Содержание статьи

Связывание таблиц в SQL позволяет объединять данные из разных источников внутри базы данных для получения полной картины информации. Для начала важно определить, какие поля будут использоваться для соединения: чаще всего это первичный и внешний ключ. Неправильный выбор ключей приводит к дублированию строк или потере данных.
Тип соединения напрямую влияет на результат запроса. INNER JOIN возвращает только совпадающие строки, LEFT JOIN сохраняет все строки из левой таблицы, а RIGHT JOIN – из правой. Для объединения нескольких таблиц одновременно рекомендуется строить цепочку соединений с чёткой последовательностью и проверкой промежуточных результатов.
При работе с большим количеством данных важно использовать фильтры после соединения. WHERE и ON помогают исключить ненужные записи, снижая нагрузку на сервер и ускоряя обработку. Отладка запросов включает проверку количества строк и соответствие значений ключевых полей.
В этом руководстве представлены конкретные шаги по связыванию таблиц, включая выбор типа соединения, построение запросов и проверку результата. Следование этим методам позволяет получать точные выборки без дублирования и пропусков данных.
Выбор типа соединения для двух таблиц
LEFT JOIN используется, если требуется сохранить все записи из первой таблицы, даже если соответствий во второй нет. Это актуально при формировании отчётов по клиентам, включая тех, кто ещё не сделал заказ.
RIGHT JOIN наоборот сохраняет все строки из второй таблицы, игнорируя отсутствие совпадений в первой. Он применяется реже, например, при анализе списка товаров с обязательным отображением всех категорий.
Выбор типа соединения влияет на количество возвращаемых строк и их структуру. Перед написанием запроса рекомендуется сопоставить ключевые поля и оценить, какие записи необходимо сохранить, чтобы избежать потери данных или лишних дубликатов.
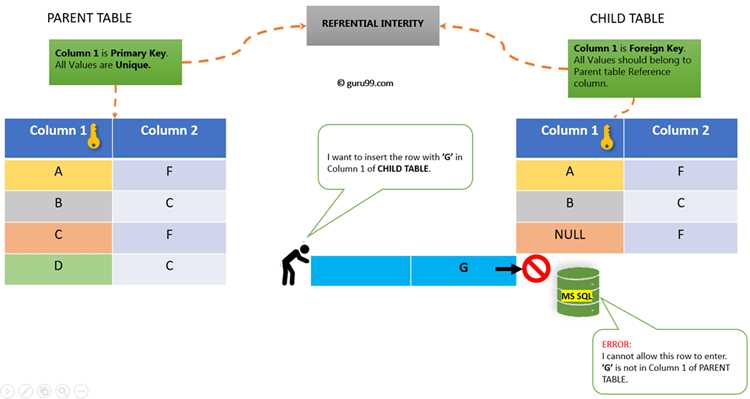
Соединение таблиц по ключевым полям
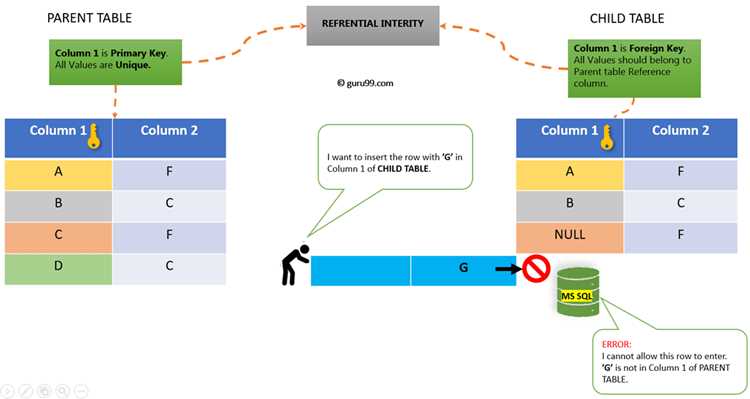
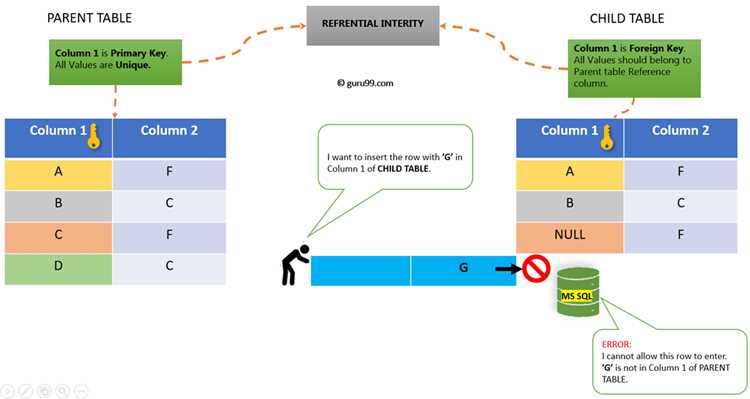
Ключевые поля обеспечивают точное сопоставление строк при объединении таблиц. Обычно используется первичный ключ одной таблицы и внешний ключ другой. Например, таблица Customers с полем CustomerID связывается с таблицей Orders по полю CustomerID.
