Содержание статьи

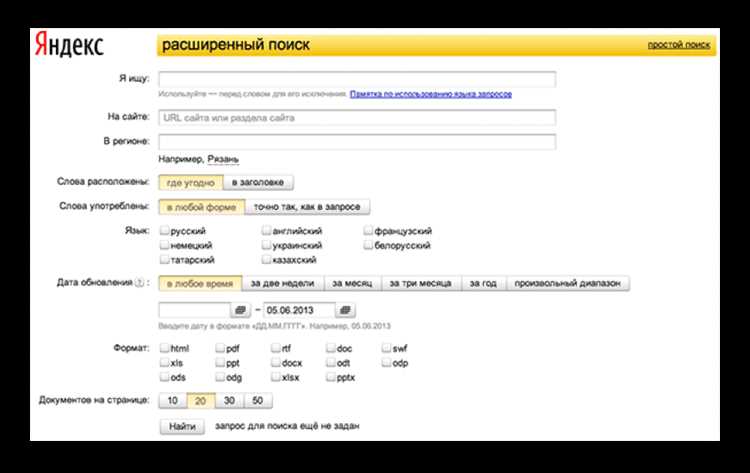
Поиск по сайту – это точка принятия решений, а не вспомогательная функция. По данным аналитики e-commerce и контентных проектов, до 30–60 % пользователей хотя бы один раз используют поиск за сессию, а их конверсия обычно выше, чем у посетителей, идущих по навигации. Если поиск возвращает нерелевантные результаты, не учитывает форму слова или игнорирует популярные запросы, пользователь покидает сайт независимо от качества контента.
Настройка поиска начинается не с выбора инструмента, а с понимания что именно ищут и в каком контексте. Для интернет-магазина это артикулы, характеристики и бренды, для медиа – темы, имена и форматы материалов, для B2B-сайта – решения конкретных задач. Эти различия определяют структуру индекса, логику ранжирования и набор полей, участвующих в поиске.
Практическая настройка включает работу с индексом, обработку пользовательских запросов и оформление результатов. Поиск должен учитывать морфологию русского языка, частые опечатки, сокращения и синонимы, а также уметь исключать устаревший или служебный контент. Не менее важно собирать статистику: запросы без результатов, клики по позициям, время до первого действия. Эти данные напрямую показывают, где поиск не выполняет свою задачу.
В статье разобраны прикладные шаги настройки поиска: от выбора архитектуры и подготовки данных до анализа запросов и доработки выдачи. Материал ориентирован на владельцев сайтов, маркетологов и специалистов, отвечающих за пользовательский опыт и конверсию.
Определение целей поиска и сценариев поведения посетителей
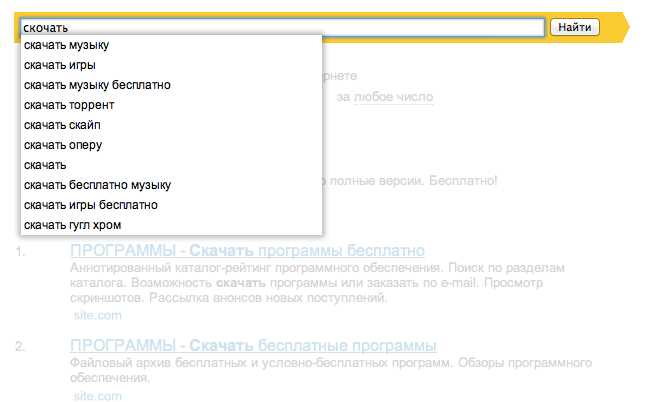
Цели поиска формируются из задач, которые пользователь не может или не хочет решать через меню. Для их определения необходимо проанализировать данные веб-аналитики: долю сессий с использованием поиска, среднее число запросов за визит, процент запросов без кликов. Если более 15–20 % запросов не приводят к переходу по результатам, это сигнал о несоответствии логики поиска ожиданиям аудитории.
Сценарии поведения фиксируются на основе реальных запросов. Запросы вида «купить + характеристика», «модель + цена», «документ + формат» указывают на потребность в точном совпадении и быстром доступе. Короткие обобщённые запросы («доставка», «гарантия», «инструкция») показывают, что пользователи используют поиск как навигацию. Для каждого типа сценария требуется отдельная логика ранжирования и набор источников данных.
Дополнительно важно разделить цели поиска по типам пользователей. Новые посетители чаще вводят общие запросы и ожидают поясняющие результаты, постоянные – точные названия и артикулы. Это различие влияет на порядок выдачи: для первых выше должны быть страницы категорий и справочные материалы, для вторых – конкретные товары, статьи или файлы.
Результаты анализа необходимо зафиксировать в виде списка приоритетных сценариев: что ищут чаще всего, какие запросы приводят к отказам, какие действия совершаются после поиска. Этот список становится основой для настройки индекса, обработки синонимов и формирования структуры страницы результатов.
Выбор типа поиска: встроенный, сторонний сервис или собственная реализация
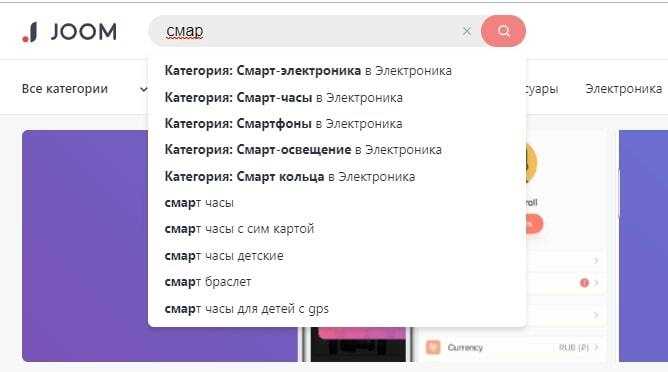
Сторонние поисковые сервисы целесообразны, когда требуется поддержка морфологии русского языка, автодополнение и обработка опечаток без разработки с нуля. Такие решения индексируют данные отдельно от основного сайта и возвращают результаты через API, снижая нагрузку на сервер. Критично заранее проверить, можно ли управлять весами полей, исключениями и логикой ранжирования, иначе поиск будет работать по универсальным правилам, не учитывающим специфику проекта.
