
Содержание статьи

В PHP строки представляют собой последовательности символов, каждая из которых доступна по индексу. Это позволяет обращаться к отдельным символам, изменять их и использовать их в вычислениях аналогично элементам массива. Например, $text[0] вернет первый символ строки, а $text[5] позволит заменить конкретный символ.
Для перебора строки можно применять циклы, такие как for или foreach, что облегчает выполнение операций над каждым символом: подсчет повторений, проверку наличия определенных символов или преобразование регистра. При этом длину строки определяет функция strlen(), а substr() позволяет извлекать подстроки без необходимости вручную рассчитывать диапазоны индексов.
Работа со строками как с массивами также включает возможность преобразования строки в массив символов с помощью str_split() и обратное соединение через implode(). Эти методы упрощают фильтрацию, сортировку и поиск внутри текста. Для строк с многобайтовыми символами, например UTF-8, рекомендуется использовать функции mb_strlen() и mb_substr(), чтобы избежать ошибок при работе с кириллицей или эмодзи.
Практическое применение этих подходов охватывает обработку пользовательского ввода, валидацию данных и генерацию динамического контента. Управление символами напрямую через индексы снижает нагрузку на систему при больших объемах текста и делает код более прозрачным, позволяя применять точечные изменения без создания дополнительных массивов.
Обращение к отдельным символам строки по индексу
В PHP каждый символ строки доступен через квадратные скобки с указанием индекса. Нумерация начинается с нуля: $string[0] вернет первый символ, $string[3] – четвертый. Отрицательные индексы позволяют обращаться с конца строки: $string[-1] возвращает последний символ.
Изменение символа по индексу производится напрямую, например, $string[2] = ‘a’; заменит третий символ. При этом важно учитывать длину строки через strlen(), чтобы избежать ошибок обращения за пределы диапазона.
Для безопасного доступа к символам рекомендуется проверять существование индекса через isset($string[$i]). Это предотвращает предупреждения при обработке динамических данных, полученных из внешних источников.
Обращение по индексу эффективно для простых операций: выборка конкретных символов, сравнение с заданными значениями, формирование новых строк. Для многобайтовых символов лучше использовать mb_substr($string, $i, 1), чтобы корректно работать с UTF-8 и избегать разделения символов на части.
Изменение символов строки через индекс
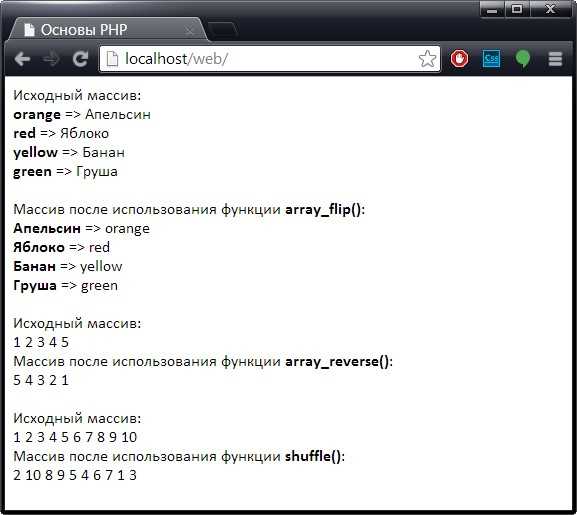
В PHP отдельные символы строки можно изменять напрямую через индекс. Это позволяет корректировать текст без создания новой строки полностью.
Основные правила и рекомендации:
- Для замены символа используйте присваивание: $string[2] = ‘A’; изменит третий символ.
- Проверяйте длину строки через strlen($string), чтобы индекс не выходил за пределы.
- Отрицательные индексы не поддерживаются для присваивания; они работают только для чтения.
- Для многобайтовых символов применяйте mb_substr() с конкатенацией:
$string = mb_substr($string, 0, $i) . ‘символ’ . mb_substr($string, $i+1);
Применение замены символов удобно при:
- Изменении регистра отдельных букв.
- Фильтрации нежелательных символов из строки.
- Формировании новых строк с минимальной нагрузкой на память.
- Обработке больших текстов по символам без использования массивов.
