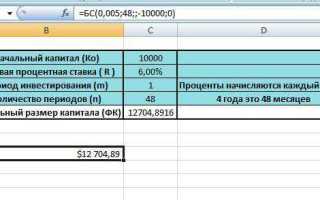
Коэффициент корреляции Пирсона (r) измеряет линейную зависимость между двумя переменными в диапазоне от -1 до 1. Значение 0,7–0,9 указывает на сильную положительную связь, -0,7–-0,9 – на сильную отрицательную, а -0,3–0,3 – на отсутствие значимой зависимости. В Excel расчет выполняется за 3 шага с использованием функции =КОРРЕЛ(массив1; массив2), но для корректной интерпретации результатов требуется предварительная проверка данных.
Для анализа значимости результата используйте t-критерий Стьюдента по формуле:
t = r * √((n-2)/(1-r²)),
где n – объем выборки. Сравните полученное значение с критическим из таблицы Стьюдента при уровне значимости α=0,05. Если |t| > t_крит, корреляция статистически значима. В Excel это реализуется через =СТЬЮДЕНТ.РАСП.2Х.
Пример: для выборки из 30 пар значений с r=0,6 расчетное t составит 4,02, что превышает критическое значение 2,05 (для df=28). Это подтверждает значимость связи. Не игнорируйте проверку гипотез – без нее коэффициент остается лишь числом без доказательной базы.
Подготовка данных для анализа корреляции в Excel
Корректный расчет коэффициента корреляции начинается с проверки структуры данных. В Excel данные должны быть организованы в виде двух столбцов (или строк) без пропусков и текстовых значений. Например, если анализируются зависимости между «Продажи» и «Рекламный бюджет», оба набора данных должны содержать только числовые значения в формате Общий или Числовой. Пустые ячейки или текст (например, «N/A») приведут к ошибке при использовании функции =КОРРЕЛ().
Перед анализом удалите выбросы – значения, резко отличающиеся от остальных. Для этого используйте инструмент Условное форматирование → Правила выделения ячеек → Другие правила → Формула с условием, например, =ABS(A2-СРЗНАЧ($A$2:$A$100))>3*СТАНДОТКЛОН($A$2:$A$100). Выбросы искажают корреляцию: один аномальный результат может изменить коэффициент на 0,2–0,3 пункта.
- Преобразуйте категориальные данные в числовые. Например, пол («Мужской»/»Женский») замените на 1/0 или используйте
=ЕСЛИ(B2="Мужской";1;0). Для многоуровневых категорий (например, «Низкий/Средний/Высокий») примените кодирование dummy-переменными: создайте отдельные столбцы для каждого уровня с бинарными значениями. - Проверьте распределение данных. Если одна из переменных имеет логнормальное распределение (например, доходы), примените логарифмирование:
=LN(A2). Это снизит влияние экстремальных значений и приблизит распределение к нормальному, что важно для линейной корреляции Пирсона.
Убедитесь, что данные синхронизированы по времени или объектам. Если анализируются ежемесячные продажи и температура, даты в обоих столбцах должны совпадать. При несовпадении используйте =ВПР() или =ИНДЕКС()+ПОИСКПОЗ() для сопоставления. Например: =ИНДЕКС($C$2:$C$100;ПОИСКПОЗ(A2;$B$2:$B$100;0)), где A2 – дата из первого набора, а B2:B100 – даты второго.
Для больших массивов (более 10 000 строк) оптимизируйте данные: удалите дубликаты через Данные → Удалить дубликаты и отключите автопересчет формул (Формулы → Параметры вычислений → Вручную). Это ускорит работу функции КОРРЕЛ(), которая при больших объемах данных может замедлять Excel. Также рассмотрите возможность использования надстройки Анализ данных (включается через Файл → Параметры → Надстройки), где есть готовый инструмент «Корреляция».
