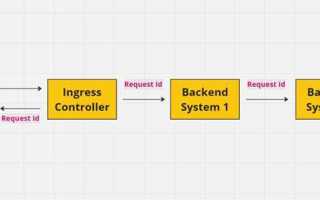
Request ID – это уникальный идентификатор, присваиваемый каждому входящему запросу в рамках сервиса или цепочки сервисов. Его основная задача – связать все операции, связанные с обработкой одного запроса, независимо от количества компонентов, баз данных и внешних API, задействованных в процессе. Без такого идентификатора анализ поведения системы при сбоях или аномалиях превращается в ручной просмотр несвязанных логов.
В распределённых архитектурах Request ID передаётся между сервисами через HTTP-заголовки, gRPC-метаданные или сообщения брокеров. На практике чаще всего используется заголовок X-Request-ID или Trace-Id, значение которого сохраняется и прокидывается на каждом этапе обработки. Это позволяет собрать сквозную картину запроса: от точки входа до последнего сервиса, даже если обработка заняла секунды или минуты.
При корректной реализации Request ID должен генерироваться один раз – на границе системы – и далее использоваться без изменений. Для генерации подходят UUID v4 или короткие хэш-идентификаторы длиной 16–32 символа, устойчивые к коллизиям. Не рекомендуется включать в Request ID бизнес-данные, IP-адреса или временные метки, так как это усложняет парсинг логов и может создать риски утечки информации.
В логировании Request ID должен записываться в каждой строке, относящейся к запросу: ошибки, предупреждения, вызовы внешних сервисов, обращения к базе данных. Это упрощает фильтрацию логов и ускоряет поиск причин проблем в production-среде. В системах мониторинга и APM Request ID используется как связующее звено между логами, трассировкой и метриками.
Что такое Request ID и какую задачу он решает в распределённых сервисах
Основная задача Request ID – обеспечить однозначную корреляцию событий, которые происходят в разных компонентах системы. Без него записи логов, метрики и трассировки остаются разрозненными и не позволяют восстановить порядок действий при сбоях или деградации производительности.
Request ID решает сразу несколько прикладных задач:
- объединение логов разных сервисов по одному запросу без анализа временных меток;
- поиск причины ошибки, возникшей в середине цепочки вызовов;
- проверка корректности маршрутизации запросов между сервисами;
- сопоставление пользовательского запроса с техническими событиями в системе.
В корректной реализации Request ID создаётся на границе системы – например, на уровне API-шлюза или первого backend-сервиса – и далее передаётся без изменений. Генерация нового идентификатора на промежуточных этапах лишает его диагностической ценности и затрудняет анализ.
Для распределённых сервисов рекомендуется использовать формат, устойчивый к коллизиям и удобный для чтения в логах:
- UUID v4 для систем с высокой нагрузкой и большим числом узлов;
- короткие строковые идентификаторы длиной 16–32 символа при жёстких ограничениях на размер заголовков;
- один тип кодировки во всей системе без смешивания форматов.
Request ID не должен содержать бизнес-данные, идентификаторы пользователей или сведения об инфраструктуре. Его роль ограничивается технической связкой операций, что упрощает хранение логов, снижает риски утечки информации и делает анализ поведения распределённых сервисов предсказуемым.
Формирование Request ID на стороне клиента и сервера
Формирование Request ID возможно как на стороне клиента, так и на стороне сервера, при этом выбор точки генерации напрямую влияет на диагностические возможности системы. Если клиент способен генерировать идентификатор заранее, сервер получает сквозной контекст запроса ещё до начала обработки и может связать backend-события с конкретным действием пользователя.
На клиентской стороне Request ID обычно создаётся в момент инициации запроса: при отправке HTTP-запроса, gRPC-вызова или публикации сообщения в очередь. Для генерации используются UUID v4 или псевдослучайные строки фиксированной длины. Идентификатор передаётся в заголовках или метаданных и не изменяется при повторных попытках запроса, что позволяет отличить ретраи от новых обращений.
Серверное формирование Request ID применяется, когда клиент не поддерживает передачу идентификаторов или не считается доверенным источником. В этом случае сервер проверяет наличие Request ID во входящих данных и создаёт новый только при его отсутствии. Такой подход позволяет сохранить единый формат идентификаторов и избежать конфликтов между различными клиентскими реализациями.
