Преобразование матрицы в вектор применяется при подготовке данных для численных расчётов, обучения моделей и передачи массивов в алгоритмы, принимающие одномерный вход. Например, при работе с изображениями матрица размером 28×28 часто приводится к вектору длиной 784, чтобы использовать её в линейных моделях или при вычислении скалярных произведений. Ошибка на этом этапе приводит к смещению признаков и некорректным результатам, поэтому порядок элементов и выбранный способ разворачивания имеют принципиальное значение.
На практике чаще всего используются два варианта: построчное и поколоночное преобразование. В среде Python и NumPy по умолчанию применяется порядок C-order, при котором элементы считываются строка за строкой. В MATLAB и Fortran распространён F-order, где обход идёт по столбцам. При переносе кода между инструментами необходимо явно задавать порядок разворачивания, иначе одинаковая матрица будет преобразована в разные векторы.
Отдельного внимания требует работа с размерностями. Матрица n×m после преобразования может быть представлена как вектор формы (n·m,) или как столбец (n·m, 1). Выбор влияет на совместимость операций умножения и конкатенации. В задачах линейной алгебры чаще нужен столбец, а при передаче данных в библиотеки машинного обучения – одномерный массив.
При обработке разреженных матриц важно учитывать формат хранения. Прямое преобразование в плотный вектор увеличивает потребление памяти и время выполнения. В таких случаях рекомендуется сначала определить, какие элементы реально участвуют в вычислениях, и только затем выполнять разворачивание с сохранением индексов. Такой подход снижает риск переполнения памяти и упрощает отладку вычислительных пайплайнов.
Когда требуется преобразование матрицы в вектор в прикладных задачах

Преобразование матрицы в вектор требуется, когда алгоритм принимает на вход одномерный массив фиксированной длины. Типичный пример – линейная регрессия и логистическая классификация, где каждый объект должен быть представлен в виде вектора признаков. Матрица признаков n×m, описывающая один объект, перед подачей в модель приводится к вектору длиной n·m, иначе вычисление скалярного произведения становится невозможным.
В задачах компьютерного зрения изображения хранятся в виде матриц или тензоров, но на этапе обучения простых моделей их часто разворачивают. Например, изображение 64×64 в градациях серого преобразуется в вектор из 4096 элементов. Такой формат требуется при использовании методов главных компонент, где входные данные задаются в виде набора векторов одинаковой длины.
Преобразование также применяется при передаче данных между библиотеками с разными требованиями к размерности. NumPy допускает работу с многомерными массивами, а многие реализации оптимизационных алгоритмов ожидают одномерный вход. Перед вызовом функции оптимизации матрица параметров разворачивается в вектор, а после вычислений результат собирается обратно в исходную форму.
В численных методах, связанных с решением систем уравнений, матричные данные нередко переводятся в вектор для формирования правой части уравнения или задания начальных условий. Например, при решении задачи теплопроводности на сетке значения температуры в узлах сетки хранятся в матрице, но итерационные методы требуют вектор состояния, упорядоченный по заранее выбранному правилу обхода.
При сериализации данных для хранения или передачи по сети матрицы часто преобразуются в векторы или плоские массивы. Это упрощает запись в бинарные форматы и снижает риск ошибок при восстановлении структуры. В таких случаях рекомендуется явно фиксировать порядок разворачивания и размеры исходной матрицы, чтобы избежать смещения элементов при обратном преобразовании.
Различия между построчным и поколоночным разворачиванием матрицы
Построчное и поколоночное разворачивание определяют порядок, в котором элементы матрицы переносятся в одномерный массив. Для матрицы размером 3×3 с элементами, пронумерованными по строкам, выбор способа меняет не форму, а содержимое итогового вектора. Это влияет на результаты умножений, вычисление градиентов и сопоставление признаков.
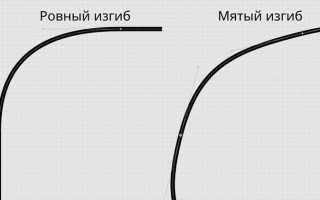
- Построчное разворачивание – элементы считываются слева направо, строка за строкой. Матрица [[a, b], [c, d]] преобразуется в вектор [a, b, c, d].