Сохраните подготовленные данные в отдельном листе с именем «Очищенные данные» и зафиксируйте изменения в журнале: укажите дату, удаленные выбросы, примененные преобразования. Это упростит повторный анализ и позволит отследить влияние подготовки на итоговый коэффициент. Например, если после логарифмирования корреляция изменилась с 0,45 до 0,62, это свидетельствует о нелинейной зависимости в исходных данных.
Выбор функции для расчета коэффициента корреляции Пирсона
Функция КОРРЕЛ требует два аргумента: массивы числовых данных. Например, =КОРРЕЛ(A2:A100; B2:B100) рассчитает коэффициент для диапазонов A2:A100 и B2:B100. Важно учитывать ограничения:
- Диапазоны должны содержать одинаковое количество значений.
- Пустые ячейки или текстовые данные игнорируются, но приводят к некорректным результатам, если их доля превышает 10–15%.
- Функция возвращает ошибку
#ДЕЛ/0!, если один из массивов содержит только нули или константы.
Для анализа нескольких пар переменных одновременно используйте инструмент «Анализ данных» (надстройка «Пакет анализа»). Он позволяет получить матрицу корреляций за один шаг, избегая ручного ввода формул для каждой пары. Активируйте надстройку через Файл → Параметры → Надстройки → Пакет анализа, затем выберите Анализ данных → Корреляция. Укажите входной диапазон и выходной интервал – результат будет представлен в виде таблицы с коэффициентами для всех комбинаций столбцов.
Использование функции КОРРЕЛ для вычисления р в Excel

Функция КОРРЕЛ в Excel вычисляет коэффициент корреляции Пирсона (ρ) между двумя наборами данных. Синтаксис: =КОРРЕЛ(массив1; массив2), где массив1 и массив2 – диапазоны ячеек с числовыми значениями. Например, если данные по переменной X находятся в ячейках A2:A10, а по Y – в B2:B10, формула примет вид =КОРРЕЛ(A2:A10; B2:B10). Результат варьируется от -1 до 1: значения близкие к 1 указывают на сильную положительную связь, к -1 – на сильную отрицательную, а 0 – на отсутствие линейной зависимости.
Перед применением функции убедитесь, что данные не содержат пустых ячеек или текста – это приведет к ошибке #Н/Д. Если массивы имеют разную длину, Excel вернет ошибку #ЗНАЧ!. Для корректной работы функции также важно исключить выбросы: одно аномальное значение может исказить результат. Например, при анализе зависимости между расходами на рекламу и продажами удалите данные за периоды с нетипичными показателями (сезонные всплески, форс-мажоры).
Функция КОРРЕЛ игнорирует логические значения и текст в диапазонах, но учитывает нулевые значения. Если требуется оценить значимость коэффициента, используйте дополнительные инструменты: надстройку «Анализ данных» (пункт «Корреляция») или формулу для расчета t-статистики: =КОРРЕЛ(A2:A10; B2:B10)*КОРЕНЬ((СЧЁТ(A2:A10)-2)/(1-КОРРЕЛ(A2:A10; B2:B10)^2)). Это позволит определить, является ли связь статистически значимой при заданном уровне доверия (например, 95%).
Для визуализации зависимости постройте диаграмму рассеяния: выделите оба диапазона, перейдите на вкладку «Вставка» и выберите «Точечная диаграмма». Добавьте линию тренда (правый клик по точкам → «Добавить линию тренда») и отметьте опцию «Показывать уравнение на диаграмме». Коэффициент перед x в уравнении регрессии будет близок к значению ρ, полученному через КОРРЕЛ, что подтвердит корректность расчетов.
Интерпретация значений коэффициента корреляции от -1 до 1
Коэффициент корреляции Пирсона (r) измеряет линейную зависимость между двумя переменными в диапазоне от -1 до 1. Значение r = 1 указывает на идеальную положительную корреляцию: при увеличении одной переменной вторая растет пропорционально. Например, зависимость между ростом и весом в однородной выборке спортсменов может приближаться к 0,9, но редко достигает 1 из-за влияния других факторов.
