Содержание статьи

На практике проблема чаще всего всплывает при обработке логов, конфигурационных файлов, списков значений или данных для последующего анализа. Например, сравнение строки из файла с заданным значением через == возвращает False, хотя визуально текст совпадает. Причина почти всегда одна – незаметный символ переноса в конце строки.
Python предлагает несколько способов работы с переводами строк, и выбор метода зависит от задачи. В одних случаях нужно удалить только \n, в других – учесть комбинацию \r\n, а иногда перенос строки лучше сохранить. Понимание того, как именно данные читаются из файла и какие методы применяются к строкам, позволяет избежать лишних преобразований и ошибок в логике программы.
В этой статье рассматриваются прикладные способы удаления символов перевода строки при чтении файлов в Python, с акцентом на реальные сценарии использования и различия между подходами.
Почему строки, прочитанные из файла, содержат \n
Функция open() при работе в текстовом режиме читает файл построчно, считая перевод строки частью данных. Это позволяет точно воспроизводить структуру исходного файла и не терять информацию о форматировании. Метод readline() возвращает строку вместе с завершающим переносом, а итерация по файловому объекту через for использует тот же механизм.
Такое поведение упрощает задачи, связанные с повторной записью данных в файл или анализом исходного формата. Например, при копировании содержимого файла Python может записать строки обратно без изменения их структуры. Если бы символ перевода строки удалялся автоматически, восстановление исходного вида файла потребовало бы дополнительных действий.
Проблемы возникают тогда, когда строки из файла используются как обычные текстовые значения: для сравнения, конкатенации или передачи в другие функции. В этих случаях \n становится скрытым символом, который влияет на результат операций. Поэтому при обработке данных разработчик сам решает, нужно ли сохранять перевод строки или удалить его явным образом.
Удаление символа \n с помощью метода str.rstrip
Метод str.rstrip() применяется для удаления символов с правого края строки. При чтении файла он чаще всего используется для очистки завершающего перевода строки \n, не затрагивая содержимое в начале и середине строки. Это делает его удобным при построчной обработке данных.
Типовой сценарий выглядит так: строка читается из файла через for line in file, после чего к ней применяется line.rstrip(). В результате удаляется перевод строки, а текстовое содержимое остаётся без изменений.
- line.rstrip() – удаляет все пробельные символы справа, включая \n, \r и пробелы
- line.rstrip(‘\n’) – убирает только символ \n, сохраняя возможные пробелы в конце строки
- line.rstrip(‘\r\n’) – подходит для файлов, созданных в Windows
Если данные содержат значимые пробелы в конце строки, рекомендуется передавать аргумент в rstrip(). В противном случае метод удалит не только перевод строки, но и все завершающие пробелы, что может исказить данные.
Метод особенно полезен при:
- сравнении строк из файла с фиксированными значениями
- формировании списков и словарей из текстовых данных
str.rstrip() не изменяет исходную строку, а возвращает новую, поэтому результат нужно сохранять в переменную или использовать сразу в выражении.
Применение str.strip и отличие от rstrip
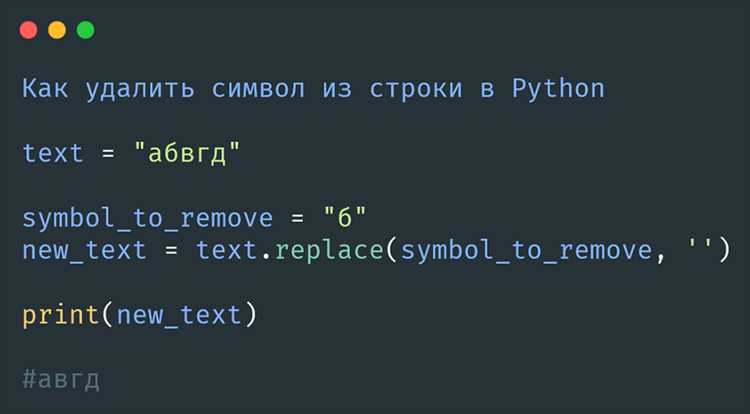
Метод str.strip() удаляет пробельные символы с обоих краёв строки. При чтении файла это означает удаление не только символа перевода строки \n, но и пробелов или табуляций слева и справа. Такое поведение подходит не для всех задач, поэтому важно понимать разницу с rstrip().
