Содержание статьи

Файл формата TXT хранит данные в виде неструктурированного текста, где смысл строк и значений определяется только их положением или символами-разделителями. При передаче таких данных между системами возникают проблемы интерпретации: разные программы по-разному читают строки, игнорируют переносы или не распознают логические связи. Преобразование TXT в XML позволяет задать явную структуру, в которой каждый фрагмент данных получает собственный тег и строго определённое место.
Перед началом преобразования важно установить, что именно означает каждая строка или блок текста: запись товара, параметр конфигурации, лог события или таблица значений. Например, если TXT-файл содержит строки вида id;name;price, то ещё до создания XML необходимо определить, какие элементы станут атрибутами, а какие – вложенными узлами. Ошибка на этом этапе приводит к сложной переработке всего документа.
Формат XML требует соблюдения правил: единая кодировка (чаще всего UTF-8), наличие корневого элемента, корректное вложение тегов и экранирование специальных символов. Эти требования делают XML пригодным для обработки парсерами, валидации по XSD и интеграции с API. В статье рассматривается пошаговый подход, который помогает преобразовать TXT-файл в XML без потери данных и с сохранением логической структуры.
Описанные шаги подходят как для ручной обработки небольших файлов, так и для автоматизации с помощью скриптов. Рекомендации ориентированы на практические задачи: подготовку исходного текста, выбор структуры XML и контроль результата, чтобы итоговый файл был готов к использованию в программных системах.
Определение структуры исходного TXT-файла перед преобразованием
Анализ TXT-файла начинается с изучения логики расположения данных. Необходимо открыть файл в текстовом редакторе с отображением непечатаемых символов, чтобы увидеть переносы строк, табуляции и пробелы. Каждая строка должна быть сопоставлена с потенциальной сущностью будущего XML: записью, параметром или группой значений.
Следующий шаг – выявление разделителей и повторяющихся шаблонов. Чаще всего используются символы ;, ,, | или фиксированная ширина полей. Повторяемость структуры указывает на возможность преобразования строк в однотипные XML-элементы.
- определить, являются ли строки независимыми записями или частью одного блока
- проверить наличие заголовков и служебных строк
- выявить обязательные и пустые поля
- зафиксировать порядок следования значений в строке
Если TXT-файл содержит вложенную логику, например группы строк, относящиеся к одному объекту, необходимо зафиксировать признаки начала и конца блока. Это могут быть ключевые слова, пустые строки или изменяющийся формат данных. Такие признаки напрямую определяют будущую иерархию XML.
- сгруппировать строки по смыслу
- присвоить каждой группе условное имя элемента
- определить уровень вложенности для каждой группы
Результатом анализа должна стать чёткая схема соответствия: строка или поле TXT → элемент или атрибут XML. Эта схема используется на всех последующих этапах и позволяет избежать несогласованной структуры и потери данных при преобразовании.
Выбор правил разметки данных для будущего XML-документа
Правила разметки определяют, как данные из TXT-файла будут представлены в XML и насколько однозначно они будут интерпретироваться программами. На этом этапе необходимо решить, какие фрагменты станут XML-элементами, а какие будут оформлены как атрибуты. Текстовые значения, содержащие смысловую нагрузку, целесообразно размещать в элементах, тогда как идентификаторы и краткие параметры удобнее задавать атрибутами.
Имена тегов должны формироваться на основе назначения данных, а не их позиции в строке. Например, значение из второго столбца TXT не должно превращаться в тег field2, если по смыслу это цена или код. Осмысленные названия упрощают чтение документа и дальнейшую обработку.
Отдельного внимания требует обработка специальных символов. В TXT-файлах часто встречаются <, >, & и кавычки, которые в XML должны быть экранированы или обёрнуты в CDATA. Правило экранирования должно быть выбрано заранее и применяться ко всем текстовым узлам без исключений.
Необходимо определить, какие данные являются обязательными. Для них в структуре XML не должно допускаться отсутствие элементов. Пустые значения следует обрабатывать единообразно: либо создавать пустой тег, либо полностью опускать элемент, но не смешивать оба подхода в одном документе.
Если XML планируется использовать в сторонних системах, стоит заранее зафиксировать ограничения на структуру: допустимые вложенности, повторяемость элементов, типы значений. Эти правила можно затем формализовать в XSD, но даже без схемы они должны быть строго соблюдены при преобразовании TXT.
Подготовка TXT-файла: кодировка, разделители и очистка данных
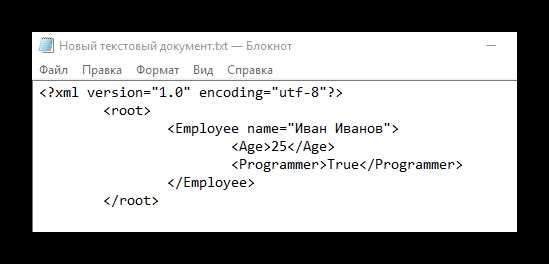
Перед преобразованием необходимо привести TXT-файл к однородному техническому состоянию. В первую очередь проверяется кодировка. Файл следует сохранить в UTF-8 без BOM, так как наличие служебных байтов в начале может привести к ошибкам при разборе XML. Определить текущую кодировку можно через текстовый редактор или утилиты анализа файлов.
