает OCR для изображений и рукописных заметок, после чего текст копируется через буфер обмена.
При работе с многоязычными документами выделите текст после распознавания и переключите язык проверки на вкладке «Рецензирование». Word автоматически исправит ошибки, связанные с неверным определением языка. Для редких языков (например, грузинского или армянского) установите соответствующий языковой пакет через «Параметры» → «Язык».
Чтобы повысить точность распознавания, увеличьте контрастность изображения перед вставкой в Word. Используйте бесплатные инструменты вроде GIMP или онлайн-сервисы (например, iloveimg.com) для настройки яркости и удаления шумов. Избегайте фото с цветным фоном – Word лучше работает с черно-белыми или монохромными изображениями.
Если текст не распознается, проверьте настройки Word: перейдите в «Файл» → «Параметры» → «Дополнительно» и убедитесь, что включена опция «Распознавать текст на изображениях». В редких случаях помогает перезапуск программы или обновление до последней версии через Microsoft Store.
Для массовой обработки изображений используйте макрос VBA. Запишите последовательность действий: вставка фото → распознавание текста → сохранение результата. Затем примените макрос ко всем файлам в папке через цикл. Пример кода доступен в официальной документации Microsoft по запросу «Word VBA OCR macro».
Как применить онлайн-сервисы для распознавания текста с фото
Онлайн-сервисы для OCR (оптического распознавания символов) позволяют извлекать текст из изображений без установки программ. Популярные инструменты – Google Drive, OnlineOCR.net и New OCR – поддерживают форматы JPG, PNG и PDF, распознают текст на 50+ языках, включая русский, и сохраняют исходное форматирование (выделение жирным, курсивом, списки). Для работы достаточно загрузить файл, выбрать язык и получить результат в формате DOCX, TXT или PDF. Точность распознавания достигает 95–98% при четком изображении и контрастном тексте, но падает до 70–80% на фотографиях с искажениями или низким разрешением.
Google Drive интегрирован с Google Документами и распознает текст автоматически при загрузке изображения или PDF. Чтобы воспользоваться функцией, откройте файл в Google Диске, щелкните правой кнопкой мыши и выберите «Открыть с помощью» → «Google Документы». Сервис бесплатен, но ограничивает размер файла до 2 МБ для изображений и 10 МБ для PDF. OnlineOCR.net предлагает 15 бесплатных распознаваний в час без регистрации, поддерживает пакетную обработку до 15 файлов одновременно и экспортирует таблицы в Excel. Для коммерческого использования доступны платные тарифы от $9,90 в месяц с увеличенными лимитами.
При выборе сервиса учитывайте специфику задачи. Для рукописного текста подойдет MyScript Nebo (точность до 90%), а для технических документов с формулами – Mathpix, который распознает LaTeX-выражения. Если требуется конфиденциальность, используйте офлайн-решения вроде Adobe Acrobat Pro или ABBYY FineReader, так как онлайн-сервисы хранят загруженные данные на своих серверах до 24 часов. Перед загрузкой отсканируйте документ с разрешением не менее 300 DPI и обрежьте лишние поля – это сократит время обработки и повысит точность.
После распознавания обязательно проверьте результат. Ошибки чаще возникают в числах, спецсимволах и тексте на фоне с градиентом. Исправьте опечатки вручную или с помощью встроенных инструментов Word (например, «Правописание и грамматика»). Для массовой обработки документов автоматизируйте процесс через API сервисов: например, API Google Vision OCR обрабатывает до 1000 страниц в минуту, но требует технических навыков для настройки.
Как скопировать распознанный текст и вставить его в документ Word
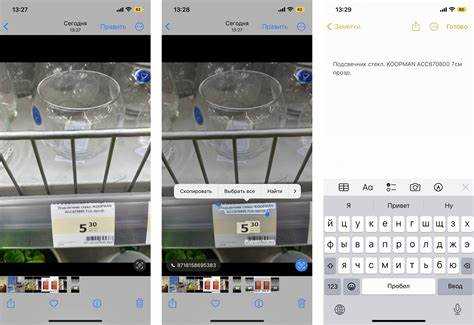
После распознавания текста с фото через инструменты вроде ABBYY FineReader, Adobe Scan или Google Keep вы получаете доступ к редактируемому содержимому. Чтобы перенести его в Word, выделите нужный фрагмент мышью или используйте комбинацию Ctrl+A для выбора всего текста. Если программа поддерживает горячие клавиши, Ctrl+C скопирует данные в буфер обмена за секунду.