При r = 0,7–0,9 связь считается сильной. В экономике такой уровень корреляции часто наблюдается между расходами на рекламу и объемом продаж. Однако даже здесь важно учитывать внешние переменные: сезонность или конкуренция могут снижать реальную зависимость. Рекомендуется дополнительно проверять данные на выбросы, которые способны искусственно завышать r.
r = 0 означает отсутствие линейной зависимости, но не исключает нелинейных связей. Например, зависимость между дозой лекарства и его эффективностью может описываться параболой, где r близок к нулю, хотя реальная связь существует. В таких случаях применяют коэффициент детерминации (R²) или непараметрические методы, такие как корреляция Спирмена.
Отрицательные значения r интерпретируются аналогично положительным, но с обратной зависимостью. r = -0,8 между временем подготовки к экзамену и количеством ошибок говорит о сильной обратной связи: чем больше времени уделяется учебе, тем меньше ошибок. Однако при r = -0,2 связь слабая, и на результат могут влиять другие факторы, например, уровень стресса или качество материалов.
Крайние значения r = -1 и r = 1 на практике встречаются редко. Они возможны только в идеализированных условиях, например, при сравнении одной и той же переменной, измеренной в разных единицах (метры и сантиметры). В реальных данных такие значения чаще всего указывают на ошибку в расчетах или искусственно созданную зависимость.
При интерпретации r всегда проверяйте статистическую значимость с помощью p-value. Даже высокий коэффициент корреляции (например, 0,8) может оказаться незначимым при малом объеме выборки (n < 30). В Excel для этого используйте функцию =КОРРЕЛ() вместе с =ТТЕСТ() или инструмент «Анализ данных» → «Корреляция».
Построение корреляционной матрицы для нескольких переменных
Для автоматизации используйте надстройку «Пакет анализа»: перейдите в Данные → Анализ данных → Корреляция. В поле «Входной интервал» укажите диапазон с данными (например, A1:D100), отметьте «Метки в первой строке» и выберите «Выходной интервал» – ячейку для размещения результата. Excel сгенерирует матрицу с коэффициентами Пирсона, где на диагонали всегда будут единицы (корреляция переменной с собой), а симметричные значения дублируются.
Интерпретируйте результаты: значения от 0,7 до 1 указывают на сильную положительную связь, от -0,7 до -1 – на сильную отрицательную. При значениях ±0,3–0,7 связь умеренная, ниже ±0,3 – слабая или отсутствует. Исключите из анализа переменные с высокой мультиколлинеарностью (коэффициенты >0,9), так как они искажают регрессионные модели. Для визуализации используйте условное форматирование: выделите матрицу, примените Главная → Условное форматирование → Цветовые шкалы, чтобы быстро выявить критические зависимости.
Визуализация зависимости с помощью диаграммы рассеяния
Диаграмма рассеяния в Excel – инструмент для наглядного анализа связи между двумя переменными. Чтобы построить её, выделите данные (например, столбцы A и B с показателями X и Y), перейдите на вкладку Вставка и выберите Точечная диаграмма. Excel автоматически разместит точки на координатной плоскости, где ось X отражает значения первой переменной, а ось Y – второй. Для данных с более чем 50 наблюдениями используйте формат Точечная с маркерами, чтобы избежать наложения точек.
Интерпретация диаграммы зависит от формы облака точек. Линейный тренд (точки вытянуты вдоль прямой) указывает на сильную корреляцию, а разброс без явной направленности – на её отсутствие. Если точки образуют кривую (например, параболу), связь нелинейна, и коэффициент Пирсона (r) не подходит для оценки. В таких случаях применяйте коэффициент Спирмена или добавляйте линию тренда с полиномиальной аппроксимацией (порядок 2–3).
- Для добавления линии тренда: кликните правой кнопкой по любой точке → Добавить линию тренда → выберите тип (линейная, экспоненциальная и др.).
- Отобразите уравнение и R²: в параметрах линии тренда установите флажки Показывать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации (R²).