Далее выполняется проверка разделителей. Во всём файле должен использоваться один и тот же символ для отделения полей. Смешение ;, , и табуляции затрудняет автоматическую обработку. Если данные содержат разделитель внутри значения, его необходимо экранировать или заключить значение в кавычки до начала преобразования.
Очистка данных включает удаление строк, не несущих смысловой нагрузки: пустых строк, комментариев, технических пометок. Такие элементы не должны попадать в XML, так как они нарушают предсказуемость структуры.
Особое внимание уделяется нормализации значений. Следует устранить лишние пробелы в начале и конце строк, заменить нестандартные символы переноса, привести числовые форматы к единому виду. Например, десятичный разделитель должен быть одинаковым во всех строках.
Результатом подготовки должен стать TXT-файл с предсказуемым форматом: одна строка соответствует одной логической записи, количество полей стабильно, все значения читаемы и готовы к прямому сопоставлению с элементами XML.
Создание корневого элемента и базовой схемы XML
XML-документ всегда начинается с единственного корневого элемента, который объединяет все данные, полученные из TXT-файла. Его имя должно отражать тип содержимого, например набор записей, журнал событий или список параметров. Корневой элемент создаётся один раз и охватывает все остальные узлы без исключений.
После определения корня формируется базовая иерархия. Каждая логическая запись из TXT-файла должна быть представлена вложенным элементом первого уровня. Если строки файла соответствуют однотипным объектам, используется повторяющийся элемент с одинаковым именем, что упрощает обработку и парсинг.
Важно заранее определить допустимую вложенность. Если внутри одной записи присутствуют группы связанных значений, они оформляются как дочерние элементы второго уровня. Плоская структура подходит только для простых файлов с фиксированным набором полей.
На этом этапе рекомендуется зафиксировать базовые правила схемы: какие элементы могут повторяться, какие должны присутствовать всегда, в каком порядке они следуют. Даже без явного XSD эти ограничения должны соблюдаться при формировании XML, чтобы документ оставался предсказуемым.
Корневой элемент и начальная схема служат каркасом, в который затем подставляются данные из TXT. Ошибки в этом каркасе приводят к необходимости переработки всего файла, поэтому структура должна быть определена до начала массового преобразования строк.
Преобразование строк TXT в XML-элементы вручную
Ручное преобразование применяется при небольшом объёме данных или при необходимости полного контроля над структурой XML. Каждая строка TXT анализируется отдельно и сопоставляется с заранее определённой схемой элементов. Работа выполняется в текстовом редакторе с подсветкой синтаксиса XML, что снижает риск ошибок вложенности.
Строку TXT следует разбить на отдельные значения строго по выбранному разделителю. Полученные фрагменты последовательно помещаются внутрь соответствующих XML-тегов. Порядок элементов должен совпадать с логикой, заданной на этапе проектирования структуры.
| Фрагмент TXT | XML-представление |
|---|---|
| 123;Книга;450 | <item><id>123</id><name>Книга</name><price>450</price></item> |
При вводе значений вручную необходимо сразу экранировать специальные символы и проверять корректность закрытия тегов. Каждый элемент должен иметь парный закрывающий тег, а вложенность не должна пересекаться.
После добавления нескольких записей рекомендуется временно проверить файл любым XML-парсером. Это позволяет быстро выявить пропущенные теги или некорректные символы до того, как документ станет слишком объёмным для ручной проверки.
Ручной способ требует аккуратности, но даёт полное понимание того, как каждая строка TXT преобразуется в конкретный XML-элемент и как формируется итоговая структура документа.
Использование скриптов или утилит для автоматического преобразования
Автоматическое преобразование оправдано при работе с большими TXT-файлами или регулярной обработке однотипных данных. Скрипт должен читать файл построчно, разбивать строки по заданному разделителю и формировать XML-элементы в соответствии с заранее определённой структурой.
Наиболее часто используются языки с развитой поддержкой работы с текстом и XML: Python, PowerShell, Bash с утилитами обработки строк. Важно, чтобы скрипт явно задавал кодировку входного и выходного файлов, иначе возможны искажения символов.
При автоматизации необходимо заложить проверки входных данных. Скрипт должен контролировать количество полей в строке, пропускать пустые или повреждённые записи и логировать строки, которые не удалось корректно преобразовать.
Готовые утилиты подходят для простых случаев, когда структура TXT фиксирована и не содержит вложенных блоков. Перед использованием таких инструментов следует проверить, поддерживают ли они настройку имён тегов, обработку специальных символов и повторяющихся элементов.