При соединении важно проверить типы данных ключевых полей: они должны совпадать. Несоответствие типов может вызвать ошибки или некорректные результаты. Для строковых идентификаторов учитывайте регистр и возможные пробелы.
Рекомендуется использовать явное указание полей через оператор ON, например: ON Customers.CustomerID = Orders.CustomerID. Это предотвращает случайные перекрёстные соединения и упрощает отладку запросов.
При объединении нескольких таблиц по ключевым полям поддерживайте последовательность соединений и проверяйте промежуточные результаты. Это помогает выявить пропущенные или дублированные записи до формирования окончательного набора данных.
Использование INNER JOIN для выборки совпадающих данных
INNER JOIN возвращает только те строки, которые имеют совпадения в обеих таблицах по указанным ключевым полям. Например, для таблиц Orders и Customers запрос SELECT Orders.OrderID, Customers.Name FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID вернёт только заказы, привязанные к существующим клиентам.
При использовании INNER JOIN важно учитывать наличие NULL-значений в ключевых полях. Такие строки не попадут в результат, поэтому при необходимости их включения следует рассмотреть LEFT JOIN.
Для повышения читаемости запросов рекомендуется явно указывать таблицы и поля, избегая сокращений. Это облегчает анализ запроса и предотвращает ошибки при добавлении новых соединений.
При соединении больших таблиц полезно проверять план выполнения запроса. Оптимизация индексов на ключевых полях ускоряет выборку и сокращает нагрузку на сервер.
Применение LEFT JOIN для сохранения всех записей из основной таблицы
LEFT JOIN возвращает все строки из левой (основной) таблицы и только совпадающие строки из правой таблицы. Например, при объединении Customers и Orders запрос SELECT Customers.Name, Orders.OrderID FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID покажет всех клиентов, включая тех, у кого нет заказов.
LEFT JOIN полезен для формирования отчётов, где необходимо видеть полные списки сущностей независимо от наличия связанных данных. Это предотвращает потерю информации при отсутствии соответствий.
При работе с LEFT JOIN следует проверять, что все поля для соединения правильно индексированы. Это ускоряет выборку и снижает нагрузку на сервер при больших объёмах данных.
Важно учитывать, что незаполненные поля правой таблицы будут отображаться как NULL. Для корректного отображения можно использовать функции, например COALESCE, чтобы подставлять значения по умолчанию.
Применение RIGHT JOIN для сохранения всех записей из присоединяемой таблицы
RIGHT JOIN возвращает все строки из правой (присоединяемой) таблицы и только совпадающие строки из левой таблицы. Например, если нужно объединить таблицы Products и Orders для анализа товаров, запрос SELECT Orders.OrderID, Products.ProductName FROM Orders RIGHT JOIN Products ON Orders.ProductID = Products.ProductID покажет все товары, включая те, которые не были заказаны.
RIGHT JOIN применяется для проверки полноты данных присоединяемой таблицы и выявления отсутствующих связей. В отчётах он позволяет не терять информацию о всех элементах справочников или каталогов.
Для наглядного представления результатов можно использовать
| ProductID | ProductName | OrderID |
|---|---|---|
| 101 | Ноутбук | 5001 |
| 102 | Монитор | NULL |
NULL в столбце OrderID указывает, что товар пока не заказан. Для удобства анализа можно использовать функции обработки NULL, например COALESCE, чтобы подставлять значения по умолчанию.
Соединение нескольких таблиц в одном запросе
При необходимости объединить более двух таблиц рекомендуется строить цепочку JOIN, начиная с основной таблицы и последовательно присоединяя другие. Например, для анализа заказов с информацией о клиентах и продуктах можно использовать:
SELECT Customers.Name, Orders.OrderID, Products.ProductName FROM Customers INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID INNER JOIN Products ON Orders.ProductID = Products.ProductID.
Важно проверять последовательность соединений: сначала присоединяются таблицы с ключами, обеспечивающими наибольшее сужение выборки, это уменьшает объём промежуточных данных и ускоряет выполнение запроса.
При нескольких JOIN рекомендуется явно указывать тип соединения для каждой пары таблиц, чтобы избежать непреднамеренных CROSS JOIN. Также полезно использовать алиасы для таблиц, чтобы запрос оставался читаемым и удобным для отладки.
Проверка промежуточных результатов после каждого соединения позволяет выявить дубли и несоответствия, что особенно важно при сложных структурах базы данных с множеством внешних ключей.
