Содержание статьи

Сравнение строк является одной из базовых операций в программировании, которая используется при проверке идентичности данных, сортировке списков и фильтрации текстовой информации. В языках, таких как Python, Java и C#, операторы == и != позволяют быстро определить равенство или неравенство строк, но важно учитывать, что они чувствительны к регистру символов и пробелам.
Для упорядочивания строк применяется лексикографическое сравнение с операторами <, <=, > и >=. Такие операции сравнивают строки по порядку символов в кодировке, что особенно важно при работе с международными текстами и Unicode. Неправильное использование этих операторов может привести к неожиданным результатам при сортировке или фильтрации.
При работе с пользовательским вводом рекомендуется приводить строки к единому регистру с помощью методов toLowerCase() или toUpperCase(), чтобы исключить ошибки при сравнении. Также важно учитывать пустые строки и строки, содержащие только пробелы, поскольку «» == » « возвращает false в большинстве языков, но может нарушать логику проверки.
Сравнение строк с использованием операторов требует точного понимания поведения языка программирования. Грамотное применение этих операторов помогает избежать логических ошибок, ускоряет отладку кода и упрощает обработку текстовых данных в сложных приложениях.
Использование оператора равенства для проверки идентичности строк
Пример проверки идентичности строк на Python:
| Строка 1 | Строка 2 | Результат сравнения |
|---|---|---|
| «Hello» | «Hello» | true |
| «Hello» | «hello» | false |
| «Test « | «Test» | false |
При работе с пользовательским вводом и внешними данными рекомендуется предварительно очищать строки от пробелов и приводить к единому регистру с помощью методов strip() и lower() в Python или Trim() и ToLower() в C#. Это позволяет избежать ложных отрицательных результатов при сравнении.
Для сложных проверок, включающих многобайтовые символы или Unicode, следует использовать специализированные функции сравнения, которые учитывают нормализацию строк. Это особенно важно при работе с международными данными, где визуально идентичные символы могут иметь разные кодовые представления.
Сравнение строк на неравенство и отрицание

Оператор != используется для проверки того, что две строки не идентичны. Он возвращает true, если хотя бы один символ отличается или если строки имеют разную длину. В языках с объектной моделью, таких как Java или C#, оператор != сравнивает ссылки на объекты, поэтому для точной проверки содержимого следует использовать !string1.equals(string2) или !String.Equals(string1, string2).
Пример проверки неравенства строк на C#:
| Строка 1 | Строка 2 | Результат |
|---|---|---|
| «Data» | «data» | true |
| «Sample» | «Sample» | false |
| «Test « | «Test» | true |
Отрицание строки можно комбинировать с другими условиями для сложных проверок. Например, if (!(userInput == «admin»)) позволяет проверить, что ввод пользователя не совпадает с заданной строкой. Рекомендуется использовать нормализацию и приведение к одному регистру перед сравнением, чтобы исключить ложные срабатывания при наличии пробелов или различий в регистре символов.
Сравнение строк с учётом регистра символов
При сравнении строк с учётом регистра каждый символ учитывается в точном виде, включая заглавные и строчные буквы. В языках программирования, таких как Python, Java и C#, стандартные операторы == и != чувствительны к регистру, поэтому «Hello» == «hello» вернёт false.
Для точного сравнения с учётом регистра рекомендуется использовать встроенные методы, обеспечивающие контроль над регистром. В Python применяются str.casefold() или str.lower() для предварительного приведения строк к единому регистру перед сравнением, если необходима гибкая проверка. В Java применяется equals() для чувствительной к регистру проверки и equalsIgnoreCase() для её игнорирования.
Пример на Python:
| Строка 1 | Строка 2 | Результат с учётом регистра |
|---|---|---|
| «Password» | «password» | false |
| «Admin» | «Admin» | true |
| «Test» | «TEST» | false |
При работе с паролями, ключами и идентификаторами важно сохранять чувствительность к регистру, чтобы избежать ложных совпадений и обеспечить корректную проверку данных. Для пользовательского ввода рекомендуется контролировать и нормализовать регистр заранее, если сравнение должно быть нечувствительным к регистру.
