Содержание статьи

Регулярные выражения в C позволяют искать, проверять и модифицировать текстовые данные по строго заданным шаблонам. Библиотека regex.h предоставляет функции для компиляции шаблонов, проверки соответствия строк и извлечения совпадений.
Основные функции, используемые в C для работы с Regex, включают regcomp для компиляции шаблона, regexec для поиска совпадений и regfree для освобождения ресурсов. Шаблон может содержать метасимволы для поиска конкретных символов, диапазонов, повторов и групп, что позволяет обрабатывать сложные текстовые структуры без ручного перебора символов.
Regex в C полезен при парсинге логов, проверке форматов ввода, извлечении данных из больших текстовых файлов и автоматизации текстовой обработки. Оптимальный подход заключается в предварительной компиляции регулярного выражения перед многократным использованием, что снижает нагрузку на программу и ускоряет поиск совпадений.
Подключение библиотеки regex.h и настройка компиляции
Для работы с регулярными выражениями в C необходимо подключить стандартную библиотеку regex.h. Это делается через директиву #include <regex.h>. Она предоставляет структуры regex_t для хранения скомпилированного шаблона и функции для его обработки.
Компиляция проекта с использованием Regex требует указания стандартной библиотеки при сборке. В GCC достаточно использовать ключ -std=c11 или выше, чтобы гарантировать поддержку стандартных функций C, а для некоторых систем может понадобиться линковка с -lregex.
Рекомендуется проверять код возврата функции regcomp после компиляции шаблона. Это позволяет сразу выявить ошибки в синтаксисе регулярного выражения и предотвратить сбои при вызове regexec. Для комплексных проектов удобно создавать отдельный модуль с функциями инициализации и освобождения регулярных выражений, что упрощает повторное использование шаблонов.
Создание и компиляция регулярного выражения в C
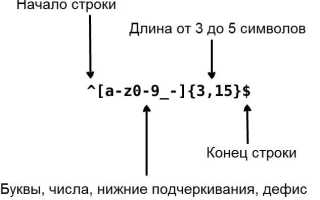
Регулярное выражение в C создается с использованием структуры regex_t. Для компиляции шаблона применяется функция regcomp(<regex_t>, <шаблон>, <флаги>). Флаги определяют способ поиска: REG_EXTENDED включает расширенный синтаксис, REG_ICASE игнорирует регистр, REG_NOSUB пропускает хранение совпадений.
Перед компиляцией рекомендуется проверять корректность шаблона на коротких строках и избегать неоднозначных конструкций, таких как пересекающиеся группы и неограниченные квантификаторы * или +, которые могут замедлять выполнение.
После вызова regcomp возвращаемое значение следует сравнивать с 0. Любое ненулевое значение указывает на ошибку синтаксиса или переполнение буфера. Для удобного отображения ошибок можно использовать функцию regerror, которая возвращает текстовое описание проблемы и помогает быстро корректировать шаблон.
Компиляция регулярного выражения один раз и многократное его использование экономит ресурсы программы и ускоряет обработку больших текстовых массивов. После завершения работы с шаблоном необходимо вызвать regfree для освобождения памяти.
Проверка соответствия строки шаблону с помощью regexec

Функция regexec используется для проверки, соответствует ли текст заданному регулярному выражению. Синтаксис функции: int regexec(const regex_t *preg, const char *string, size_t nmatch, regmatch_t pmatch[], int eflags). Здесь preg – скомпилированное регулярное выражение, string – проверяемая строка, nmatch – количество элементов массива для хранения совпадений, pmatch – массив структур regmatch_t, eflags – дополнительные флаги.
Значение, возвращаемое regexec, можно интерпретировать следующим образом:
| Возврат | Описание |
|---|---|
| 0 | Строка соответствует шаблону |
| REG_NOMATCH | Совпадений не найдено |
| Любое другое значение | Ошибка выполнения или некорректный шаблон |
Для извлечения совпадений массив pmatch заполняется индексами начала и конца совпадающих подстрок. Это позволяет обрабатывать несколько групп внутри одного шаблона. Рекомендуется проверять возвращаемое значение перед использованием pmatch, чтобы избежать выхода за пределы массива.
Флаг REG_NOTBOL позволяет рассматривать строку как не начинающуюся с начала текста, а REG_NOTEOL – как не оканчивающуюся концом строки. Эти опции полезны при поиске совпадений внутри больших текстовых блоков без разбиения на строки.
Извлечение совпадений и подстрок из текста
Для извлечения совпадений используется массив структур regmatch_t, который передается в функцию regexec. Каждая структура содержит два поля: rm_so – индекс начала совпадения, и rm_eo – индекс конца. Эти значения позволяют точно выделять подстроки из исходного текста.
Если регулярное выражение содержит группы, pmatch[0] хранит полное совпадение, а pmatch[1], pmatch[2] и так далее – содержимое соответствующих групп. Это удобно для извлечения отдельных компонентов, например, имени файла и расширения или даты и времени из строки.
Для сохранения подстрок рекомендуется использовать функцию strncpy, выделяя память строго по длине rm_eo — rm_so и добавляя завершающий нулевой символ. Такой подход предотвращает переполнение буфера и позволяет безопасно работать с динамическими строками.
При обработке больших текстов стоит повторно вызывать regexec с указанием rm_so следующего совпадения, чтобы находить все вхождения шаблона. Использование циклов вместе с массивом pmatch позволяет последовательно извлекать все совпадения без потери данных.
Замена и редактирование текста через регулярные выражения

