Содержание статьи

При работе с чужим кодом или устаревшими проектами часто возникает необходимость быстро понять, что именно выполняет конкретный фрагмент. Определение задачи кода начинается с анализа входных и выходных данных: важно зафиксировать типы переменных, структуру данных и возможные значения аргументов функции. Это позволяет формализовать ожидания от работы кода и выявить его роль в общей программе.
Следующий шаг – исследование логики и последовательности операций. Разбор операторов присваивания, условий и циклов помогает понять, какие вычисления происходят и какие промежуточные результаты формируются. Наблюдение за порядком выполнения функций и обработкой исключений позволяет составить карту действий, которую выполняет фрагмент.
Особое внимание стоит уделить внешним зависимостям. Подключаемые библиотеки, вызовы API или использование вспомогательных функций существенно влияют на конечное поведение кода. Фиксация всех таких связей позволяет определить границы ответственности фрагмента и понять, какие данные он изменяет или возвращает.
Для закрепления понимания полезно составить краткое текстовое описание выполняемой задачи, включающее входные данные, алгоритмы обработки и ожидаемые результаты. Такой подход ускоряет работу с кодом, облегчает его рефакторинг и снижает риск ошибок при интеграции в более крупные системы.
Как определить входные и выходные данные кода
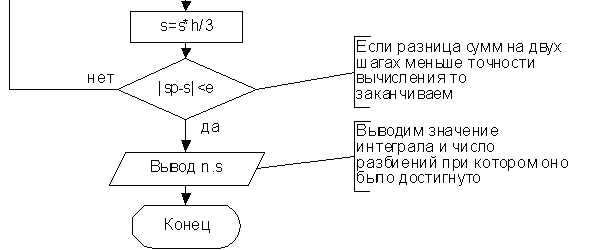
Первый шаг анализа кода – выявление всех параметров функции и переменных, используемых на старте выполнения. Необходимо записать типы данных, диапазоны значений и возможные структуры, например массивы, словари или объекты. Если функция принимает сложные объекты, стоит отметить ключевые поля, которые реально влияют на логику.
Для входных данных полезно проследить точки, где они формируются или передаются в код. Это может быть пользовательский ввод, файлы, данные из базы или результаты других функций. Фиксация источников позволяет понять ограничения и предусмотреть варианты некорректных значений.
Выходные данные фиксируются по результату работы кода: возвращаемые значения функций, модифицируемые переменные и побочные эффекты, например запись в файл или изменение состояния объекта. Рекомендуется проверять типы и структуру выходных данных на нескольких тестовых примерах, чтобы убедиться, что они соответствуют ожидаемой задаче фрагмента.
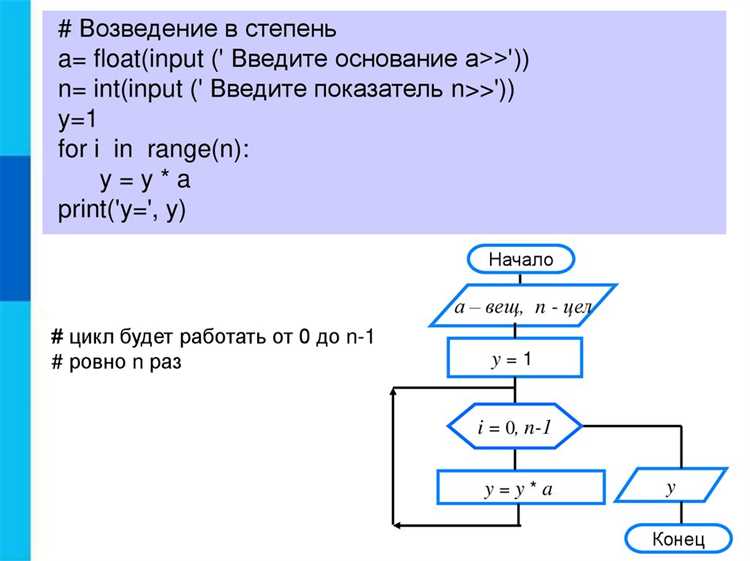
Если код использует промежуточные вычисления, стоит выделить ключевые точки, где значения можно замерить или вывести для контроля. Это ускоряет понимание того, как входные данные преобразуются и какие части кода отвечают за формирование конкретного результата.
