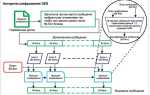
Содержание статьи
Сканы документов в формате JPG часто содержат артефакты, неровные края или нечитаемый текст. Чтобы преобразовать их в редактируемый документ Word, недостаточно просто вставить изображение – требуется распознавание текста и корректировка формата. Встроенные инструменты Microsoft Word позволяют выполнить эту задачу без сторонних программ, но с ограничениями: точность распознавания зависит от качества скана, а ручная правка может занять до 30% времени.
Для работы потребуется Word версии 2013 и новее – в более ранних версиях функция OCR (оптического распознавания символов) отсутствует. Оптимальное разрешение скана – не менее 300 DPI: при меньших значениях точность распознавания падает на 15–20%. Если исходный файл имеет низкое качество, предварительно обработайте его в графическом редакторе: увеличьте контрастность, удалите шумы и выровняйте перспективу.
Word распознает текст только в горизонтальном положении. Если скан повернут, используйте инструмент «Поворот» в разделе «Формат рисунка» перед началом редактирования. Для многостраничных документов сохраните каждую страницу отдельным JPG-файлом – Word не поддерживает пакетную обработку изображений в одном документе.
После распознавания проверьте результат: Word может ошибаться с буквами схожей формы (например, «о» и «0», «л» и «1»). Особое внимание уделите таблицам и спискам – их форматирование часто нарушается. Для исправления ошибок используйте сочетания клавиш Ctrl+F (поиск) и Ctrl+H (замена), чтобы быстро находить и исправлять повторяющиеся неточности.
Как подготовить изображение JPG перед вставкой в Word
Обрежьте лишние поля и фон с помощью инструмента «Кадрирование» (Crop). В Paint.NET или Photoshop выделите нужную область и удалите всё за её пределами. Для сканов с неровными краями используйте функцию «Удаление фона» (например, в GIMP с инструментом «Ножницы» или «Волшебная палочка»). Это сократит объём файла и улучшит визуальную интеграцию с документом.
Корректируйте яркость и контрастность, чтобы текст на скане стал чётким. В Adobe Photoshop откройте «Изображение» → «Коррекция» → «Яркость/Контрастность» и установите значения: яркость +10–20%, контрастность +20–30%. Для автоматической коррекции в IrfanView нажмите Shift+C. Избегайте чрезмерного увеличения контраста – это может привести к потере полутонов и артефактов.
| Параметр | Рекомендуемое значение | Инструмент настройки |
|---|---|---|
| Разрешение (DPI) | 150–300 (текст), 400–600 (детали) | GIMP, IrfanView |
| Формат сжатия | JPG (качество 80–90%) | Photoshop, Paint.NET |
| Цветовой режим | Оттенки серого (текст), RGB (цветные элементы) | Любой графический редактор |
Преобразуйте изображение в оттенки серого, если оно содержит только текст или монохромные элементы. Это уменьшит размер файла в 2–3 раза по сравнению с RGB. В GIMP выберите «Изображение» → «Режим» → «Оттенки серого». Для цветных сканов оставьте RGB, но снизьте насыщенность на 10–15% через «Цветовой баланс», чтобы избежать излишней пестроты.
Сохраните файл в оптимальном формате: JPG с качеством 80–90% для баланса между размером и чёткостью. В Photoshop при сохранении выберите «Сохранить для Web» и установите качество 80%. Если скан содержит прозрачные области (например, логотипы), используйте PNG-24. Перед вставкой в Word проверьте размер файла – он не должен превышать 5 МБ, иначе документ будет медленно открываться.
Какие инструменты Word использовать для распознавания текста на скане
Microsoft Word интегрирован с технологией оптического распознавания символов (OCR) через встроенный функционал «Преобразовать в текст». Чтобы активировать его, откройте скан в формате JPG через меню Файл → Открыть, выберите изображение и нажмите Вставить. Word автоматически предложит преобразовать содержимое в редактируемый текст – подтвердите действие кнопкой ОК. Точность распознавания зависит от качества скана: разрешение не менее 300 DPI и контрастный текст на однородном фоне повышают результат до 95%.