- Поколоночное разворачивание – обход идёт сверху вниз по столбцам. Та же матрица принимает вид [a, c, b, d].
В практических вычислениях важно учитывать, что Python и NumPy используют построчный порядок как стандарт, тогда как MATLAB и Fortran работают с поколоночным. При переносе данных между этими средами одинаковый код без явного указания порядка создаёт разные векторы, что приводит к расхождениям в численных результатах.
Выбор способа должен соответствовать математической модели. Если матрица описывает набор признаков, сгруппированных по строкам, построчное разворачивание сохраняет их логическую связанность. При работе с операторами, заданными в столбцовом виде, предпочтительнее поколоночный обход.
- Определить, что именно представляют строки и столбцы матрицы.
- Зафиксировать порядок разворачивания в коде и документации.
- Проверить результат на небольшом примере перед запуском расчётов.
Игнорирование этих различий чаще всего проявляется не в ошибках выполнения, а в неверных числах на выходе, поэтому контроль порядка элементов должен быть частью проверки входных данных.
Преобразование матрицы в вектор при работе с линейной алгеброй

В линейной алгебре преобразование матрицы в вектор используется при приведении операций к стандартному виду, удобному для умножения и решения систем уравнений. Матрица коэффициентов или значений часто разворачивается в вектор, чтобы применить матричное умножение с оператором фиксированной размерности. Например, матрица n×m переводится в вектор длиной n·m для работы с блочной матрицей размера (n·m)×(n·m).
При решении линейных систем методами Крылова или градиентного спуска состояние системы задаётся в виде вектора. Если исходные данные заданы в виде матрицы, например значений на двумерной сетке, их необходимо упорядочить по заранее выбранному правилу. Нарушение этого порядка приводит к тому, что оператор системы применяется к неверным элементам, и итерации сходятся к ошибочному решению.
Отдельное применение связано с операцией векторизации, обозначаемой как vec(A). Она переводит матрицу A в столбец и позволяет переписать матричные равенства в векторной форме. Так, выражение AXB = C может быть преобразовано в систему (Bᵀ ⊗ A)·vec(X) = vec(C), где ⊗ – кронекерово произведение. Без разворачивания матрицы такое преобразование невозможно.
На практике рекомендуется явно фиксировать, используется ли построчная или поколоночная векторизация, и придерживаться этого выбора во всех формулах и вычислениях. При работе с учебными формулами и программной реализацией важно сверять соглашения, так как большинство теоретических источников предполагают поколоночную векторизацию, а программные библиотеки часто применяют построчную.
Перед масштабными вычислениями полезно проверить корректность преобразования на матрице малого размера, вычислив результат вручную. Это позволяет выявить несоответствие порядка элементов до того, как ошибка начнёт искажать результаты численных методов.
Разворачивание матрицы в вектор в NumPy и распространённые ошибки
В NumPy для разворачивания матрицы в вектор чаще всего применяются методы ravel(), flatten() и reshape(-1). Все они возвращают одномерный массив, но различаются поведением по отношению к памяти. ravel() по возможности создаёт представление без копирования данных, тогда как flatten() всегда формирует новый массив. При работе с большими матрицами это напрямую отражается на потреблении памяти и времени выполнения операций.
Распространённая ошибка связана с неявным использованием порядка элементов. По умолчанию NumPy применяет построчный обход, и разработчик часто предполагает, что результат совпадёт с формулами из учебников линейной алгебры, где принят поколоночный порядок. Чтобы избежать несоответствий, необходимо явно указывать параметр order, особенно при обмене данными с MATLAB или при реализации алгоритмов из теоретических источников.
Ещё одна типичная проблема – путаница между одномерным массивом формы (n,) и вектором-столбцом формы (n, 1). Многие операции умножения в NumPy дают разный результат в зависимости от формы. После разворачивания матрицы следует проверять размерность с помощью shape и при необходимости выполнять дополнительное преобразование.