Фиксирование всех этих деталей в виде схемы или списка облегчает дальнейший анализ алгоритмов, выявление ошибок и интеграцию фрагмента в более крупный проект.
Выявление используемых алгоритмов и структур данных
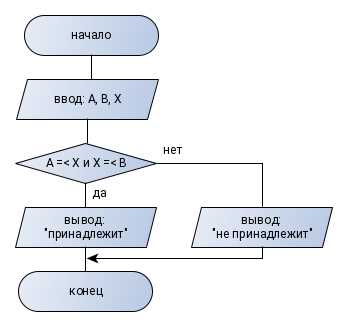
Для точного понимания кода необходимо определить, какие алгоритмы применяются для обработки данных. Сначала следует проследить последовательность действий: сортировка, фильтрация, агрегация или поиск. Если используются циклы с вложенными условиями, важно определить, повторяются ли операции с разными элементами коллекции и как это влияет на результат.
Определение структур данных требует анализа типов переменных и их взаимодействия. Массивы, списки и словари указывают на последовательное или ассоциативное хранение данных, множества – на работу с уникальными элементами. Связанные списки, деревья или графы сигнализируют о более сложных операциях поиска и обхода.
Рекомендуется отметить, какие структуры данных изменяются, а какие используются только для чтения. Это помогает выявить алгоритмы модификации данных, такие как вставка, удаление, слияние или пересортировка, и понять их влияние на производительность и результат.
Следует проверять наличие рекурсивных вызовов или функций высшего порядка, которые применяют алгоритмы к подмножествам данных. Выделение таких элементов упрощает формализацию задачи, выполняемой кодом, и ускоряет процесс написания тестов для проверки корректности работы алгоритмов.
Фиксирование всех этих наблюдений в виде схемы или комментариев внутри кода помогает систематизировать понимание алгоритмов и структур данных, облегчая дальнейший анализ и модификацию фрагмента.
Анализ логики и последовательности операций
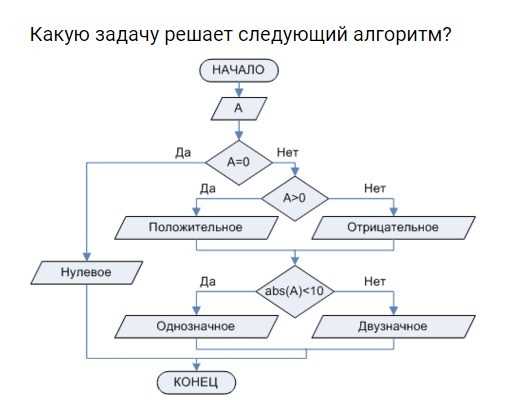
Анализ кода начинается с разборки порядка выполнения операторов. Необходимо проследить, какие действия происходят последовательно, а какие зависят от условий или циклов. Это позволяет определить цепочку вычислений и понять, как формируются промежуточные результаты.
Особое внимание стоит уделить условным конструкциям: if, switch или тернарным операторам. Важно зафиксировать, при каких значениях входных данных выполняются те или иные ветви, и какие значения изменяются на выходе. Это помогает выявить скрытую логику и сценарии обработки исключительных случаев.
Циклы требуют отдельного анализа: нужно определить, сколько раз повторяются действия, на каких данных и как меняется состояние переменных внутри каждого прохода. Важно различать циклы с фиксированным числом итераций и зависимые от значений условий, так как это влияет на конечный результат и производительность кода.