Фильтрация данных после соединения таблиц
После объединения таблиц часто требуется отфильтровать результат для получения только нужных записей. Для этого используются условия WHERE и ON в сочетании с логическими операторами.
Основные рекомендации при фильтрации после JOIN:
- Использовать WHERE для ограничения итогового набора данных, например: WHERE Orders.OrderDate >= ‘2025-01-01’.
- Применять ON для ограничения соединения только соответствующих строк: INNER JOIN Products ON Orders.ProductID = Products.ProductID AND Products.Category = ‘Электроника’.
- Использовать IN или BETWEEN для фильтрации по множественным значениям или диапазонам.
- Применять функции обработки NULL, например COALESCE, чтобы исключить пустые значения при объединении LEFT или RIGHT JOIN.
Для сложных фильтров рекомендуется разбивать условия на логические блоки и использовать скобки, чтобы избежать ошибок при сочетании AND и OR:
- Сначала фильтруйте по ключевым полям соединения.
- Затем применяйте дополнительные ограничения по датам, категориям или статусам.
- Проверяйте результаты после каждого добавленного условия, чтобы убедиться в корректности выборки.
Отладка и проверка результатов соединений
После выполнения соединений важно проверить корректность выборки и выявить ошибки, такие как дублирование строк или потеря данных.
Основные методы отладки:
- Использовать SELECT COUNT(*) для проверки количества строк после соединения и сопоставления с ожидаемым результатом.
- Проверять наличие NULL в ключевых полях после LEFT или RIGHT JOIN, чтобы определить, где отсутствуют совпадения.
- Применять LIMIT для выборки первых нескольких строк и анализа структуры данных перед выполнением полного запроса.
- Использовать EXPLAIN или EXPLAIN ANALYZE для проверки плана выполнения и выявления неоптимальных соединений.
- Сравнивать промежуточные результаты при многократных JOIN, чтобы убедиться, что каждая таблица добавляет корректные данные.
Рекомендации для упрощения проверки:
- Присваивать алиасы таблицам, чтобы легко различать одинаковые названия полей.
- Отдельно проверять соединение каждой пары таблиц перед объединением всех в одном запросе.
- Использовать агрегатные функции, такие как COUNT или SUM, для контроля целостности данных после соединения.
Вопрос-ответ:
Как выбрать правильный тип соединения между двумя таблицами?
Выбор типа соединения зависит от того, какие данные нужно получить. INNER JOIN возвращает только совпадающие строки, LEFT JOIN сохраняет все строки из основной таблицы, а RIGHT JOIN — все строки из присоединяемой. Анализируя структуру таблиц и количество совпадений ключевых полей, можно определить подходящий тип соединения для конкретной задачи.
Что делать, если соединение возвращает дублированные строки?
Дублирование часто возникает из-за неправильного выбора ключевых полей или множественных совпадений в связанных таблицах. Чтобы устранить это, проверяют уникальность ключей и применяют DISTINCT или группировку GROUP BY по необходимым полям. Также важно анализировать промежуточные соединения при работе с несколькими таблицами.
Как правильно соединять более двух таблиц в одном запросе?
При соединении нескольких таблиц рекомендуется строить цепочку JOIN, начиная с основной таблицы и добавляя другие по мере необходимости. Для каждой пары таблиц нужно явно указывать тип соединения и ключи. Использование алиасов облегчает чтение запроса, а проверка промежуточных результатов помогает выявить ошибки на раннем этапе.
Почему некоторые строки отсутствуют после использования INNER JOIN?
INNER JOIN возвращает только совпадающие строки по указанным ключевым полям. Строки без совпадений не включаются в результат. Если нужно сохранить все записи из одной таблицы, следует использовать LEFT JOIN или RIGHT JOIN в зависимости от того, какая таблица является основной.
Как проверить корректность данных после объединения таблиц?
Для проверки используют SELECT COUNT(*) для контроля количества строк, а также анализируют поля с NULL для выявления отсутствующих связей. Разбивка условий соединения и фильтрации поэтапно, использование EXPLAIN для проверки плана выполнения и тестовые выборки с LIMIT позволяют убедиться, что запрос возвращает точные и полные данные.
Как определить, какой тип JOIN использовать при объединении таблиц с разной структурой данных?
Для выбора типа JOIN сначала анализируют, какие записи нужно сохранить. Если необходимы только совпадения по ключевым полям — применяют INNER JOIN. Когда важно сохранить все строки из основной таблицы, включая те, которые не имеют совпадений — используют LEFT JOIN. Если требуется сохранить все строки из присоединяемой таблицы — применяют RIGHT JOIN. Перед написанием запроса проверяют соответствие типов данных ключевых полей и наличие индексов, чтобы избежать ошибок и снизить нагрузку на сервер.
 (пока оценок нет)
(пока оценок нет)