Прямое присваивание символов ускоряет обработку и делает код компактным. Для динамических данных важно всегда проверять существование индекса, чтобы избежать предупреждений PHP.
Перебор строки с помощью цикла foreach
В PHP строки можно рассматривать как массивы символов после преобразования через str_split(). Это позволяет использовать foreach для последовательной обработки каждого символа.
Пример базового перебора:
| Код | Описание |
|---|---|
| $string = «PHP»; $chars = str_split($string); foreach ($chars as $char) { echo $char; } |
Рекомендации при использовании foreach:
| Совет | Применение |
|---|---|
| Использовать str_split() для строк с латиницей и цифрами | Обеспечивает корректный перебор символов без ошибок |
| Для UTF-8 применять mb_str_split() | Предотвращает разделение многобайтовых символов |
| Внутри цикла можно изменять элементы массива и собирать новую строку через implode() | Позволяет модифицировать текст без изменения исходной строки |
| Проверять пустые строки перед перебором | Избегает предупреждений и ошибок выполнения |
Использование foreach упрощает фильтрацию, подсчет символов и замену отдельных элементов, делая код читаемым и структурированным при работе с текстовыми данными.
Использование функций strlen и substr для работы с частями строки
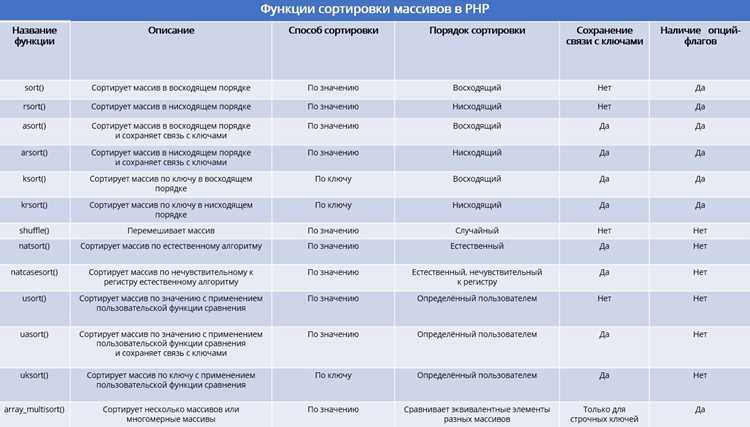
Функция strlen() возвращает длину строки в символах. Она необходима для контроля индексов при обращении к отдельным символам и при использовании substr(). Пример: $length = strlen($string); позволит определить, сколько символов доступно для обработки.
substr() используется для извлечения подстрок. Синтаксис: substr($string, $start, $length), где $start – начальный индекс, а $length – количество символов. Отрицательные значения $start или $length позволяют работать с концом строки. Например, substr($string, -3, 2) вернет два символа, начиная с третьего с конца.
Практические рекомендации:
- Всегда проверяйте, что $start и $length не превышают длину строки через strlen().
- Для работы с UTF-8 используйте mb_strlen() и mb_substr(), чтобы избежать разбиения многобайтовых символов.
- substr() можно комбинировать с циклом или массивными операциями, чтобы обрабатывать текст блоками по N символов.
- Используйте отрицательные индексы для удобного извлечения символов с конца строки без вычисления длины вручную.
Функции strlen и substr позволяют безопасно и точно работать с частями строки, делая возможными выборку, замену и анализ отдельных сегментов текста.
Проверка наличия символа и его позиции в строке
В PHP для поиска символа или подстроки используют функции strpos() и strrpos(). strpos($string, $char) возвращает индекс первого вхождения символа, а strrpos($string, $char) – последнего. Если символ не найден, функция возвращает false.
Рекомендации при работе с позициями символов:
- Используйте строгую проверку !== false, чтобы корректно различать ноль (первый символ) и отсутствие символа.
- Для многобайтовых строк применяйте mb_strpos() и mb_strrpos(), чтобы избежать ошибок при UTF-8.
- Если требуется проверка наличия без индекса, str_contains($string, $char) возвращает true или false, упрощая условия.
- Комбинируйте с substr() для извлечения частей строки после найденного символа или для замены конкретного участка.
Эти методы позволяют точно определить расположение символов, фильтровать текст и выполнять операции замены или анализа конкретных участков строки.