- R² (коэффициент детерминации) показывает долю дисперсии Y, объясняемую X. Значение 0,7–1 свидетельствует о высокой предсказательной способности модели.
Настройте оси для повышения информативности. Если данные имеют разный масштаб (например, X – от 1 до 10, Y – от 100 до 1000), включите логарифмическую шкалу для одной из осей: правый клик по оси → Формат оси → Параметры оси → Логарифмическая шкала. Это устранит искажения и сделает тренд более очевидным. Для категориальных данных (например, группы «А», «Б») используйте Точечную с категориями.
Цвет и размер точек можно использовать для передачи дополнительной информации. Например, если третья переменная (Z) влияет на зависимость, задайте размер маркеров пропорционально Z: выделите точки → Формат ряда данных → Заливка и линии → Маркер → Параметры маркера → Размер → выберите столбец с Z. Для цветовой градации используйте условное форматирование перед построением диаграммы или настройте цветовую шкалу в Формат ряда данных.
Проверка значимости корреляции через t-критерий Стьюдента

Критическое значение t зависит от уровня значимости (обычно α=0.05) и числа степеней свободы df = n-2. Для df=28 и двустороннего теста критическое значение t при α=0.05 равно 2.048. Если расчетное t превышает критическое, корреляция считается значимой. В Excel критическое значение можно получить функцией =T.ОБР.2Х(0.05; n-2).
Практический пример: в таблице ниже приведены результаты расчета для трех выборок. Обратите внимание, что при одинаковом r=0.5 значимость различается из-за разного объема данных.
| n | r | t-статистика | Критическое t (α=0.05) | Значимость |
|---|---|---|---|---|
| 10 | 0.5 | 1.63 | 2.306 | Нет |
| 30 | 0.5 | 3.06 | 2.048 | Да |
| 100 | 0.5 | 5.77 | 1.984 | Да |
В Excel t-статистику можно вычислить напрямую: =КОРРЕЛ(диапазон1; диапазон2)*КОРЕНЬ(СЧЁТ(диапазон1)-2)/КОРЕНЬ(1-КОРРЕЛ(диапазон1; диапазон2)^2). Альтернативный способ – использовать функцию =T.РАСП.2Х(ABS(t); n-2), которая вернет p-значение. Если p < 0.05, гипотеза об отсутствии корреляции отвергается.
Важно учитывать ограничения метода: t-критерий предполагает нормальное распределение данных и линейность связи. При нарушении этих условий результаты могут быть искажены. Для проверки нормальности используйте тесты Шапиро-Уилка или Колмогорова-Смирнова, доступные в надстройке «Анализ данных».
При малых выборках (n < 15) мощность теста снижается, и даже сильная корреляция может не достигать значимости. В таких случаях рекомендуется увеличивать объем данных или применять непараметрические методы, например, корреляцию Спирмена. Для больших выборок (n > 100) даже слабая корреляция (r=0.2) может оказаться значимой, поэтому важно оценивать не только p-значение, но и величину эффекта.
В отчетах указывайте не только p-значение, но и доверительный интервал для r. В Excel его можно рассчитать с помощью z-преобразования Фишера: =РЫБ.ОБР(РЫБ.РАСП(r; ИСТИНА) ± НОРМ.СТ.ОБР(1-α/2)*1/КОРЕНЬ(n-3)). Например, для r=0.6 и n=30 95%-ный доверительный интервал составит [0.32; 0.78].
Автоматизировать проверку значимости можно с помощью макроса VBA. Пример кода для расчета t-статистики и p-значения:
Function CorrTSig(r As Double, n As Integer) As Double
Dim t As Double
t = r * Sqr(n - 2) / Sqr(1 - r ^ 2)
CorrTSig = WorksheetFunction.T_Dist_2T(Abs(t), n - 2)
End FunctionИспользуйте этот подход для быстрой оценки значимости корреляции в больших массивах данных без ручных расчетов.