В стандартной библиотеке C нет встроенной функции для прямой замены текста через Regex, поэтому требуется комбинировать regexec и работу со строками вручную. Основной подход включает последовательные шаги:
- Вызвать regexec для поиска совпадения шаблона в исходной строке.
- Использовать массив regmatch_t для определения индексов начала и конца совпадения.
- Создать новую строку, копируя все символы до совпадения.
- Вставить текст замены в место совпадения.
- Добавить оставшуюся часть исходной строки после совпадения.
- Повторять процесс для всех последующих совпадений, при необходимости в цикле.
Для сложных замен удобно использовать временные буферы и динамическое выделение памяти, чтобы избежать переполнения. Также рекомендуется проверять длину итоговой строки перед каждой вставкой.
Практические рекомендации:
- При замене нескольких совпадений используйте смещение индекса начала поиска на конец предыдущего совпадения.
- Для шаблонов с группами можно включать содержимое групп в строку замены, обращаясь к индексам массива pmatch.
- Тестируйте регулярные выражения на небольших примерах, чтобы убедиться, что замена не затрагивает нежелательные фрагменты текста.
- При работе с большими текстами используйте буферы фиксированного размера с проверкой длины, чтобы избежать ошибок памяти.
Обработка ошибок при работе с regex в C

Функции regcomp и regexec возвращают коды ошибок, которые необходимо проверять после каждого вызова. regcomp возвращает ненулевое значение при синтаксической ошибке шаблона или переполнении внутреннего буфера. regexec возвращает REG_NOMATCH, если совпадений нет, и другие ненулевые значения при системных ошибках.
Рекомендуемые практики:
- Проверять возврат regcomp перед вызовом regexec и выполнять regfree только для успешно скомпилированных выражений.
- Всегда обрабатывать REG_NOMATCH отдельно, чтобы отличать отсутствие совпадений от ошибок выполнения.
- Использовать буфер фиксированной длины для regerror, а при необходимости запрашивать длину сообщения повторно, чтобы избежать обрезки текста.
- При циклическом поиске совпадений проверять корректность индексов rm_so и rm_eo, чтобы исключить выход за пределы строки.
Примеры использования регулярных выражений в проектах на C

Регулярные выражения в C применяются для обработки текстовых данных, проверки форматов и автоматизации анализа информации. Ниже приведены практические сценарии их использования:
- Парсинг лог-файлов для извлечения IP-адресов, временных меток и кодов ошибок.
- Валидация пользовательского ввода, включая адреса электронной почты, номера телефонов и идентификаторы.
- Извлечение данных из CSV или JSON файлов, когда необходимо фильтровать строки по определённым шаблонам.
- Автоматическое переименование файлов на основе шаблонов, например, изменение расширений или добавление префиксов.
- Поиск и замена повторяющихся слов или символов в текстовых документах.
Реализация в проекте может следовать схеме:
- Компиляция регулярного выражения с использованием regcomp.
- Поиск совпадений в целевых строках через regexec.
- Извлечение совпадений и групп с использованием массива regmatch_t.
- При необходимости создание новой строки с заменами или фильтрацией данных.
- Освобождение ресурсов с помощью regfree после завершения обработки.
Рекомендуется тестировать регулярные выражения на небольших примерах и постепенно внедрять их в рабочий проект, чтобы избежать ошибок и контролировать производительность при работе с большими объёмами данных.
Вопрос-ответ:
Что такое регулярные выражения в C и для чего они используются?
Регулярные выражения в C — это шаблоны, которые позволяют находить, проверять и изменять текстовые данные. Они применяются для поиска совпадений, валидации форматов, извлечения подстрок и обработки больших текстовых массивов без ручного перебора символов.
Как подключить библиотеку для работы с Regex в C?
Для работы с регулярными выражениями нужно подключить regex.h через #include <regex.h>. При компиляции проекта с GCC достаточно указать стандарт C11 или выше с ключом -std=c11. В некоторых системах может потребоваться линковка с -lregex. После подключения можно использовать структуры regex_t и функции regcomp, regexec, regfree.
Как проверить, соответствует ли строка регулярному выражению?
Для проверки используется функция regexec. Она принимает скомпилированный шаблон, строку для проверки, массив для хранения совпадений и флаги. Возврат 0 означает совпадение, REG_NOMATCH — его отсутствие, а другие значения указывают на ошибки. Индексы начала и конца совпадений доступны через массив regmatch_t.
Каким образом можно извлекать отдельные подстроки из совпадений?
Массив regmatch_t хранит начало и конец каждого совпадения или группы. Для извлечения подстроки используют эти индексы с функциями вроде strncpy, создавая буфер нужной длины и добавляя нулевой символ в конце. Такой метод безопасно выделяет совпадения без риска выхода за пределы строки.
Можно ли заменить части текста с помощью регулярных выражений в C?
Прямой функции замены в стандартной библиотеке нет, поэтому обычно комбинируют regexec и работу со строками. После поиска совпадения копируют текст до совпадения, вставляют строку замены и добавляют остаток исходного текста. Для нескольких совпадений используется цикл с обновлением индекса начала поиска. Важно использовать буферы с контролем длины, чтобы избежать ошибок памяти.
Как правильно использовать регулярные выражения для поиска и замены текста в C?
В C нет встроенной функции для прямой замены текста через регулярные выражения, поэтому процесс включает несколько шагов. Сначала шаблон компилируется с помощью regcomp. Далее с помощью regexec ищутся совпадения в строке, а массив regmatch_t хранит позиции начала и конца каждого совпадения. Для замены создается новая строка: копируются символы до совпадения, вставляется текст замены и добавляется оставшаяся часть исходной строки. Для нескольких совпадений используется цикл с обновлением индекса начала поиска. Рекомендуется контролировать длину буфера при копировании, чтобы избежать переполнения, и использовать regfree после завершения работы с шаблоном.