Лексикографическое сравнение строк
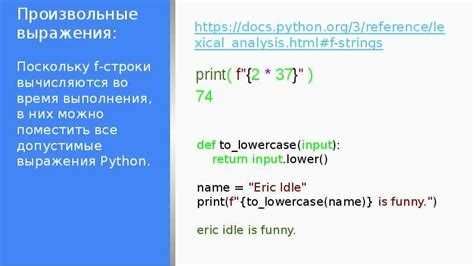
Лексикографическое сравнение оценивает строки по порядку символов в кодировке, аналогично словарной сортировке. В языках программирования операторы <, <=, > и >= сравнивают строки посимвольно и возвращают true или false в зависимости от первого различающегося символа.
В Python и C# строки сравниваются на основе Unicode-кодов символов. Например, «Apple» < «Banana» вернёт true, потому что код символа ‘A’ меньше кода ‘B’. При этом регистр влияет на результат: «apple» < «Banana» также может вернуть false из-за различий между заглавными и строчными буквами.
Пример лексикографического сравнения на Python:
| Строка 1 | Строка 2 | Результат |
|---|---|---|
| «Alpha» | «Beta» | true |
| «gamma» | «Gamma» | false |
| «Data» | «Database» | true |
Для корректной сортировки и фильтрации текстов с разными регистрами рекомендуется использовать предварительное приведение к единому регистру. Это исключает неожиданное поведение при обработке списков строк, содержащих как заглавные, так и строчные символы.
Применение операторов больше и меньше для строк
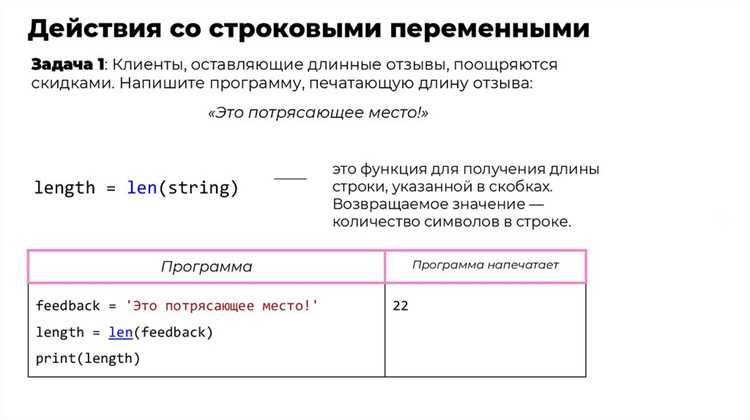
Операторы > и < позволяют сравнивать строки на основе их последовательности символов. В большинстве языков программирования сравнение выполняется по Unicode-кодам символов, что обеспечивает предсказуемую сортировку и фильтрацию текстовых данных.
Пример использования операторов на Python:
| Строка 1 | Строка 2 | Выражение | Результат |
|---|---|---|---|
| «apple» | «banana» | «apple» < «banana» | true |
| «Cherry» | «cherry» | «Cherry» < «cherry» | true |
| «Data» | «Database» | «Data» > «Database» | false |
Важно учитывать регистр: заглавные буквы имеют меньшие коды Unicode, чем строчные, поэтому «A» < «a» вернёт true. Для унифицированного сравнения рекомендуется предварительно привести строки к одному регистру с помощью lower() или upper() в Python, ToLower() или ToUpper() в C#.
Использование операторов больше и меньше позволяет реализовать сортировку, фильтрацию и поиск в текстовых массивах без применения дополнительных функций, при условии правильной нормализации данных и контроля регистра.
Особенности сравнения строк с пробелами и пустыми значениями
При сравнении строк наличие пробелов или пустых значений может привести к неожиданным результатам. Операторы == и != учитывают каждый символ, включая пробелы, поэтому «Test» != «Test « вернёт true, а «» == » « вернёт false.
Рекомендации при работе с такими строками:
- Использовать методы очистки пробелов: strip() в Python, Trim() в C#, чтобы удалить лишние пробелы в начале и конце строки.
- Проверять пустые строки с помощью len() в Python или String.IsNullOrEmpty() в C# для точной идентификации отсутствия текста.