Откройте документ Word и установите курсор в нужное место. Вставка выполняется через Ctrl+V или правый клик мыши с выбором опции «Вставить». Если текст содержит таблицы или форматирование, используйте специальную вставку: Ctrl+Alt+V → «Сохранить только текст» для удаления лишних стилей.
- Для многостраничных документов проверьте последовательность распознанных блоков – иногда программы перемешивают абзацы.
- Если текст вставляется с ошибками кодировки (например, кракозябры), сохраните его сначала в формате
.txt, а затем откройте в Word. - В Word 2019 и новее доступна функция «Вставить с форматированием исходного текста» – она сохраняет шрифты и выравнивание.
При работе с PDF, конвертированными в текст, обратите внимание на переносы строк. Word может вставлять лишние разрывы – удалите их через поиск и замену: Ctrl+H, в поле «Найти» введите ^p, в «Заменить на» – пробел. Для сложных документов используйте макросы или плагин «Kutools for Word» для пакетной обработки.
Если распознанный текст содержит гиперссылки или сноски, проверьте их работоспособность после вставки. Word автоматически преобразует URL в кликабельные ссылки, но иногда требуется ручная корректировка через контекстное меню «Изменить гиперссылку». Для сносок используйте инструмент «Вставить сноску» на вкладке «Ссылки».
Сохраните документ сразу после вставки в формате .docx – это минимизирует риск потери форматирования. Для резервного копирования экспортируйте текст в .pdf через «Файл» → «Экспорт» → «Создать PDF/XPS». Если планируете дальнейшее редактирование, включите отслеживание изменений: Ctrl+Shift+E.
Как проверить и отформатировать перенесённый текст в документе
После распознавания текста с фото в Word откройте документ и первым делом запустите проверку орфографии. Нажмите F7 или перейдите в раздел «Рецензирование» → «Правописание». Word выделит ошибки красным, а грамматические недочёты – синим. Особое внимание уделите словам с дефисами, аббревиатурам и терминам: они часто распознаются некорректно. Если программа предлагает неверную замену, игнорируйте её или добавьте слово в словарь через контекстное меню.
Сравните перенесённый текст с исходным изображением. Частые ошибки распознавания:
- Замена букв: «о» → «0», «з» → «3», «ч» → «4».
- Пропуск или дублирование пробелов между словами.
- Неправильное разбиение абзацев, особенно если на фото текст расположен в несколько колонок.
- Слипшиеся слова из-за некачественного снимка (например, «текстнафото» вместо «текст на фото»).
Для ускорения проверки используйте функцию «Найти и заменить» (Ctrl+H). Введите типичные ошибки в поле «Найти» и укажите правильный вариант в «Заменить на». Например, замените все «0» на «о» в словах, но исключите цифры.
Отформатируйте структуру документа. Выделите весь текст (Ctrl+A) и сбросьте стили через «Главная» → «Стили» → «Очистить всё». Затем примените единообразное форматирование:
- Заголовки: используйте стили «Заголовок 1», «Заголовок 2» и т. д. для автоматического создания оглавления.
- Основной текст: шрифт Times New Roman 12 пт или Arial 11 пт, межстрочный интервал 1,15–1,5.
- Выравнивание: по ширине для основного текста, по левому краю для списков.
- Отступы: 1,25 см для первой строки абзаца (настраивается в «Абзац» → «Отступы и интервалы»).
Проверьте специальные символы и форматирование. Распознаватели часто путают:
- Кавычки: «ёлочки» заменяются на «» или «лапки». Исправьте через Ctrl+H.
- Тире и дефисы: длинное тире – (Alt+0151) вместо короткого —.
- Неразрывные пробелы (Ctrl+Shift+Пробел) перед предлогами и союзами в начале строки.
- Табуляцию: замените множественные пробелы на табуляцию (Tab) для выравнивания таблиц или списков.
Сохраните документ в двух форматах: .docx (для редактирования) и .pdf (для финальной версии). Перед конвертацией в PDF убедитесь, что все гиперссылки работают, а изображения (если они были в исходнике) вставлены корректно. Для проверки печати используйте режим «Предварительный просмотр» (Ctrl+F2) – так вы увидите, как текст ляжет на страницу.