Содержание статьи

Базы данных представляют собой организованные хранилища информации, где данные структурированы в таблицы, строки и столбцы для быстрого поиска и обработки. Каждая таблица имеет уникальный ключ, обеспечивающий однозначную идентификацию записей, а связи между таблицами позволяют строить сложные запросы без дублирования информации.
Типы баз данных определяют способ хранения и обработки информации. Реляционные базы используют таблицы с четко заданными схемами и поддержкой SQL-запросов, документные базы хранят данные в формате JSON или XML, что упрощает работу с полуструктурированной информацией. Выбор типа зависит от объема данных и требований к скорости поиска.
Индексы ускоряют доступ к часто запрашиваемым полям, уменьшая время выполнения операций поиска. Планируя структуру базы, рекомендуется создавать индексы на колонках, которые участвуют в фильтрации и соединениях таблиц, но избегать чрезмерного их количества, чтобы не увеличивать нагрузку на обновление данных.
Транзакции гарантируют сохранение целостности данных при одновременной работе нескольких пользователей. Применение механизма ACID позволяет откатывать изменения при ошибках, что критично для финансовых и учетных систем. Практика резервного копирования баз данных каждые несколько часов защищает от потери информации при сбоях оборудования или программных ошибок.
Контроль доступа обеспечивает разграничение прав пользователей: одни могут только читать данные, другие – изменять или администрировать базу. Настройка ролей и паролей снижает риск несанкционированных изменений и утечек информации, особенно при работе с внешними сервисами или облачными платформами.
Типы баз данных и их практическое применение
Выбор типа базы данных напрямую влияет на скорость обработки запросов и удобство работы с данными. На практике применяются несколько основных типов:
- Реляционные базы данных (RDBMS): используют таблицы с фиксированной схемой. Применяются для финансовых систем, складского учета и CRM, где важна строгая структура и поддержка сложных SQL-запросов.
- Документные базы данных: хранят данные в формате JSON или XML. Оптимальны для веб-приложений и сервисов с полуструктурированной информацией, таких как каталоги товаров или блоги.
- Ключ-значение: данные хранятся как пары «ключ–значение». Используются для кеширования и хранения сессий пользователей, где необходим быстрый доступ к отдельным элементам.
- Графовые базы данных: строят связи между объектами в виде графов. Применимы для социальных сетей, рекомендационных систем и анализа сетевых связей.
- Колонкоориентированные базы: хранят данные по столбцам вместо строк, что ускоряет агрегации и аналитические запросы. Используются в BI-системах и для работы с большими массивами данных.
При выборе базы данных важно оценивать характер нагрузки:
- Частота чтения и записи данных.
- Необходимость сложных соединений между таблицами.
- Объем и структура информации: строго структурированная или гибкая.
- Требования к масштабированию и распределению данных между серверами.
Практический совет: для проектов с изменяющейся схемой лучше использовать документные базы, а для систем с финансовыми транзакциями и строгими связями – реляционные базы. Комбинированные подходы позволяют сочетать преимущества разных типов и повышают надежность работы приложения.
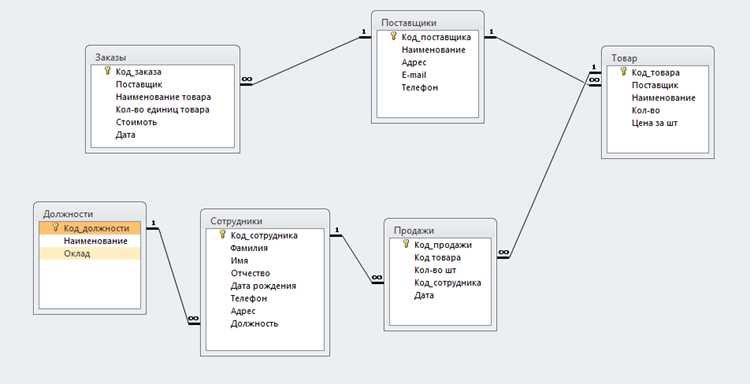
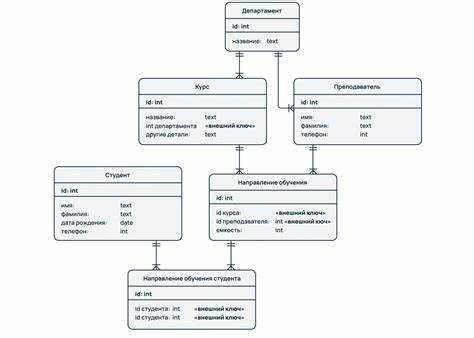
Как устроены таблицы и связи между ними
Каждая таблица должна иметь первичный ключ (PRIMARY KEY) – уникальный идентификатор записи. Он гарантирует уникальность строк и используется для создания связей с другими таблицами.