При использовании strip() Python обрабатывает строку следующим образом:
- удаляет \n, \r и \t в конце строки
- убирает пробелы и табуляции в начале строки
- возвращает новый объект строки без изменения исходного значения
Это удобно при разборе файлов, где отступы не несут смысла, например списков значений, данных CSV без кавычек или пользовательского ввода, сохранённого в файл.
str.rstrip(), в отличие от strip(), работает только с правой частью строки. Это позволяет сохранить начальные пробелы, которые могут использоваться для форматирования, выравнивания или хранения иерархии данных.
Различия между методами на практике:
- strip() – подходит для очистки строк перед сравнением или преобразованием типов
- rstrip() – подходит для удаления \n без влияния на отступы
- strip(‘\n’) – убирает только перевод строки с обеих сторон, что редко требуется
Если файл содержит структурированные данные с ведущими пробелами, предпочтение стоит отдавать rstrip(). strip() лучше применять осознанно, когда форматирование строки не играет роли.
Чтение файла через splitlines без символов перевода строки
Метод str.splitlines() позволяет получить строки файла без сохранения символов перевода строки. В этом случае файл сначала читается целиком с помощью read(), после чего содержимое разбивается на строки по всем поддерживаемым разделителям: \n, \r\n и \r. Каждый элемент результата не содержит символов переноса.
Такой подход полезен при работе с небольшими файлами, где требуется получить чистый список строк без дополнительной обработки. В отличие от построчного чтения, здесь не нужно вызывать rstrip() или strip() для каждой строки, так как разделение происходит сразу по всем типам переводов строк.
По умолчанию splitlines() удаляет символы переноса. Если требуется сохранить их, метод поддерживает параметр keepends=True, но при очистке строк его использовать не следует. Для задачи удаления \n важно оставить значение по умолчанию.
Следует учитывать, что чтение через read() загружает весь файл в память. Для логов, дампов или других объёмных файлов такой способ может привести к избыточному расходу памяти. В подобных случаях построчное чтение с for и rstrip() будет более подходящим.
splitlines() удобно применять при разборе конфигурационных файлов, списков значений или текстов, где порядок строк важен, а сами переводы строк не несут смысловой нагрузки.
Очистка строк от \n при чтении файла в цикле for
Самый прямой способ убрать \n в этом сценарии – обработать строку внутри цикла. Чаще всего применяется вызов line = line.rstrip(), который удаляет завершающий перевод строки перед дальнейшей логикой обработки.
Если в данных присутствуют значимые пробелы в конце строки, рекомендуется использовать line.rstrip(‘\n’). Такой вариант убирает только символ переноса и не затрагивает остальные символы, что особенно важно при анализе форматированных файлов.
Очистку строки следует выполнять сразу после чтения, до сравнения, разбиения или преобразования данных. Это позволяет избежать скрытых ошибок, когда строка визуально совпадает с ожидаемым значением, но содержит невидимый символ в конце.
Чтение файла в цикле for с удалением \n подходит для больших файлов, так как строки обрабатываются последовательно и не загружаются целиком в память. Такой подход хорошо сочетается с фильтрацией строк, подсчётом значений и пошаговой обработкой данных.
Удаление \n при использовании метода readlines
Для удаления \n после вызова readlines() применяют генератор списков или цикл:
lines = [line.rstrip(‘\n’) for line in file.readlines()]
Такой подход позволяет одновременно удалить переводы строк и сохранить порядок строк в списке. Если файл был создан в Windows и содержит \r\n, лучше использовать line.rstrip(‘\r\n’) для корректного удаления обоих символов.
Метод readlines() удобен при необходимости работать со всеми строками сразу, но стоит учитывать, что он загружает весь файл в память. Для больших файлов рекомендуется использовать построчное чтение с for и rstrip().
Удаление \n после readlines() облегчает последующие операции: объединение строк, формирование списков значений, передачу данных в функции и сравнение с эталонными строками без риска ошибки из-за невидимого символа переноса.
Учет переводов строк \r\n и \r при чтении файлов

В текстовых файлах разных операционных систем символы конца строки могут отличаться. В Unix и Linux используется \n, в Windows – комбинация \r\n, в старых версиях macOS – \r. При чтении файла в Python важно учитывать эти различия, иначе строки будут содержать лишние символы, влияющие на обработку данных.