- При сравнении пользовательского ввода приводить строки к единому формату, например, input.strip().lower(), чтобы избежать ложных несоответствий.
- Использовать явное сравнение с пустой строкой вместо предположений: if text == «» или if text != «».
Особое внимание следует уделять массивам и коллекциям строк, где пробелы могут влиять на сортировку и фильтрацию. Нормализация данных перед сравнением помогает избежать логических ошибок и упрощает обработку текстовых данных в программах.
Ошибки при сравнении строк и способы их избежать
Наиболее распространённые ошибки при сравнении строк связаны с регистром символов, пробелами, пустыми значениями и особенностями работы операторов в разных языках программирования. Например, использование == в Java для сравнения строк проверяет ссылки на объекты, а не содержимое, что приводит к ложным результатам.
Типичные ошибки и способы их устранения:
- Сравнение без учёта регистра: «Test» != «test». Решение: применять toLowerCase() или toUpperCase() перед сравнением.
- Наличие лишних пробелов: «Data » != «Data». Решение: использовать strip() в Python или Trim() в C# для удаления пробелов по краям.
- Сравнение с пустыми строками: «» != » «. Решение: явно проверять строки на пустоту с помощью len() или String.IsNullOrEmpty().
- Использование операторов == и != в Java/C# для объектов: решение: применять equals() или String.Equals() для точного сравнения содержимого.
- Лексикографические несоответствия при сортировке: различия в Unicode-кодах заглавных и строчных букв. Решение: нормализовать регистр перед сортировкой и фильтрацией.
Систематическая нормализация строк и правильный выбор методов сравнения позволяют избегать логических ошибок, корректно обрабатывать пользовательский ввод и обеспечивать точную проверку данных в приложениях.
Вопрос-ответ:
Почему при сравнении строк в Java оператор == иногда возвращает false для идентичных значений?
В Java оператор == сравнивает ссылки на объекты, а не их содержимое. Даже если две строки имеют одинаковый текст, они могут быть разными объектами в памяти. Для сравнения текста следует использовать метод equals(), который проверяет посимвольно совпадение символов.
Как правильно сравнивать строки без учёта регистра символов?
Чтобы игнорировать различия между заглавными и строчными буквами, строки можно привести к единому регистру. В Python применяют lower() или casefold(), а в C# — ToLower() или ToUpper(). Например, string1.lower() == string2.lower() вернёт true для «Test» и «test».
Что нужно учитывать при сравнении строк с пробелами и пустыми значениями?
Пробелы в начале и конце строки влияют на результат сравнения. Строки «Data» и «Data » считаются разными. Чтобы избежать ошибок, рекомендуется использовать методы очистки пробелов, например strip() в Python или Trim() в C#. Также следует явно проверять пустые строки с помощью len() или String.IsNullOrEmpty().
Как работают операторы больше и меньше при сравнении строк?
Операторы > и < сравнивают строки по Unicode-кодам символов, оценивая их лексикографически. Например, «Apple» < «Banana» вернёт true, потому что код символа ‘A’ меньше кода ‘B’. Заглавные и строчные буквы имеют разные коды, поэтому «apple» < «Banana» может вернуть false. Для унификации регистра используют приведение всех строк к нижнему или верхнему регистру.
Какие ошибки чаще всего возникают при сравнении строк и как их избежать?
Распространённые ошибки включают:
Почему строки с одинаковым текстом иногда считаются разными в Java и C# при использовании оператора ==?
В Java и C# оператор == для объектов сравнивает ссылки, а не содержимое. Даже если строки выглядят одинаково, они могут находиться в разных участках памяти, поэтому результат сравнения будет false. Для проверки текста используют методы equals() в Java или String.Equals() в C#, которые сравнивают символы внутри строки.
Как правильно сравнивать строки с учётом пробелов и регистра символов?
При сравнении строк пробелы в начале и конце изменяют результат, а регистр символов делает строки различными. Чтобы исключить эти факторы, применяют методы очистки и нормализации: strip() или trim() для удаления пробелов, lower() или upper() для приведения к единому регистру. Например, input.strip().lower() == reference.strip().lower() вернёт true для » Test » и «test». Это помогает точно сравнивать строки при обработке пользовательского ввода и данных из разных источников.