Для ручной корректировки ошибок OCR используйте инструмент Проверка правописания (F7). Word подчеркнёт нераспознанные слова красным, но не полагайтесь на него полностью – алгоритм часто пропускает специфические термины, имена собственные или символы (например, «№», «©»). В таких случаях применяйте Поиск и замена (Ctrl+H) для массовой правки повторяющихся ошибок, например, замены «0» на «О» в словах.
- Надстройки для OCR: Если встроенное распознавание не справляется, установите надстройку Microsoft OneNote или ABBYY FineReader через Файл → Параметры → Надстройки. OneNote бесплатен и поддерживает 27 языков, включая русский, но требует предварительного импорта скана в приложение. FineReader точнее (до 99% для печатного текста), но платный – пробная версия ограничена 10 страницами.
- Языковые пакеты: Для распознавания текста на иностранных языках скачайте соответствующий языковой пакет через Файл → Параметры → Язык. Word поддерживает OCR для 60+ языков, но для редких (например, грузинского или тайского) потребуется стороннее ПО.
При работе с таблицами на сканах используйте Вставка → Таблица → Преобразовать текст в таблицу. Word попытается автоматически определить границы ячеек, но часто ошибается с объединёнными ячейками или сложными макетами. Вручную уточните разделители (например, табуляцию или запятую) в окне преобразования. Для сканов с низким разрешением предварительно обработайте изображение в графическом редакторе (увеличьте контраст, удалите шумы).
Инструмент Рисование → Лассо позволяет выделять фрагменты текста на скане для выборочного распознавания. Это полезно, если на изображении есть рукописные заметки или нечитаемые области. Выделите нужный участок, щёлкните правой кнопкой мыши и выберите Копировать текст с рисунка. Метод работает только для печатного текста и не поддерживает форматирование.
- Откройте скан в Word через Файл → Открыть.
- Дождитесь появления всплывающего окна с предложением преобразовать текст – нажмите ОК.
- Если окно не появилось, щёлкните по изображению правой кнопкой и выберите Копировать текст с рисунка.
- Вставьте текст в документ (Ctrl+V) и проверьте на ошибки.
- Для таблиц используйте Преобразовать текст в таблицу с ручной настройкой разделителей.
- Сохраните результат в формате DOCX для дальнейшего редактирования.
Ограничения встроенного OCR в Word: не распознаёт рукописный текст, плохо работает с цветными фонами и шрифтами размером менее 8 пт. Для таких случаев экспортируйте скан в PDF через Файл → Экспорт → Создать PDF/XPS, затем откройте его в Adobe Acrobat (инструмент Распознать текст → В этом файле) или используйте онлайн-сервисы типа OnlineOCR.net. После распознавания скопируйте текст обратно в Word.
Для пакетной обработки нескольких сканов используйте макросы. Запишите макрос через Вид → Макросы → Записать макрос, выполните преобразование одного скана, затем остановите запись. Назначьте макрос кнопке на панели быстрого доступа и применяйте его ко всем изображениям в папке. Пример кода для автоматизации:
Sub ConvertScansToText() Dim img As InlineShape For Each img In ActiveDocument.InlineShapes img.Range.Select Selection.Copy Selection.PasteSpecial DataType:=wdPasteText Next img End Sub
Как исправить ошибки распознавания после конвертации JPG в текст
Шрифты с засечками (Times New Roman, Georgia) распознаются точнее, чем гротески (Arial, Helvetica). Если исходный документ набран нестандартным шрифтом, замените его в Word на ближайший аналог из списка поддерживаемых OCR-движками: Calibri, Verdana или Courier New. В ABBYY FineReader 15 есть режим «Ручная коррекция шрифта» – выделите проблемный фрагмент и укажите правильный стиль из базы программы.