Результат работы скрипта должен формироваться потоково, без накопления всего XML в памяти. Это позволяет обрабатывать файлы большого размера и сразу получать корректно сформированный документ, готовый к проверке и дальнейшему использованию.
Проверка корректности XML-файла после преобразования
После формирования XML-файла необходимо убедиться, что документ соответствует синтаксическим требованиям и логике заданной структуры. Первичная проверка выполняется с помощью XML-парсера, который выявляет ошибки вложенности, отсутствующие закрывающие теги и недопустимые символы.
- наличие одного корневого элемента
- корректное закрытие всех тегов
- соблюдение вложенности без пересечений
- правильное экранирование специальных символов
Далее проводится проверка соответствия ожидаемой структуре. Для этого просматривается несколько записей в разных частях файла, чтобы убедиться, что все элементы создаются в одинаковом порядке и с одинаковыми именами.
- сравнить количество записей в TXT и XML
- проверить заполненность обязательных элементов
- убедиться в отсутствии лишних или дублирующихся узлов
Если XML предназначен для интеграции с другой системой, следует выполнить тестовую загрузку или валидацию по XSD. Это позволяет обнаружить расхождения в типах данных и ограничениях, которые не выявляются простой проверкой синтаксиса.
Финальным шагом является просмотр XML в текстовом виде. Читаемость структуры и логичное расположение элементов служат дополнительным признаком корректного преобразования и готовности файла к дальнейшему использованию.
Сохранение и дальнейшее использование XML-документа
После завершения проверки XML-документ следует сохранить в стабильном виде с явно указанной кодировкой UTF-8 в заголовке файла. Имя файла должно отражать его содержимое и версию структуры, чтобы избежать путаницы при обновлениях и повторных преобразованиях.
Для дальнейшего использования важно зафиксировать формат XML как контракт данных. Если документ применяется для обмена между системами, любые изменения структуры должны вноситься осознанно и сопровождаться обновлением схемы или описания формата.
XML-файл может быть использован для загрузки в базы данных, передачи через API или обработки прикладными программами. В каждом случае следует учитывать требования принимающей стороны к порядку элементов, допустимым значениям и наличию обязательных узлов.
Рекомендуется хранить исходный TXT и итоговый XML вместе, чтобы при необходимости можно было восстановить процесс преобразования. Это особенно важно при автоматической генерации, где скрипты могут быть изменены со временем.
При повторном использовании структуры целесообразно создать шаблон XML с пустыми значениями. Такой шаблон служит ориентиром для новых преобразований и снижает риск отклонений от согласованного формата.
Вопрос-ответ:
Можно ли преобразовать TXT в XML, если строки имеют разную длину и количество полей?
Да, это возможно, но требуется предварительный анализ содержимого. Нужно определить, какие поля являются постоянными, а какие появляются только в отдельных строках. В XML такие данные обычно оформляются как необязательные элементы, которые создаются только при наличии значения. При автоматической обработке скрипт должен проверять количество полей в строке и корректно обрабатывать пропуски.
Что делать, если в TXT-файле встречаются символы < и &, которые ломают XML?
Такие символы нельзя переносить в XML напрямую. Их необходимо заменить на экранированные формы (<, &) или поместить текст в секцию CDATA. Способ выбирается заранее и применяется ко всем текстовым узлам, чтобы структура документа оставалась однородной.
Как понять, что лучше использовать: XML-элементы или атрибуты?
Если значение содержит текст, может повторяться или иметь вложенную структуру, его размещают в элементе. Атрибуты подходят для коротких параметров, идентификаторов и признаков, которые не предполагают дальнейшего разбиения. Смешивание подходов для одинаковых данных приводит к сложностям при обработке.
Подходит ли ручное преобразование для рабочих задач?
Ручной способ оправдан при малом объёме данных или разовой задаче, когда требуется точный контроль структуры. Для файлов с сотнями и тысячами строк такой подход быстро становится неудобным и увеличивает риск ошибок, поэтому его используют только в ограниченных случаях.
Нужно ли создавать XSD-схему после преобразования TXT в XML?
Если XML используется внутри одного процесса, схема не всегда обязательна. При передаче данных между системами XSD помогает зафиксировать правила структуры, типы значений и допустимую вложенность. Это снижает количество ошибок при приёме и обработке файла.
Как преобразовать TXT в XML, если данные в файле сгруппированы блоками по несколько строк?
В таком случае каждая группа строк рассматривается как одна логическая запись. Сначала нужно определить признак начала и конца блока: это может быть ключевое слово, пустая строка или изменение формата строки. При ручном преобразовании блок целиком оформляется как один XML-элемент с вложенными узлами для каждой строки. При автоматизации скрипт должен накапливать строки до завершения блока, а затем формировать XML-структуру только после полного считывания группы.