На стороне сервера Request ID должен создаваться до начала бизнес-логики, сразу после приёма запроса. Это гарантирует, что все последующие операции – аутентификация, валидация, обращения к внешним сервисам и базе данных – будут зафиксированы с одним и тем же идентификатором в логах и системах наблюдения.
Независимо от точки генерации, важно соблюдать единые правила: один Request ID на один логический запрос, отсутствие повторной генерации внутри цепочки вызовов и строгая проверка формата входящего значения. Это снижает вероятность ошибок при корреляции событий и упрощает анализ поведения системы при нагрузке и сбоях.
Передача Request ID между сервисами по HTTP и очередям сообщений

При синхронных HTTP-вызовах Request ID добавляется ко всем внутренним запросам, включая обращения к сторонним API. Если внешний сервис не поддерживает пользовательские заголовки, идентификатор сохраняется локально и используется только для логирования и трассировки внутри системы.
В асинхронных сценариях с брокерами сообщений Request ID передаётся в метаданных сообщения или в его заголовках, если формат очереди это допускает. Для систем вроде Kafka, RabbitMQ или SQS предпочтительно использовать служебные headers, а не тело сообщения, чтобы идентификатор был доступен до десериализации полезной нагрузки.
При обработке сообщений потребитель обязан извлекать Request ID из метаданных и устанавливать его в контекст выполнения до начала бизнес-логики. Это позволяет связать публикацию сообщения, его доставку и обработку в разных сервисах в одну цепочку событий, даже если между этапами проходит значительное время.
Особое внимание требуется при fan-out и batch-обработке. Если один запрос порождает несколько сообщений, каждое сообщение должно содержать тот же Request ID. При объединении нескольких сообщений в одну операцию необходимо явно выбирать стратегию: либо использовать один из входящих идентификаторов, либо фиксировать новый идентификатор с сохранением исходных значений в логах для последующего анализа.
Использование Request ID для трассировки запросов в логах
Request ID используется в логах как ключ корреляции, позволяющий собрать все записи, относящиеся к одному запросу, вне зависимости от сервиса, потока или узла. Каждый логируемый шаг обработки должен содержать идентификатор в отдельном поле, а не в тексте сообщения, чтобы системы агрегации логов могли фильтровать и группировать данные без дополнительного парсинга.
На практике Request ID добавляется в контекст логирования сразу после приёма запроса. Для backend-приложений это означает автоматическую подстановку значения во все записи текущего потока выполнения. В распределённых системах отсутствие Request ID хотя бы в одном сервисе разрывает цепочку и делает трассировку неполной.
Для удобства анализа рекомендуется придерживаться единых правил оформления логов: фиксированное имя поля, строковый тип значения, отсутствие сокращений и вариаций формата. Примером корректного подхода является поле request_id, присутствующее в каждой записи уровня debug, info, warning и error.
При возникновении ошибки Request ID позволяет восстановить последовательность событий: входной запрос, промежуточные вызовы, обращения к базе данных и ответ клиенту. Это снижает время поиска причины сбоя, так как инженер работает не с временным диапазоном, а с точным набором связанных записей.
В системах централизованного логирования Request ID применяется как основной фильтр при анализе инцидентов. По одному значению можно отследить запрос даже в случаях, когда сервисы находятся в разных дата-центрах или используют разные форматы логов, при условии сохранения идентификатора на всех этапах обработки.
Поиск и анализ ошибок по Request ID в мониторинге
Request ID используется в системах мониторинга как связующее звено между логами, трассировкой и метриками. При поступлении алерта инженер может взять значение идентификатора из сообщения об ошибке и использовать его как ключ для точечного анализа, не просматривая общий поток событий за период времени.
В APM и системах наблюдения Request ID связывается с трассами выполнения. Это позволяет определить, на каком сервисе произошёл сбой, какой вызов стал источником ошибки и сколько времени запрос провёл на каждом этапе. Такой подход особенно полезен при нестабильных ошибках, которые не воспроизводятся при повторных запросах.