Ошибки возникают и при модификации исходных данных. Если результат ravel() используется для изменения элементов, изменения могут отразиться на исходной матрице. Это поведение полезно при осознанном использовании, но при отсутствии контроля приводит к трудноуловимым багам. Когда требуется изолированный вектор, предпочтительнее создавать копию.
Для проверки корректности разворачивания рекомендуется сравнивать результат с ожидаемым порядком на матрицах малого размера и фиксировать выбранный способ преобразования в коде. Такой подход снижает риск логических ошибок при дальнейшем расширении вычислений.
Использование reshape и flatten для получения вектора из матрицы
Методы reshape и flatten в NumPy позволяют преобразовать матрицу в одномерный массив, но имеют различия в поведении и применении. reshape(-1) создаёт представление данных без копирования, если это возможно, и поддерживает изменение формы на лету. Например, матрица 3×4 после вызова matrix.reshape(-1) превращается в вектор длиной 12, сохраняя порядок элементов в построчном обходе по умолчанию.
flatten() всегда создаёт новый массив, копируя данные. Это удобно, если исходная матрица должна остаться неизменной, и требуется полностью независимый вектор. Для контроля порядка элементов можно использовать параметр order=’F’ для поколоночного разворачивания или order=’C’ для построчного.
При использовании этих методов важно учитывать размерность исходной матрицы и совместимость с последующими операциями. Например, вектор из матрицы (m×n) можно сразу подать на вход функции линейной алгебры, ожидающей одномерный массив, но при умножении на матрицу-столбец может потребоваться дополнительное изменение формы с помощью reshape(-1,1).
Для сложных вычислительных пайплайнов рекомендуется придерживаться одного метода разворачивания и фиксировать порядок обхода. Это предотвращает рассогласование данных при передаче между функциями и библиотеками, особенно если вектор будет участвовать в конкатенации или умножении на другие массивы.
Перед массовым применением полезно протестировать оба метода на небольшой матрице и убедиться, что порядок элементов совпадает с ожидаемым для алгоритма. Это позволяет избежать ошибок, которые проявляются только на больших наборах данных.
Преобразование разреженной матрицы в вектор без потери данных
Разреженные матрицы содержат преимущественно нулевые элементы, и их прямое преобразование в плотный вектор увеличивает потребление памяти и замедляет вычисления. Для сохранения структуры данных и уменьшения объёма рекомендуется использовать специализированные форматы хранения, такие как CSR (Compressed Sparse Row) или CSC (Compressed Sparse Column).
Алгоритм преобразования разреженной матрицы в вектор обычно включает следующие шаги:
- Определение формата хранения: CSR подходит для построчного разворачивания, CSC – для поколоночного.
- Извлечение непустых элементов и их индексов с помощью методов data и indices.
- Создание вектора фиксированной длины, равной произведению числа строк на число столбцов, с заполнением нулями на местах отсутствующих элементов.
Пример в Python с использованием SciPy:
from scipy.sparse import csr_matrix
matrix = csr_matrix([[0, 2, 0], [3, 0, 4]])
vector = matrix.toarray().reshape(-1)
Такой подход гарантирует, что все элементы, включая нули, сохранят своё положение. При необходимости уменьшить объём памяти можно хранить только непустые элементы и соответствующие индексы, передавая их в алгоритмы, поддерживающие разреженные форматы.
При обработке больших данных важно контролировать порядок элементов и соответствие формата хранения требованиям вычислительных методов. Несоблюдение этих правил приводит к смещению признаков и искажению результатов аналитики или обучения моделей.
Как сохранить порядок элементов при преобразовании матрицы
Сохранение порядка элементов при разворачивании матрицы критично для корректной работы алгоритмов, где позиция каждого элемента несёт смысловую нагрузку. Основные рекомендации:
- Определить, используется ли построчное (C-order) или поколоночное (F-order) преобразование.
- Явно указывать порядок при вызове методов reshape, flatten или ravel в NumPy с параметром order.
- Проверять результат на небольшой матрице до применения к большим данным.
