Содержание статьи

Работа с индексами в pandas напрямую влияет на доступ к данным, сбор выборок и выполнение группировок. Нередко после фильтрации, объединения таблиц или импорта набор получает разрозненные или неподходящие индексы. В таких ситуациях требуется их обновление, чтобы упростить дальнейшие операции и исключить ошибки при обращении к строкам.
В процессе анализа данные могут менять структуру: строки удаляются, сортируются, преобразуются. pandas предоставляет несколько способов перераспределения и переназначения индексов – от простого сброса до построения многоуровневых схем. Каждый подход решает конкретные задачи: восстановление последовательности, подготовка набора к слиянию, перенос служебного столбца в индекс.
При корректной работе с индексами снижается риск конфликтов при объединении таблиц, ускоряется поиск нужных элементов и упрощается контроль над структурой набора. В тексте далее рассматриваются практические приёмы, которые применяются в типичных рабочих сценариях: обработка результата фильтрации, формирование нового набора после импорта, перенастройка уровня индексирования.
Сброс индекса с сохранением исходных данных
Сброс индекса через DataFrame.reset_index(drop=False) позволяет перевести текущий индекс в обычный столбец. Такой подход полезен, когда индекс содержит значения, которые требуется сохранить для последующих вычислений, сортировки или проверки уникальности.
При выполнении reset_index() без параметра drop=True создаётся новый числовой индекс, а прежние значения переносятся в отдельный столбец. Это упрощает анализ исторических идентификаторов, которые ранее использовались как ключи, и позволяет избежать потери данных при дальнейших преобразованиях.
После сброса индекса удобно выполнять группировку, объединение таблиц или пересчёт показателей, где требуется доступ к прежнему порядку строк. Если старый индекс содержит названия дат или категорий, его перенос в столбец помогает использовать эти значения в фильтрации или построении выборок.
Перенос столбца в индекс и возврат обратно
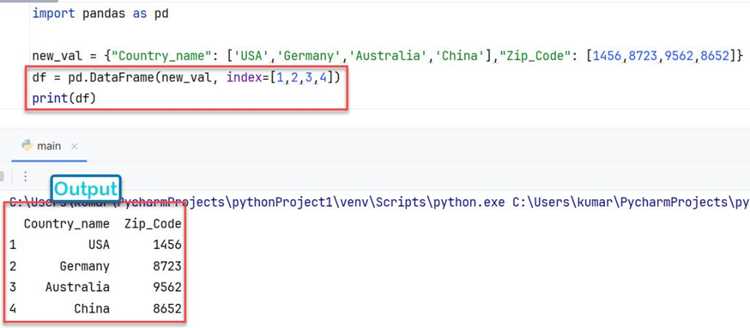
Перенос значений столбца в индекс применяется, когда требуется ускорить обращение к строкам или использовать колонку как ключ при группировках и выборках. Для этого используется метод set_index(), который позволяет назначить один или несколько столбцов в качестве индексирующей структуры.
- Для переноса используется вызов df.set_index(«column»), который формирует новый индекс на основе выбранного столбца.
- При необходимости сохранить исходный столбец следует указать параметр drop=False, чтобы он остался в наборе данных.
- Если ключи должны быть уникальными, рекомендуется предварительно проверить данные через df[«column»].is_unique.
Возврат индекса обратно в столбец выполняется через reset_index(). Эта операция удобна, когда индекс перестал быть ключевой частью набора или требуется подготовить таблицу к объединению.
- Вызов df.reset_index() переносит текущий индекс в новый столбец.
- Если индекс не нужен, его можно удалить параметром drop=True.
- При многоуровневом индексе все уровни возвращаются в отдельные столбцы, что позволяет выполнять дальнейшие расчёты без ограничений.
Обновление индекса после фильтрации строк

После применения условия фильтрации DataFrame сохраняет исходные метки строк. Это приводит к пропускам в индексе, что осложняет последующие операции, особенно при слиянии наборов или формировании последовательных выборок. Для устранения разрывов используется команда reset_index(drop=True), создающая новую последовательность без сохранения предыдущих значений.
Если требуется анализировать прежние позиции строк, допустимо использовать reset_index(drop=False). В этом случае старые метки попадают в столбец, что удобно для контроля изменений или сопоставления с другой таблицей. Такой перенос помогает выявить элементы, исключённые фильтром, и восстановить связи между выборками.