Связи реализуются через внешние ключи (FOREIGN KEY). Например, поле customer_id в таблице Заказы ссылается на id в таблице Клиенты, формируя связь один ко многим: один клиент может иметь несколько заказов.
Связь многие ко многим реализуется через промежуточную таблицу. Например, таблицы Студенты и Курсы соединяются таблицей Записи, содержащей student_id и course_id. Каждая запись фиксирует участие одного студента в одном курсе.
Индексы повышают производительность выборок и объединений таблиц. Индекс по внешнему ключу ускоряет JOIN-запросы и поиск данных в больших таблицах.
При проектировании следует применять нормализацию. Первые три нормальные формы исключают дублирование данных, обеспечивают атомарность полей и устраняют транзитивные зависимости, что поддерживает целостность информации.
Правильная структура таблиц и корректные связи позволяют строить точные SQL-запросы для выборки, обновления и удаления данных без потерь и нарушений целостности.
Роль индексов в ускорении поиска данных
Типы индексов:
- B-Tree – стандартный индекс для быстрого поиска, сортировки и диапазонных запросов.
- Hash – оптимален для точного поиска по ключу, не подходит для диапазонов.
- Bitmap – эффективен для столбцов с ограниченным числом уникальных значений.
Применение индексов:
- Ускорение SELECT-запросов с условиями WHERE.
- Оптимизация JOIN по внешним ключам.
- Повышение скорости ORDER BY и GROUP BY.
- Снижение нагрузки на сервер при больших объемах данных.
Рекомендации:
- Создавать индексы на колонках, часто используемых в фильтрах и соединениях.
- Избегать избыточных индексов, так как они замедляют INSERT, UPDATE и DELETE.
- Использовать составные индексы для нескольких колонок, если они часто встречаются вместе в запросах.
- Регулярно анализировать эффективность индексов с помощью EXPLAIN или аналогичных инструментов.
Правильное использование индексов снижает время отклика запросов с тысяч до долей миллисекунд при больших таблицах.
Механизмы хранения и форматы данных
Данные в базе хранятся в физических структурах, оптимизированных под тип СУБД и объем информации. Основные механизмы хранения:
- Строковое хранение (Row Storage) – данные записей хранятся последовательно строками. Эффективно для операций вставки и выборки полной строки.
- Столбцовое хранение (Column Storage) – данные каждого поля хранятся отдельно. Позволяет ускорить агрегатные операции и выборку отдельных колонок при больших таблицах.
- Файловая организация – данные разбиваются на блоки или страницы фиксированного размера. Позволяет управлять кэшированием и снижает количество операций чтения с диска.
- Журнал транзакций – хранит последовательность изменений для восстановления и обеспечения целостности данных.
Форматы данных определяют способ кодирования значений в таблицах. Типовые форматы:
| Тип данных | Формат хранения | Примечание |
|---|---|---|
| INTEGER | 4 байта | Целые числа, оптимизированы под арифметические операции |
| BIGINT | 8 байт | Большие целые числа, используется для уникальных идентификаторов |
| VARCHAR(n) | Переменная длина, n байт максимум | Текстовые строки, экономия места при коротких значениях |
| DATE / TIMESTAMP | 4–8 байт | Дата и время, хранение в формате, поддерживающем арифметику и сравнение |
| BLOB / BYTEA | Переменная длина | Двоичные данные, изображения, документы |
Рекомендации:
- Выбирать тип данных с минимально достаточным размером для значений.
- Использовать строковое хранение для OLTP-систем и столбцовое для аналитических нагрузок.
- Регулярно мониторить использование страниц и фрагментацию для оптимизации производительности.
- Для больших объектов применять отдельные таблицы или файловое хранение с ссылкой на основной объект.