Для корректного анализа Request ID должен присутствовать в следующих источниках данных:
| Источник | Роль Request ID |
|---|---|
| Логи сервисов | Корреляция всех записей, связанных с одним запросом |
| Трассировки | Восстановление цепочки вызовов между сервисами |
| Алерты мониторинга | Быстрый переход от ошибки к конкретному запросу |
| Метрики ошибок | Связь агрегированных показателей с конкретными инцидентами |
При анализе ошибки по Request ID рекомендуется начинать с конечного сервиса, где зафиксирован сбой, и последовательно двигаться назад по цепочке вызовов. Это позволяет выявить первопричину, а не симптом, например таймаут, вызванный задержкой в зависимом компоненте.
Для снижения времени реакции стоит настроить автоматическую подстановку Request ID в ссылки из алертов на систему логирования и трассировки. В таком случае один клик по уведомлению сразу открывает полный контекст запроса, включая параметры вызовов и сообщения об ошибках.
Хранение и формат Request ID требования и ограничения

Request ID должен храниться в виде строки фиксированного формата, чтобы его можно было безопасно передавать между сервисами и сохранять в логах, базах данных и системах мониторинга. Стандартные варианты – UUID v4 длиной 36 символов или короткие хэшированные идентификаторы длиной 16–32 символа.
При выборе формата важно учитывать следующие требования:
- уникальность идентификатора во всей системе, чтобы избежать коллизий при высокой нагрузке;
- отсутствие чувствительных данных и бизнес-информации, чтобы снизить риски утечки;
- совместимость с заголовками HTTP и метаданными сообщений в очередях, включая допустимые символы;
- поддержка быстрого поиска и фильтрации в логах и мониторинговых системах.
Хранение Request ID в базах данных должно учитывать тип поля: чаще всего используется CHAR или VARCHAR с длиной, соответствующей формату идентификатора. Для систем с большим количеством запросов рекомендуется индексировать поле request_id, чтобы ускорить выборку при поиске по конкретному запросу.
Не допускается изменение Request ID на промежуточных этапах обработки. Любое преобразование формата или генерация нового идентификатора разрывает связь между событиями и делает невозможной точную корреляцию логов и трассировки.
При интеграции с внешними системами следует согласовывать формат Request ID заранее, чтобы исключить несовместимость, например, если сторонний API не принимает символы дефиса или имеет ограничение на длину заголовка.
Вопрос-ответ:
Зачем нужен Request ID в микросервисной архитектуре?
Request ID позволяет отслеживать один запрос через все сервисы, участвующие в его обработке. Даже если запрос проходит через несколько микросервисов, очередей сообщений и баз данных, идентификатор связывает все операции в логах и системах мониторинга. Это помогает быстро выявить, на каком этапе возникла ошибка, и определить последовательность действий, приведших к сбою.
Как правильно генерировать Request ID на клиенте и сервере?
На клиенте Request ID создаётся при формировании запроса и передаётся в заголовке или метаданных сообщения. На сервере идентификатор проверяется: если отсутствует, создаётся новый. Для генерации подходят UUID v4 или короткие уникальные строки длиной 16–32 символа. Главное — использовать единый формат на всех этапах обработки и не включать в идентификатор бизнес-данные или временные метки.
Какие ошибки возникают при неправильной передаче Request ID между сервисами?
Если Request ID не передаётся или изменяется в процессе обработки, теряется возможность корреляции логов и трассировки. Это усложняет поиск причины ошибки и анализ производительности. В асинхронных системах, при работе с очередями сообщений, отсутствие идентификатора делает невозможным точное сопоставление публикации и обработки сообщений, что увеличивает время расследования инцидентов.
Как Request ID используется для анализа ошибок в логах и мониторинге?
Request ID позволяет собрать все события одного запроса в единую цепочку. В логах идентификатор добавляется к каждой записи, что упрощает фильтрацию и поиск. В системах мониторинга и трассировки Request ID связывает метрики, алерты и сообщения об ошибках с конкретным запросом. Это позволяет быстро определить сервис, где произошёл сбой, и проследить последовательность операций, вплоть до обращения к базе данных.
Какие требования к хранению и формату Request ID?
Request ID должен храниться в виде строки фиксированной длины, совместимой с логами, базами данных и заголовками HTTP. Рекомендуется использовать UUID v4 или короткие уникальные строки 16–32 символа. Поле request_id в базе данных лучше индексировать для ускорения поиска. Идентификатор нельзя изменять на промежуточных этапах, а при интеграции с внешними системами нужно согласовать формат, чтобы избежать конфликтов и потери корреляции.