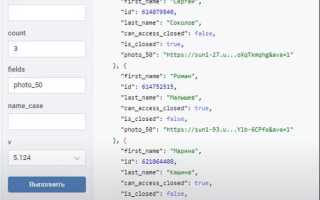
JSON файлы широко применяются для хранения структурированных данных в проектах на Python. Они представляют собой текстовые файлы с форматированием ключ-значение, что позволяет легко обмениваться данными между приложениями и сервисами.
Для работы с JSON в Python используется встроенный модуль json, который позволяет загружать данные из файла, преобразовывать их в словари и списки, а затем вносить изменения. Основной подход заключается в чтении существующего файла, модификации содержимого и сохранении обновлённого JSON обратно на диск.
Добавление новых данных может включать создание новых ключей, обновление значений существующих элементов или добавление объектов в массивы. Важно корректно обрабатывать ошибки чтения и записи, чтобы избежать повреждения файла, особенно при работе с большими объёмами данных.
Практическая рекомендация – всегда использовать режимы открытия файлов с явным указанием кодировки ‘utf-8’ и структурировать данные в виде словарей и списков, что упрощает последующую сериализацию и десериализацию JSON.
Следующие разделы покажут пошаговые примеры добавления и обновления данных в JSON файле, включая обработку исключений и работу с различными структурами данных в Python.
Выбор подходящей библиотеки для работы с JSON

В Python для работы с JSON доступен встроенный модуль json, который обеспечивает функции load, loads, dump и dumps для чтения, записи и преобразования данных между строками и объектами Python. Он подходит для большинства задач и не требует установки дополнительных пакетов.
Для проектов с большими файлами или высокими требованиями к скорости можно использовать библиотеку orjson. Она обеспечивает более быструю сериализацию и десериализацию, поддерживает сохранение объектов в байтовом формате и совместима с типами данных Python, включая datetime.
Если требуется расширенная валидация и работа с более сложными структурами, стоит рассмотреть ujson. Эта библиотека оптимизирована для скорости, поддерживает массивы и вложенные объекты, а также снижает накладные расходы при работе с большими JSON документами.
При выборе библиотеки важно учитывать тип проекта: для стандартных задач достаточно json, для высокой производительности – orjson, а для сложной валидации и обработки больших массивов – ujson. Всегда проверяйте совместимость с текущей версией Python и требования к кодировке, чтобы избежать ошибок при чтении и записи.
Чтение существующего JSON файла в Python
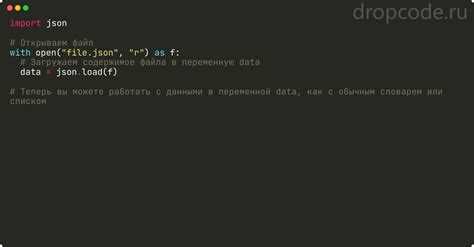
Для работы с JSON в Python используется функция json.load(), которая считывает данные из открытого файла и преобразует их в объекты Python, обычно словари или списки. Файл необходимо открывать в режиме чтения с указанием кодировки ‘utf-8’ для корректной обработки символов.
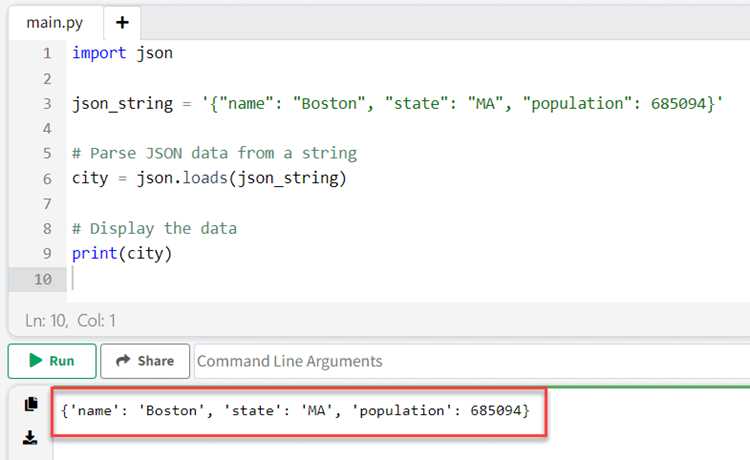
Если данные находятся в строковом формате, применяется json.loads(), позволяющая сразу преобразовать строку в словарь или список. Этот метод удобен при работе с данными из API или текстовых файлов, не требующих прямого сохранения на диск.
При чтении больших JSON файлов рекомендуется использовать конструкцию with open() для автоматического закрытия файла после завершения операций. Это снижает риск утечки ресурсов и обеспечивает стабильность приложения при многократных чтениях.
После успешного чтения данные становятся доступными для модификации, добавления новых элементов или обновления существующих, что является следующим шагом при работе с JSON в Python.
Добавление новых ключей и значений в словарь
Для добавления новых данных в JSON после чтения файла применяется стандартная операция присваивания в словаре Python. Например, data[‘новый_ключ’] = значение создаёт новый элемент или обновляет существующий с тем же именем ключа.
Если требуется добавить несколько пар ключ-значение сразу, можно использовать метод update(), передав ему другой словарь. Это позволяет объединять данные без необходимости добавлять элементы по одному.
Для массивов внутри JSON применяется метод append() при добавлении новых объектов в список. Такой подход полезен для хранения коллекций элементов, например, списка пользователей или записей с временными метками.
Перед добавлением новых ключей рекомендуется проверять наличие ключа с помощью оператора in, чтобы избежать случайного перезаписывания существующих данных. В случае необходимости обновления значения лучше явно обрабатывать логику замены.
При добавлении сложных структур, таких как вложенные словари или списки, важно поддерживать корректное форматирование, чтобы последующая сериализация с помощью json.dump() прошла без ошибок и структура данных сохранялась.
Обновление данных в существующих записях JSON
Для изменения существующих значений в JSON-файле после чтения его в Python используется стандартная работа со словарями и списками. Значение ключа можно обновить через присваивание: data[‘ключ’] = новое_значение.
Если структура данных содержит вложенные словари, доступ к нужному элементу осуществляется по цепочке ключей, например: data[‘пользователи’][0][‘имя’] = ‘Новый_Имя’. Это позволяет точно обновлять отдельные записи без изменения остальных данных.
При работе с массивами объектов часто применяется цикл for для перебора элементов и условная проверка значений ключей перед обновлением. Такой подход обеспечивает контроль над выборкой записей, которые необходимо изменить.
Метод update() также полезен для одновременного обновления нескольких полей словаря. Он заменяет существующие ключи и добавляет новые при необходимости.
Рекомендуется перед внесением изменений создавать резервную копию файла или использовать try-except блоки для отлавливания ошибок типа KeyError и TypeError, что предотвращает потерю данных при некорректных обновлениях.
Сохранение изменений обратно в JSON файл