Запросы SQL: чтение, добавление и изменение записей
Для работы с данными используются ключевые операции SQL: SELECT, INSERT, UPDATE и DELETE. Они позволяют извлекать, добавлять и модифицировать записи в таблицах.
Чтение данных (SELECT):
- Выбор всех столбцов: SELECT * FROM Таблица;
- Фильтрация записей: SELECT имя, возраст FROM Клиенты WHERE возраст > 30;
- Сортировка: ORDER BY для упорядочивания по одному или нескольким полям.
- Объединение таблиц: JOIN позволяет получать связанные данные из нескольких таблиц.
- Агрегация: функции SUM, COUNT, AVG, MIN, MAX для вычислений по столбцам.
Добавление данных (INSERT):
- Полное добавление записи: INSERT INTO Клиенты (имя, возраст, email) VALUES (‘Иван’, 28, ‘ivan@mail.com’);
- Добавление нескольких записей за один запрос: INSERT INTO Таблица VALUES (…), (…), (…);
- Вставка через SELECT: INSERT INTO Архив SELECT * FROM Клиенты WHERE возраст > 60;
Изменение данных (UPDATE):
- Обновление отдельных полей: UPDATE Клиенты SET email = ‘new@mail.com’ WHERE id = 5;
- Массовое изменение с фильтром: UPDATE Заказы SET статус = ‘Завершен’ WHERE дата < ‘2025-01-01’;
- Использование вычислений: UPDATE Продукты SET цена = цена * 1.1; для увеличения всех цен на 10%.
Удаление данных (DELETE):
- Удаление одной записи: DELETE FROM Клиенты WHERE id = 10;
- Удаление по условию: DELETE FROM Лог WHERE дата < ‘2024-01-01’;
- Внимание: без WHERE удаляются все строки таблицы.
Рекомендации:
- Использовать WHERE для выборочного обновления и удаления.
- Применять транзакции BEGIN/COMMIT/ROLLBACK для групп операций, чтобы избежать потери данных.
- Оптимизировать SELECT с помощью индексов по часто используемым полям.
- Проверять изменения через SELECT перед массовым UPDATE или DELETE.
Транзакции и сохранение целостности данных
Основные команды для работы с транзакциями:
- BEGIN – начало транзакции.
- COMMIT – сохранение всех изменений, выполненных в рамках транзакции.
- ROLLBACK – отмена всех изменений до начала транзакции.
Применение транзакций:
- Обновление связанных таблиц: при изменении счета клиента и складского остатка оба действия выполняются атомарно.
- Групповые операции INSERT/UPDATE/DELETE, чтобы обеспечить согласованность данных.
- Восстановление после сбоев: транзакция предотвращает частичное выполнение и нарушение целостности.
Контроль целостности данных достигается через ключи и ограничения:
- PRIMARY KEY – уникальная идентификация записи.
- FOREIGN KEY – обеспечение ссылочной целостности между таблицами.
- UNIQUE – запрет дублирующихся значений в столбце.
- CHECK – проверка допустимых значений в поле.
- NOT NULL – обязательное заполнение поля.
Рекомендации:
- Оборачивать критические изменения в транзакции.
- Использовать ROLLBACK при ошибках для предотвращения некорректных данных.
- Минимизировать длительность транзакций, чтобы снизить блокировки и повысить производительность.
- Комбинировать ограничения и транзакции для комплексной защиты данных.
Резервное копирование и восстановление баз данных
Резервное копирование обеспечивает сохранность данных и возможность их восстановления при сбоях или ошибках. Основные типы резервных копий:
- Полное (Full Backup) – копируется вся база данных. Позволяет восстановить систему в конкретный момент времени.
- Инкрементное (Incremental Backup) – копируются только изменения с последнего полного или инкрементного бэкапа. Экономит место и время.
- Дифференциальное (Differential Backup) – копируются все изменения с момента последнего полного бэкапа.
Методы восстановления:
- Восстановление из полного бэкапа – загрузка всей базы из одного файла резервной копии.
- Комбинированное восстановление – использование полного бэкапа с последующими инкрементными или дифференциальными копиями для актуализации данных.
- Point-in-time recovery – восстановление базы до конкретного момента, используя журналы транзакций.
Рекомендации по организации бэкапов:
- Хранить копии на отдельном физическом носителе или в облаке.
- Регулярно проверять целостность бэкапов через тестовое восстановление.