Методы rstrip() и splitlines() позволяют корректно удалить любые переводы строк:
- line.rstrip(‘\r\n’) – удаляет как \r, так и \n в конце строки
- str.splitlines() – разбивает текст по всем типам переводов строк и возвращает список строк без управляющих символов
При использовании readlines() также рекомендуется применить rstrip(‘\r\n’) для очистки строк. Это особенно важно при работе с файлами, полученными из разных систем, чтобы сравнения, фильтрация и объединение строк выполнялись корректно.
Правильная обработка \r\n и \r позволяет избежать ошибок при анализе логов, конфигурационных файлов и текстовых данных, где символы конца строки могут быть различными. В большинстве случаев достаточно явного указания rstrip(‘\r\n’) или использования splitlines() для получения чистых строк.
Ситуации, когда символ перевода строки нужно сохранить
Сохранение символа перевода строки \n необходимо, когда структура исходного файла имеет значение. Например, при формировании текстовых отчетов, логов или файлов конфигурации порядок строк и наличие переносов критичны для корректной работы программы.
Примеры таких случаев удобно представить в виде таблицы:
| Ситуация | Причина сохранения \n | Пример использования |
|---|---|---|
| Форматирование текстового отчета | Перенос строки задаёт новую строку отчета | Запись с помощью write() в файл для сохранения структуры |
| Логи сервера или приложения | Каждое событие должно начинаться с новой строки | Сбор логов в массив и последующая запись в файл без удаления \n |
| Конфигурационные файлы | Отступы и переносы важны для парсинга | Чтение и запись файла без изменения символов конца строки |
| Текстовые шаблоны | Сохранение исходной разметки | Шаблоны HTML или Markdown, где переносы формируют структуру |
В таких ситуациях использование rstrip() или splitlines() не рекомендуется. Символ переноса строки обеспечивает правильное разделение данных при записи и отображении, позволяя сохранить исходный формат файла.
Вопрос-ответ:
Почему при чтении файла каждая строка содержит символ \n?
Символ \n указывает на конец строки в текстовом файле. При использовании функций open(), readline() или итерации через for line in file Python возвращает строку вместе с этим символом, чтобы сохранить точную структуру исходного файла. Без него восстановление исходного текста или повторная запись в файл могут работать некорректно.
Как удалить только символ перевода строки без удаления пробелов в конце строки?
Для удаления только \n используют line.rstrip(‘\n’). Этот метод удаляет конкретно символ переноса строки справа, оставляя все пробельные символы и табуляции. Такой подход важен при обработке файлов, где отступы имеют смысл, например, в конфигурациях или форматированных списках.
В чём отличие методов strip() и rstrip() при удалении перевода строки?
strip() удаляет пробельные символы с обоих концов строки, включая \n и \r, тогда как rstrip() обрабатывает только правый край. Для задач, где важны начальные пробелы, используют rstrip(), чтобы удалить только завершающий символ переноса строки без изменения форматирования строки.
Можно ли использовать splitlines для получения строк без \n?
Да, метод splitlines() разделяет текст на строки по всем типам переносов (\n, \r\n, \r) и возвращает список строк без символов конца строки. Это удобно для небольших файлов, когда нужно получить чистые строки без дополнительной обработки с помощью rstrip().
Когда символ переноса строки нужно оставить при обработке файла?
Сохранение \n требуется, если порядок строк или структура текста имеет значение. Например, в логах, текстовых отчетах, конфигурационных файлах или шаблонах, где перенос строки формирует разделение данных. В таких случаях удаление символа переноса приведёт к изменению формата и может нарушить работу программы.
Как удалить символ \n при чтении файла построчно через цикл for?
При чтении файла через for line in file каждая строка содержит символ переноса \n. Для его удаления внутри цикла используют line = line.rstrip() или line = line.rstrip(‘\n’). Первый вариант удаляет все пробельные символы справа, второй — только перенос строки, сохраняя отступы. После этого строку можно безопасно сравнивать, объединять или записывать в новый файл.
Можно ли убрать \n сразу при чтении всех строк через readlines?
Да, метод readlines() возвращает список строк с символами конца строки. Для их удаления используют генератор списков: lines = [line.rstrip(‘\n’) for line in file.readlines()]. Если файл из Windows содержит \r\n, применяют line.rstrip(‘\r\n’). Такой подход сохраняет порядок строк и обеспечивает работу с чистыми значениями в списке без скрытых символов переноса.