Следует отметить точки вызова функций и порядок их выполнения относительно основного потока. Это помогает понять, какие операции делегируются внешним блокам кода, и какие результаты возвращаются для дальнейшей обработки.
Фиксирование логики в виде схемы или комментариев позволяет визуализировать последовательность действий, облегчает поиск ошибок и ускоряет интерпретацию поведения фрагмента при изменении входных данных.
Поиск условий и циклов для понимания поведения кода

Для точного понимания работы кода важно выявить все условные конструкции и циклы, которые определяют поток выполнения. Это позволяет проследить, какие действия выполняются при различных значениях входных данных и как изменяется состояние переменных.
Рекомендуется использовать последовательность действий:
- Просмотреть все if, else, switch и тернарные операторы, зафиксировать проверяемые условия и возможные ветви исполнения.
- Определить циклы: for, while, do-while, и записать условия их завершения и зависимости от переменных.
- Выявить вложенные условия и циклы, чтобы понять, какие блоки кода выполняются только при сочетании нескольких условий.
- Отметить любые ранние выходы из функций или циклов (return, break, continue), которые изменяют последовательность операций.
- Проверить влияние условий и циклов на модификацию ключевых переменных и формирование выходных данных.
Дополнительно полезно строить схемы или диаграммы потока, отмечая точки ветвления и повторения. Это помогает визуализировать возможные сценарии выполнения и выявить участки, где ошибки или неожиданные значения могут изменить поведение кода.
Определение зависимости от внешних библиотек и функций
Следует проследить, какие данные передаются во внешние функции и какие результаты возвращаются. Это позволяет определить, насколько фрагмент кода автономен и какие внешние компоненты критичны для его работы.
Рекомендуется обратить внимание на побочные эффекты внешних вызовов: изменения глобальных переменных, запись в файлы, сетевые запросы или доступ к базе данных. Такие зависимости формируют скрытые ограничения и влияют на поведение кода при интеграции в другую среду.
Полезно составить список всех внешних зависимостей с указанием конкретных функций и ожидаемых результатов. Это облегчает тестирование кода, позволяет выявить потенциальные ошибки при обновлении библиотек и ускоряет процесс модификации фрагмента.
Для сложных проектов рекомендуется использовать автоматизированные инструменты анализа зависимостей, которые позволяют быстро визуализировать связи между кодом и внешними модулями, выявляя критические точки для проверки и оптимизации.
Составление краткого описания выполняемой задачи
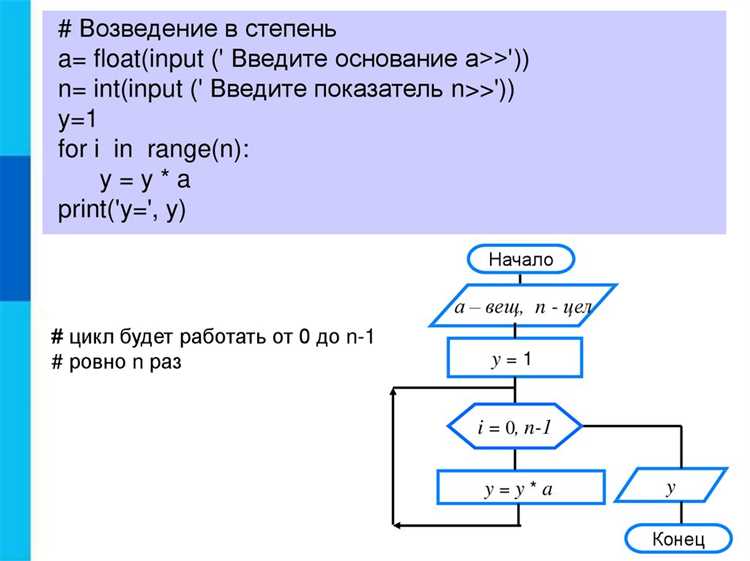
Рекомендуется структурировать информацию в виде таблицы, чтобы быстро зафиксировать ключевые элементы:
| Элемент | Описание |
|---|---|
| Входные данные | Типы и структура параметров, диапазоны значений, источники данных |
| Алгоритмы | Основные операции: сортировка, фильтрация, вычисления, обработка коллекций |
| Условия и циклы | Ветвления и повторяющиеся действия, влияющие на формирование результата |
| Выходные данные | Возвращаемые значения, модифицируемые объекты, побочные эффекты |
| Внешние зависимости | Подключаемые библиотеки, вызовы сторонних функций, сетевые запросы |
Такой формат позволяет быстро оценить назначение фрагмента, выявить критические точки и упростить документирование кода. Таблица служит основой для тестов и дальнейшего анализа, облегчая интеграцию и рефакторинг.