После внесения изменений в словарь или список Python данные необходимо записать обратно в JSON-файл с помощью функции json.dump(). Файл открывается в режиме записи ‘w’ с кодировкой ‘utf-8’ для корректного сохранения символов.
Для улучшения читаемости JSON можно использовать параметр indent, например json.dump(data, file, indent=4, ensure_ascii=False), который форматирует файл с отступами и сохраняет символы Unicode без экранирования.
При работе с большими файлами рекомендуется сначала сохранять изменения во временный файл, а затем заменять им оригинальный. Это снижает риск повреждения данных при сбое программы во время записи.
Важно закрывать файл после записи, что достигается использованием конструкции with open(). Она гарантирует корректное завершение операции и освобождение ресурсов.
При необходимости регулярного обновления JSON можно организовать функции сохранения, принимающие словарь данных и путь к файлу, что упрощает повторное использование кода в проектах с динамическими данными.
Обработка ошибок при работе с JSON файлами

При работе с JSON в Python возможны различные ошибки, которые важно корректно обрабатывать для предотвращения потери данных и аварийного завершения программы.
- FileNotFoundError – возникает, если указанный путь к файлу неверен. Рекомендуется проверять существование файла с помощью os.path.exists() или оборачивать чтение в try-except блок.
- TypeError – может возникнуть при попытке сериализовать неподдерживаемый тип данных. Для сложных объектов следует преобразовать их в допустимые типы Python или использовать библиотеки, поддерживающие дополнительные типы, например orjson.
- PermissionError – появляется при попытке записи в файл без прав доступа. Проверяйте права на запись и открывайте файл в соответствующем режиме.
Рекомендуется комбинировать try-except с созданием резервных копий файла перед записью. Это позволяет безопасно откатывать изменения при возникновении ошибок и поддерживает целостность данных.
Вопрос-ответ:
Как добавить новый ключ и значение в существующий JSON файл через Python?
Сначала файл открывается в режиме чтения, и данные загружаются в словарь с помощью json.load(). Затем новый ключ добавляется через присваивание, например data[‘новый_ключ’] = значение. После этого файл открывается в режиме записи, и обновленный словарь сохраняется с помощью json.dump().
Можно ли обновлять значения нескольких записей JSON одновременно?
Да, для этого можно использовать метод update() словаря или перебрать элементы массива с помощью цикла for и условной проверки ключей. Такой подход позволяет изменять нужные записи без затрагивания остальных данных.
Какая библиотека в Python быстрее обрабатывает большие JSON файлы?
Стандартный модуль json подходит для большинства задач, но для больших файлов лучше использовать orjson. Она обеспечивает быструю сериализацию и десериализацию, поддерживает объекты Python и сохраняет Unicode без экранирования.
Как защитить данные при записи изменений в JSON файл?
Рекомендуется сначала сохранять изменения во временный файл и проверять корректность данных. Только после успешной записи временный файл заменяет оригинал. Также полезно использовать try-except для отлавливания ошибок типа JSONDecodeError или PermissionError.