- Использовать автоматизацию создания резервных копий с расписанием и ротацией файлов.
- Сохранять журналы транзакций для восстановления после сбоев между полными бэкапами.
- Разграничивать права доступа к бэкапам для предотвращения несанкционированного изменения.
Систематическое резервное копирование и проверка восстановления минимизируют риск потери данных и обеспечивают непрерывность работы базы.
Безопасность и контроль доступа к информации
Контроль доступа обеспечивает защиту данных от несанкционированного просмотра и изменений. Основные механизмы:
- Аутентификация – проверка пользователя через логин и пароль, двухфакторную аутентификацию или сертификаты.
- Ролевое управление доступом (RBAC) – назначение прав пользователям через роли: читатель, редактор, администратор. Позволяет централизованно управлять привилегиями.
- Привилегии на уровне таблиц и столбцов – SELECT, INSERT, UPDATE, DELETE задаются индивидуально для объектов базы данных.
- Шифрование данных – защита конфиденциальной информации при хранении (Transparent Data Encryption) и передаче (TLS/SSL).
- Аудит и логирование – запись всех действий пользователей для выявления несанкционированных операций и анализа безопасности.
Рекомендации:
- Применять принцип минимальных привилегий: пользователи получают только необходимые права.
- Регулярно обновлять учетные данные и использовать сложные пароли.
- Включать шифрование на уровне базы и соединений с сервером.
- Проводить аудит и анализ журналов изменений и доступа к данным.
- Ограничивать доступ к резервным копиям и обеспечивать их шифрование.
Системное применение этих мер снижает риск утечки, повреждения или потери информации и обеспечивает контроль за использованием данных.
Вопрос-ответ:
Что такое таблица в базе данных и из чего она состоит?
Таблица — это основная структура хранения данных в базе. Она состоит из строк и столбцов: строки представляют отдельные записи, а столбцы определяют поля с определёнными типами данных, например, числа, текст или даты. Каждая таблица должна иметь первичный ключ для уникальной идентификации записей.
Как устроены связи между таблицами?
Связи реализуются через внешние ключи. Например, поле customer_id в таблице заказов может ссылаться на id клиента в таблице клиентов. Это создаёт связь один ко многим, когда один клиент может иметь несколько заказов. Для связи многие ко многим используют промежуточную таблицу, которая содержит ссылки на обе связанные таблицы.
Как индексы влияют на скорость работы базы данных?
Индексы ускоряют поиск и сортировку данных, уменьшая количество операций чтения. B-Tree индексы подходят для диапазонных и сортировочных запросов, а хеш-индексы эффективны для точного поиска по ключу. Наличие индекса по колонке, используемой в WHERE или JOIN, позволяет выполнять запросы быстрее, особенно на больших таблицах.
Зачем нужны транзакции и как они поддерживают целостность данных?
Транзакции объединяют несколько операций в единый блок, который либо выполняется полностью, либо откатывается при ошибке. Это гарантирует, что данные остаются согласованными. Транзакции применяются для обновления связанных таблиц или массовых изменений, предотвращая частичное выполнение и нарушения ссылочной целостности.
Какие меры безопасности применяются для защиты базы данных?
Безопасность обеспечивается аутентификацией пользователей, ролевым управлением доступа, назначением привилегий на таблицы и столбцы, шифрованием данных и соединений, а также аудитом действий. Минимизация прав пользователей и регулярный анализ логов помогают предотвращать несанкционированный доступ и поддерживать контроль за использованием информации.
Что такое нормализация в базе данных и зачем она нужна?
Нормализация — это процесс организации таблиц и связей между ними для устранения дублирования данных и поддержания целостности. Например, вместо хранения информации о клиентах в каждой записи заказа создают отдельную таблицу клиентов и связывают её с заказами через внешний ключ. Это уменьшает количество повторяющихся данных, упрощает обновление и предотвращает ошибки при изменении информации.
Как выбираются типы данных для полей таблиц?
Тип данных выбирается исходя из характера информации и объёма значений. Числовые значения используют INTEGER или BIGINT, текст — VARCHAR с ограничением длины, дату и время — DATE или TIMESTAMP. Правильный выбор типа данных экономит память, ускоряет запросы и предотвращает ошибки при хранении информации, например, недопустимые символы или переполнение числового поля.