Собственная реализация оправдана для проектов с нестандартной структурой данных, сложными фильтрами или высокими требованиями к контролю выдачи. В этом случае используются отдельные поисковые движки с индексами, формируемыми из подготовленных данных. Необходимо учитывать затраты на разработку, поддержку и обновление индекса, а также настройку мониторинга: без регулярного анализа логов качество поиска быстро снижается.
Выбор типа поиска должен опираться на объём контента, частоту обновлений и сценарии использования. Если поиск выполняет роль навигации – достаточно готового решения. Если он влияет на конверсию, поддержку клиентов или доступ к критичным данным, экономия на архитектуре приводит к потерям, которые сложно компенсировать последующими доработками.
Настройка индексации контента и исключений из поиска
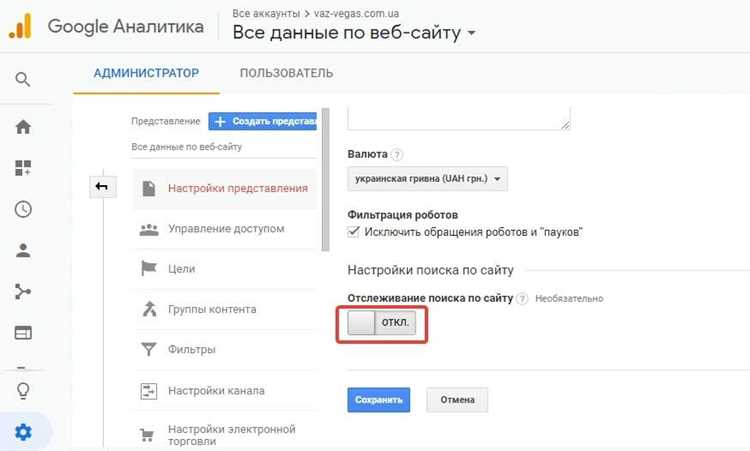
Индекс поиска должен содержать только тот контент, который решает задачи пользователей. Первым шагом формируется перечень сущностей для индексации: страницы, товары, статьи, документы, справочные блоки. Если в индекс попадают служебные разделы, архивы или дубликаты, релевантность выдачи снижается, а время ответа увеличивается.

Для каждой сущности необходимо определить набор полей и их приоритет. Практика показывает, что поиск по всему тексту без весов приводит к хаотичным результатам. Рекомендуется задать разные коэффициенты значимости:
- заголовок и наименование объекта;
- основные характеристики и атрибуты;
- краткое описание или аннотация;
- вспомогательный текст и метаданные.
Исключения из индекса должны настраиваться явно. В первую очередь убираются элементы, которые часто совпадают с запросами, но не должны отображаться в выдаче:
- страницы «Спасибо», «Успешно отправлено», системные уведомления;
- личные кабинеты и технические разделы;
- устаревшие материалы и товары без возможности заказа;
- параметрические дубликаты и фильтры без самостоятельной ценности.
Обновление индекса следует привязывать к изменениям контента. Для динамических сайтов критично поддерживать частичную переиндексацию: пересобирать только изменённые объекты, а не весь массив данных. Это снижает нагрузку и позволяет пользователям видеть актуальные результаты без задержек.
После настройки необходимо проверить индекс вручную: выполнить тестовые запросы по ключевым сценариям, оценить порядок выдачи и наличие лишних элементов. Любые найденные несоответствия корректируются на уровне структуры данных, а не визуального отображения результатов.
Вопрос-ответ:
Нужно ли настраивать поиск отдельно для разных типов контента на сайте?
Да, если на сайте есть товары, статьи, документы и справочные страницы, их нельзя обрабатывать одинаково. Пользователь, вводящий артикул, ожидает увидеть карточку товара, а не обзорную статью. Для этого каждому типу контента задают собственные поля индексации и правила сортировки, а также ограничивают источники выдачи для отдельных сценариев запросов.
Почему поиск часто возвращает страницы, которые не имеют отношения к запросу?
Чаще всего причина в отсутствии весов полей и переиндексации всего текста без приоритетов. Если служебные блоки, футер или повторяющиеся элементы участвуют в поиске наравне с заголовками, они создают ложные совпадения. Решение — исключить такие зоны из индекса и повысить значимость ключевых полей.
Как понять, какие запросы пользователи не могут закрыть через поиск?
Для этого анализируют логи поисковых запросов: запросы без кликов, запросы с быстрым возвратом к поисковой строке, повторяющиеся формулировки за одну сессию. Если один и тот же запрос регулярно не приводит к переходу, значит в индексе нет нужного контента или он скрыт низко в выдаче.
Имеет ли смысл добавлять автодополнение и подсказки?
Автодополнение снижает число ошибок и сокращает время до результата. Оно особенно полезно на сайтах с большим каталогом или сложной терминологией. Подсказки формируются из популярных запросов и структуры данных, но должны обновляться регулярно, иначе они перестают отражать реальные интересы аудитории.
Как часто нужно пересобирать поисковый индекс?
Частота зависит от динамики контента. Для интернет-магазинов с обновлением цен и наличия индекс пересобирают частично — при каждом изменении объекта. Для статейных проектов достаточно плановой переиндексации раз в несколько часов или суток. Полная пересборка применяется только при изменении структуры данных или логики поиска.