Ошибки в таблицах исправляйте в два этапа. Сначала экспортируйте таблицу из Word в Excel через «Вставка → Таблица → Экспорт в Excel». Затем используйте функцию «Текст по столбцам» (Данные → Текст по столбцам) для разделения слипшихся ячеек. Если границы таблицы распознались неверно, настройте параметры OCR: в FineReader выберите «Таблица с границами» и укажите толщину линий в пикселях (обычно 1–2 px).
Для исправления опечаток в числовых данных применяйте регулярные выражения. В Word включите поиск с подстановочными знаками (Ctrl+H → Больше → Подстановочные знаки) и используйте шаблоны: `\d{3}-\d{2}-\d{4}` для ИНН, `\d{1,3}(?:[.,]\d{3})*(?:[.,]\d{2})?` для денежных сумм. Это ускорит замену неверно распознанных цифр. В Google Docs аналогичная функция доступна через «Инструменты → Поиск и замена» с включенным режимом «Регулярные выражения».
Специальные символы (©, ®, §, математические знаки) часто заменяются на похожие по начертанию буквы. Восстановите их через автозамену: в Word перейдите в «Файл → Параметры → Правописание → Параметры автозамены» и добавьте правила, например, «(с)» → «©», «тм» → «™». Для массовой замены используйте макросы VBA: запишите макрос с последовательностью замен и запускайте его для каждого документа.
Проверка контекста помогает исправить логические ошибки. Включите в Word функцию «Проверка читаемости» (Файл → Параметры → Правописание → Показывать статистику удобочитаемости) – она выявит неестественные сочетания слов. Для технических текстов используйте специализированные словари: в FineReader добавьте пользовательский словарь с терминами из вашей отрасли (например, медицинские или юридические термины). Это снизит количество ложных срабатываний на редких словах.
После ручной правки сохраните документ в формате DOCX с включенной опцией «Сохранить данные для восстановления». Это позволит вернуться к исходной версии при случайных ошибках. Для финальной проверки экспортируйте текст в PDF с тегами (Файл → Экспорт → Создать PDF/XPS → Параметры → Включить теги документа) – так вы увидите, как текст будет восприниматься программами для чтения с экрана, и сможете исправить оставшиеся проблемы с форматированием.
Какие параметры форматирования применить к отсканированному тексту
Первым шагом после распознавания скана в Word станет корректировка шрифта. Используйте стандартные гарнитуры с высокой читаемостью: Arial (11–12 пт), Times New Roman (12 пт) или Calibri (11 пт). Избегайте декоративных шрифтов – они снижают качество восприятия, особенно при печати. Если исходный документ содержал моноширинный текст (например, код или таблицы), замените его на Consolas или Courier New с размером 10 пт для сохранения выравнивания.
Выравнивание абзацев критически важно для структурированных документов. Для основного текста установите выравнивание по ширине с отступом первой строки 1,25 см – это соответствует ГОСТ для деловых и научных материалов. В таблицах и списках применяйте выравнивание по левому краю, чтобы избежать разрывов между словами. Межстрочный интервал задайте как 1,15 или 1,5 – меньшие значения затрудняют редактирование, большие увеличивают объем документа без необходимости.
Цвет текста по умолчанию должен оставаться черным (#000000) на белом фоне. Исключение – выделение ключевых элементов: заголовки можно оформить темно-синим (#000080) или темно-зеленым (#006400), но не ярче 50% насыщенности. Для ссылок используйте стандартный синий (#0000FF) с подчеркиванием, но только если документ предназначен для цифрового распространения. Избегайте градиентов, теней и других эффектов – они ухудшают качество печати и распознавания при повторном сканировании.
Поля документа настройте в зависимости от его назначения. Для внутреннего использования достаточно 2 см со всех сторон. Для официальных документов установите: верхнее и нижнее – 2 см, левое – 3 см, правое – 1,5 см (требования для большинства российских организаций). Если текст содержит колонтитулы, оставьте дополнительные 1,25 см сверху и снизу. Проверьте параметры страницы: формат A4, ориентация книжная, масштаб 100% – любые отклонения приведут к смещению элементов при печати.