При работе с временными рядами индекс часто содержит даты. После фильтрации по диапазону параметр drop=False позволяет сохранить исходные отметки времени, не нарушая их целостность. Это полезно при построении графиков или применении агрегирующих функций, где требуется корректная временная шкала.
Назначение пользовательских индексов на основе списка или массива
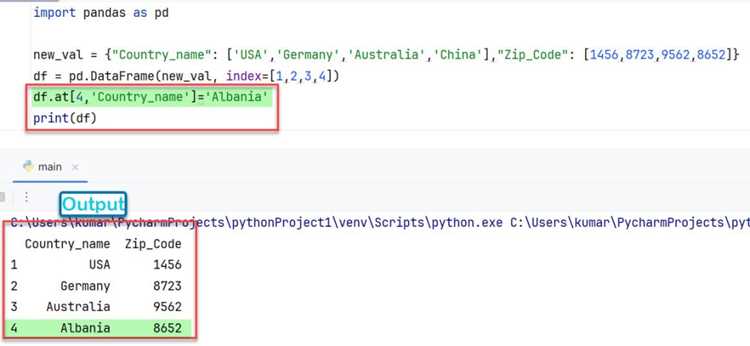
Переопределение индекса вручную используется, когда требуется задать строгий порядок строк или установить собственные ключи. Источник значений может быть списком, массивом NumPy или результатом вычисления внутри DataFrame.
- Для прямого назначения применяется выражение df.index = custom_list, где длина списка должна совпадать с числом строк.
- Если элементы индекса формируются динамически, удобно использовать np.arange() или генераторы, чтобы задать последовательность без пропусков.
- При создании текстовых ключей полезно предварительно проверить уникальность значений через pd.Index(custom_list).is_unique, чтобы избежать конфликтов при обращении к строкам.
Пользовательские индексы удобны при моделировании временных шкал, управлении группами строк или подготовке данных к последующим объединениям. Чётко заданные метки упрощают навигацию по таблице и позволяют точнее контролировать структуру набора.
- Создать список или массив, соответствующий числу строк.
- Передать последовательность в df.index для замены стандартного индекса.
- Проверить корректность структуры через df.head() и убедиться, что новые ключи отображаются без дубликатов.
Переименование существующих индексов в DataFrame
Переименование индексов применяется, когда требуется заменить текущие метки на более информативные или привести их к единому формату. Для точечного изменения отдельных значений используется метод rename(), позволяющий передать словарь соответствий между старыми и новыми метками.
Если нужно изменить название уровня индекса, а не его значения, применяется параметр df.index.name. Это удобно при работе с временными рядами и наборами, где индекс играет роль ключевого поля. Новое имя улучшает читаемость структуры и помогает при экспорте данных.
Массовое переименование всех меток выполняется через присвоение новой последовательности: df.index = new_index. Длина указанной последовательности должна совпадать с числом строк, иначе возникнет ошибка сопоставления. Такой способ подходит, когда требуется полностью перенастроить структуру меток без изменения содержимого таблицы.
Создание многоуровневого индекса и его обновление

Многоуровневый индекс (MultiIndex) позволяет структурировать DataFrame по нескольким уровням, что облегчает группировку и агрегирование. Для его создания используется метод set_index() с передачей списка столбцов: df.set_index([«level1», «level2»]). Каждый уровень хранит отдельный набор меток, что упрощает фильтрацию по комбинациям значений.
Обновление многоуровневого индекса может потребоваться после фильтрации или объединения таблиц. Для корректного восстановления последовательности используют reset_index(), который возвращает все уровни в столбцы, или reindex() с новым списком комбинаций, чтобы подстроить структуру под новые данные.
При добавлении нового уровня индексирования рекомендуется проверять уникальность каждой комбинации через df.index.is_unique. Если дубликаты существуют, их можно устранить через агрегацию или добавление дополнительного ключа. Такой подход обеспечивает точные выборки, корректные расчёты агрегатных функций и упрощает визуализацию данных.