Конвертация строки в массив символов и обратно
Для работы с отдельными символами строки удобно преобразовать её в массив. Функция str_split($string) разбивает строку на массив, где каждый элемент – один символ. Для многобайтовых строк применяется mb_str_split($string), чтобы корректно обрабатывать UTF-8.
Обратное преобразование выполняется через implode(», $array), что собирает массив символов обратно в строку.
Практические советы при конвертации:
- Используйте str_split() для коротких строк с латиницей и цифрами.
- Для кириллицы и эмодзи применяйте mb_str_split() с указанием кодировки.
- Проверяйте, что массив содержит только символы, прежде чем применять implode(), чтобы избежать лишних разделителей.
- Конвертация в массив облегчает фильтрацию, сортировку и замену отдельных символов с сохранением исходного порядка.
Пример применения:
- Разбить строку на символы: $chars = str_split($text);
- Изменить конкретные символы по индексу: $chars[2] = ‘A’;
- Собрать обратно в строку: $newText = implode(», $chars);
Этот подход повышает точность операций над символами и упрощает обработку текстовых данных, особенно при динамическом формировании или редактировании строк.
Обработка многобайтовых символов в строках

Стандартные функции работы со строками в PHP, такие как strlen(), substr() и обращение по индексу, не учитывают многобайтовые символы. Это приводит к некорректному вычислению длины и разбиению символов UTF-8.
Для корректной обработки используйте многобайтовые функции из расширения mbstring:
- mb_strlen($string, ‘UTF-8’) – возвращает количество символов, учитывая многобайтовые кодировки.
- mb_substr($string, $start, $length, ‘UTF-8’) – извлекает подстроку_
Вопрос-ответ:
Как получить конкретный символ строки по его позиции в PHP?
В PHP строки можно рассматривать как массивы символов. Для доступа к конкретному символу используется синтаксис $string[index], где index — номер символа, начиная с нуля. Например, $string[0] вернет первый символ строки. Для отрицательных индексов работает только чтение с конца строки, например, $string[-1] возвращает последний символ.
Можно ли изменять отдельные символы строки через индекс?
Да, строку можно изменять по индексу. Присваивание $string[2] = ‘A’; заменит третий символ. Перед этим рекомендуется проверять длину строки с помощью strlen(), чтобы не выходить за границы. Для многобайтовых символов, таких как кириллица или эмодзи, следует использовать mb_substr() и конкатенацию, иначе символ может быть поврежден.
Как безопасно перебирать все символы строки в PHP?
Прямой перебор через foreach работает только с массивами. Чтобы применить foreach к строке, сначала разбейте её на массив символов с помощью str_split($string) или mb_str_split($string) для UTF-8. После этого можно обрабатывать каждый символ отдельно, например, для фильтрации, подсчета или замены.
В чем разница между strlen() и mb_strlen() при работе с текстом?
Функция strlen() возвращает длину строки в байтах, а не символах, что приводит к некорректной работе с многобайтовыми символами UTF-8. Функция mb_strlen($string, ‘UTF-8’) считает именно символы, корректно обрабатывая кириллицу, эмодзи и другие символы, занимающие более одного байта.
Как преобразовать строку в массив символов и собрать обратно в строку?
Для преобразования используйте str_split($string) для стандартных строк или mb_str_split($string) для многобайтовых. Это создаст массив, элементы которого — отдельные символы. После обработки массива, например, изменения или фильтрации, соберите строку обратно через implode(», $array), чтобы получить исходный текст с внесенными изменениями.
Как корректно работать с UTF-8 символами при обращении к строке как к массиву?
При работе с UTF-8 обычное обращение к строке по индексу через $string[i] или функции strlen() и substr() может привести к разрыву символов, так как один символ может занимать несколько байт. Для корректной работы используйте функции из расширения mbstring: mb_strlen($string, ‘UTF-8’) для определения длины строки в символах, mb_substr($string, $start, $length, ‘UTF-8’) для извлечения подстрок и mb_str_split($string, 1, ‘UTF-8’) для преобразования строки в массив символов. После обработки массив можно собрать обратно через implode(), чтобы сохранить целостность текста.