Для улучшения визуальной структуры используйте стили Word. Назначьте заголовкам уровни от «Заголовок 1» до «Заголовок 3» с последовательным форматированием: размер шрифта +2 пт к основному тексту, полужирное начертание, отступы перед и после абзаца 6 пт. Списки оформляйте через инструмент «Маркеры» или «Нумерация» с отступом 0,63 см для второго уровня. Таблицы конвертируйте в формат Word, удаляя границы ячеек, если они не несут смысловой нагрузки, и применяйте автоподбор ширины столбцов.
Как сохранить отредактированный документ с исходным качеством
После редактирования скана в Word критически важно сохранить документ без потери качества изображения. По умолчанию Word экспортирует файлы в форматы, оптимизированные для текста, что приводит к сжатию графики. Чтобы избежать этого, используйте следующие методы.
Первый шаг – экспорт в PDF с настройками высокого разрешения. В Word перейдите в Файл → Экспорт → Создать PDF/XPS. В окне параметров выберите Оптимизация: Стандарт (публикация в Интернете и печать). Убедитесь, что флажок Совместимость с ISO 19005-1 (PDF/A) снят – он ограничивает качество. Для сканов с разрешением 300 DPI и выше установите параметр Качество изображения: Максимальное.
Если требуется сохранить документ в формате Word для дальнейшего редактирования, избегайте повторного сжатия изображений. Вставленные сканы должны быть в форматах TIFF или PNG с разрешением не ниже 200 DPI. Перед сохранением выполните:
- Выделите все изображения в документе.
- Щелкните правой кнопкой мыши и выберите Формат рисунка → Сжатие рисунков.
- Снимите флажок Применить только к этому рисунку и выберите Не сжимать.
- В разделе Разрешение установите Использовать разрешение документа.
Для сохранения в формате DOCX без потерь используйте архиватор. DOCX – это ZIP-архив с XML-файлами и изображениями. Чтобы извлечь оригиналы сканов:
- Переименуйте файл .docx в .zip.
- Распакуйте архив и перейдите в папку word/media.
- Скопируйте изображения – они сохранятся в исходном качестве.
При необходимости передать документ с минимальными потерями используйте формат PDF/A-3. Он поддерживает вложенные файлы, включая оригиналы изображений. В Word выберите Файл → Экспорт → PDF/XPS → Параметры, затем установите Стандарт: PDF/A-3b и добавьте изображения через Вложения. Это гарантирует сохранность исходных данных при печати или архивировании.
Избегайте сохранения в форматах JPG или GIF для многостраничных документов – они не предназначены для текста и сканов. Если требуется именно JPG, экспортируйте каждую страницу отдельно через специализированные программы (например, Adobe Acrobat) с параметрами сжатия Без потерь или Максимальное качество.
Для проверки качества после сохранения используйте инструменты анализа. В Adobe Acrobat откройте PDF и выберите Файл → Свойства → Описание – разрешение изображений должно совпадать с исходным. В Word проверьте размер файла: если он резко уменьшился, вероятно, произошло сжатие. В таком случае повторите сохранение с другими настройками.
Если документ содержит критически важные сканы (например, юридические или медицинские), дублируйте оригиналы в отдельной папке. При сохранении в Word добавьте в название файла суффикс _оригинал_качество и используйте облачные хранилища с поддержкой версий (Google Drive, OneDrive) для отката к предыдущей версии при необходимости.
Вопрос-ответ:
Можно ли отредактировать скан JPG прямо в Word, не используя другие программы?
Да, в Microsoft Word есть встроенные инструменты, которые позволяют работать со сканированными изображениями в формате JPG. Однако возможности ограничены: вы сможете обрезать картинку, изменить её размер, яркость или контрастность, но редактировать текст напрямую не получится. Для этого потребуется преобразовать изображение в текст с помощью функции распознавания (OCR), которая доступна в Word через «Вставка» → «Рисунок» → «Из файла», а затем через контекстное меню («Копировать текст с рисунка»). Если текст распознаётся плохо, лучше воспользоваться специализированными программами вроде ABBYY FineReader.