Для наглядного контроля порядка элементов можно использовать таблицу соответствия между исходной матрицей и результирующим вектором:
| Исходная матрица | Построчное разворачивание | Поколоночное разворачивание |
|---|---|---|
[[a, b], [c, d]] |
[a, b, c, d] |
[a, c, b, d] |
При работе с разреженными матрицами рекомендуется контролировать порядок через индексы непустых элементов. Любое смешение строк и столбцов на этапе разворачивания приводит к некорректным результатам при последующих операциях, включая матричные умножения и обучение моделей.
Фиксация порядка должна сопровождаться документацией и тестами. Даже при небольших матрицах проверка соответствия элементов вектору и исходной матрице позволяет избежать ошибок при масштабировании данных.
Практические примеры преобразования матрицы в вектор в машинном обучении
В машинном обучении преобразование матрицы в вектор применяется для подготовки данных к алгоритмам, которые ожидают одномерные массивы. Например, изображения в градациях серого размером 28×28 пикселей разворачиваются в вектор длиной 784 для подачи в линейные модели или нейронные сети. Векторы сохраняют порядок пикселей, что критично для корректного обучения.
Для работы с цветными изображениями матрица height×width×channels сначала преобразуется в двумерную форму (height·width)×channels, а затем в одномерный массив, если алгоритм требует плоский вход. В NumPy это делается с помощью reshape(-1) с указанием порядка элементов.
В текстовых данных представление через матрицу «объект–признак» часто используется для модели bag-of-words. Матрица частот слов n документов × m слов разворачивается в вектор длиной n·m для алгоритмов, которые работают с одномерными входами. Это упрощает интеграцию с библиотеками, такими как scikit-learn, при обучении линейных классификаторов или регрессий.
При работе с временными рядами матрица timestep × признаки разворачивается в вектор, чтобы совместить несколько шагов в единую точку данных. Например, 10 временных шагов с 5 признаками создают вектор длиной 50, который подается на вход модели прогнозирования. Такой подход позволяет использовать стандартные оптимизационные алгоритмы без изменения структуры модели.
Для контроля корректности преобразования рекомендуется визуализировать первые несколько элементов вектора и сопоставить их с исходной матрицей. Это помогает убедиться, что порядок элементов соответствует логике задачи и алгоритм получает правильные признаки.
Вопрос-ответ:
Что означает разворачивание матрицы в вектор и зачем это нужно?
Разворачивание матрицы в вектор — это преобразование двумерного массива данных в одномерный массив. Это требуется, когда алгоритмы или функции работают с плоскими входными данными, а не с матрицами. Например, в линейной регрессии или при обучении нейронных сетей каждый объект должен быть представлен как вектор признаков, чтобы можно было корректно вычислять скалярные произведения и применять операции линейной алгебры.
Как выбрать между построчным и поколоночным разворачиванием матрицы?
Выбор зависит от того, как матрица интерпретируется в задаче. Построчное разворачивание считывает элементы строка за строкой, а поколоночное — столбец за столбцом. В Python и NumPy по умолчанию используется построчный порядок, а в MATLAB и Fortran — поколоночный. Несоблюдение правильного порядка приводит к расхождениям в расчетах и нарушению соответствия элементов с исходной структурой данных.
Какие ошибки чаще всего возникают при преобразовании матрицы в вектор в NumPy?
Наиболее распространённые ошибки связаны с размерностью и порядком элементов. Часто используют ravel() или flatten() без явного указания порядка, что приводит к некорректным векторизованным данным. Ещё одна ошибка — путаница между одномерным массивом (n,) и столбцом (n, 1), что влияет на результаты умножений и конкатенации. Также стоит учитывать, что ravel() может изменять исходную матрицу, если создаётся представление без копирования.
Как правильно преобразовать разреженную матрицу в вектор, чтобы не потерять данные?
Для разреженных матриц прямое преобразование в плотный вектор увеличивает потребление памяти и может замедлить вычисления. Рекомендуется использовать форматы CSR или CSC, извлекать непустые элементы и их индексы, а затем формировать вектор фиксированной длины. Если алгоритм поддерживает разреженные данные, можно хранить только значения и индексы, что сохраняет структуру и уменьшает нагрузку на память.