Корректировка индекса после объединения DataFrame
При объединении двух и более DataFrame с помощью concat или merge исходные индексы сохраняются, что может привести к дублированию меток и некорректной последовательности строк. Для устранения этих проблем используется reset_index(drop=True), создающий новый непрерывный индекс.
Иногда необходимо сохранить исходные индексы для анализа источника данных. В этом случае можно использовать параметр keys в concat, который создаёт многоуровневый индекс. Пример:
| DataFrame | Индекс после объединения |
|---|---|
| df1 | 0, 1, 2 |
| df2 | 0, 1, 2 |
| Объединение с keys=[‘A’,’B’] |
(A,0), (A,1), (A,2), (B,0), (B,1), (B,2) |
После объединения важно проверить целостность индекса через df.index.is_unique. Если требуется дальнейшая последовательная нумерация, лучше применить reset_index(drop=True), что позволит выполнять фильтрацию, выборку и агрегирование без конфликтов.
Автоматическое формирование индекса при чтении данных

При импорте данных с помощью pandas методы read_csv, read_excel и другие автоматически формируют числовой индекс, если не указан конкретный столбец для использования в качестве ключа. По умолчанию создаётся последовательность от 0 до N-1, где N – количество строк.
Для задания пользовательского индекса при чтении используют параметр index_col. Например, pd.read_csv(«data.csv», index_col=»ID») назначит столбец «ID» индексом DataFrame. Это позволяет сразу работать с уникальными идентификаторами без дополнительного сброса или переназначения индекса.
Если данные содержат даты или категории, рекомендуется использовать parse_dates для временных меток и dtype для категориальных полей. Такой подход обеспечивает корректное построение индекса и ускоряет фильтрацию, группировку и выборку по ключевым значениям.
Вопрос-ответ:
Почему после фильтрации DataFrame индекс становится разреженным, и как это исправить?
После фильтрации строки сохраняют исходные метки, что создаёт разрывы в индексе. Для восстановления последовательности используют reset_index(drop=True), который создаёт новый непрерывный числовой индекс, или reset_index(drop=False), если нужно сохранить старые метки в столбце для последующего анализа.
Как перенести столбец в индекс и зачем это может понадобиться?
Метод set_index() позволяет назначить один или несколько столбцов в качестве индекса. Это ускоряет выборку данных по ключу и упрощает группировку. Если требуется сохранить исходный столбец, используют параметр drop=False, чтобы он остался в таблице. Возврат к обычному столбцу выполняется через reset_index().
Можно ли задать индекс вручную при чтении CSV файла?
Да. Параметр index_col в pd.read_csv() позволяет сразу назначить столбец в качестве индекса. Это исключает необходимость последующего переназначения и обеспечивает корректную фильтрацию и группировку по уникальным идентификаторам. Для временных меток можно дополнительно использовать parse_dates.
Что делать, если после объединения нескольких DataFrame индексы дублируются?
При объединении с concat или merge старые индексы сохраняются, что приводит к повторяющимся меткам. Для корректной работы используют reset_index(drop=True), создающий новый непрерывный индекс. При необходимости сохранить источник данных применяют параметр keys в concat, создавая многоуровневый индекс.
Как изменить существующие метки индекса на более информативные?
Для замены отдельных значений используется метод rename() с передачей словаря старых и новых меток. Чтобы изменить имя уровня индекса, применяют df.index.name. Если требуется полностью заменить все метки, используют присвоение новой последовательности через df.index = new_index, соблюдая совпадение длины с количеством строк.
Как правильно сбросить индекс после фильтрации DataFrame, чтобы сохранить старые метки?
После фильтрации строки сохраняют исходные позиции, что создаёт разрывы в индексе. Чтобы сохранить старые метки, используют reset_index(drop=False). Старый индекс переносится в отдельный столбец, а новые позиции назначаются автоматически. Это позволяет сохранить связь с исходными данными при анализе или объединении таблиц.
Когда имеет смысл назначать пользовательский индекс вручную, и как это сделать?
Пользовательский индекс полезен, когда требуется управлять порядком строк, использовать уникальные идентификаторы или подготовить набор к объединению. Для этого создают список или массив значений длиной, равной числу строк, и присваивают его через df.index = custom_list. Перед этим желательно проверить уникальность элементов через pd.Index(custom_list).is_unique во избежание дублирующихся меток.