Вопрос-ответ:
Как определить, какие переменные во фрагменте кода являются входными, а какие создаются внутри?
Для идентификации входных и локальных переменных стоит просмотреть список аргументов функции или точки, где данные передаются в фрагмент. Переменные, которые получают значения извне или через параметры, являются входными. Все остальные, которые инициализируются внутри блока кода и используются только там, считаются локальными. Практически полезно составить таблицу с именами переменных, их типами и источниками данных, чтобы сразу видеть границы влияния каждого элемента.
Какие методы помогают понять, какой алгоритм применён в коде?
Начните с анализа структуры кода: если присутствуют циклы и условия, обратите внимание на последовательность обработки данных. Проверяйте, используются ли стандартные функции сортировки, поиска или фильтрации. Отдельно фиксируйте любые рекурсивные вызовы и применение функций высшего порядка, так как они часто скрывают сложные алгоритмы. Для наглядности полезно создавать схемы действий с пометкой ключевых вычислений и изменений переменных.
Как понять, как внешние библиотеки влияют на работу фрагмента кода?
Сначала необходимо зафиксировать все импорты и подключаемые модули. Для каждой функции из внешней библиотеки следует определить, какие значения она получает и что возвращает. Обратите внимание на побочные эффекты: изменение глобальных переменных, запись в файлы, обращения к базе данных или сетевые вызовы. Ведение списка всех таких зависимостей позволяет понять, какие элементы кода не будут работать автономно и где могут возникнуть ошибки при изменении версии библиотеки.
Как составить краткое описание задачи кода, чтобы им было удобно пользоваться при тестировании?
Лучше всего оформлять описание в виде таблицы с отдельными колонками для входных данных, алгоритмов обработки, условий и циклов, выходных значений и внешних зависимостей. Каждая строка фиксирует конкретный элемент и его поведение. Такой подход позволяет при тестировании быстро проверять, какие входные значения привести, какие промежуточные состояния контролировать и что должно вернуться на выходе.
Почему важно фиксировать точки изменения переменных в циклах и условиях?
Циклы и условные конструкции могут многократно изменять состояние переменных, и именно эти изменения формируют итоговый результат. Если не зафиксировать, какие значения переменных меняются на каждом шаге, легко пропустить ошибку или неправильно интерпретировать поведение кода. Для контроля удобно отмечать эти точки прямо в комментариях или строить визуальную схему, показывающую последовательность и зависимость изменений.
Как проверить, какие части фрагмента кода зависят от значений внешних данных и как это влияет на понимание выполняемой задачи?
Для проверки зависимости от внешних данных следует проследить все точки, где фрагмент получает значения извне: аргументы функций, файлы, базы данных или результаты других модулей. Каждое использование таких данных необходимо зафиксировать, отмечая, какие переменные получают значения и как они влияют на выполнение операций внутри кода. Это позволяет понять, какие части фрагмента работают автономно, а какие строго зависят от конкретных входных значений. Также важно проверить, как изменения этих данных могут изменить результат: например, при изменении структуры входного массива или отсутствии некоторых полей объекта поведение кода может кардинально измениться. Фиксирование этих зависимостей помогает точно описать задачу фрагмента и определить возможные сценарии тестирования.