Файлы с расширением .pkl представляют собой бинарные объекты, сохранённые с помощью модуля pickle в Python. Их используют для хранения сложных структур данных, включая словари, списки и модели машинного обучения. Открытие такого файла напрямую как текстового приведёт к нечитаемому набору символов.
Для работы с pkl файлами важно проверить корректность пути и существование файла. Ошибки в имени или расположении приведут к FileNotFoundError. Рекомендуется использовать функции os.path.exists или pathlib.Path для предварительной проверки.
Основной метод чтения pkl файлов – использование функции pickle.load(). Она безопасно восстанавливает объекты Python из бинарного файла. При работе с данными из интернета следует учитывать риск загрузки вредоносного кода, поэтому для чужих файлов лучше использовать pickle.load с осторожностью.
Для таблиц и датафреймов удобнее применять pandas.read_pickle(). Этот подход позволяет сразу получить объект DataFrame, готовый для анализа, фильтрации и визуализации без ручного преобразования структур данных.
После загрузки файла важно проверить тип данных и содержимое, используя функции type() и len(). Это помогает убедиться, что данные восстановлены корректно и готовы к дальнейшей обработке или сохранению.
Проверка наличия файла и пути к pkl
Перед открытием pkl файла важно убедиться, что указанный путь существует. Для этого можно использовать модуль os и функцию os.path.exists(‘путь_к_файлу’), которая возвращает True, если файл доступен, и False в противном случае.
Альтернативный способ – использование pathlib.Path. Создайте объект пути Path(‘путь_к_файлу’) и проверьте его методом exists(). Этот подход более современный и удобный при работе с кроссплатформенными путями.
Для предотвращения ошибок рекомендуется также проверять, что путь действительно указывает на файл, а не на директорию. В os используется os.path.isfile(‘путь_к_файлу’), в pathlib – Path(‘путь_к_файлу’).is_file(). Это помогает избежать IsADirectoryError при попытке открыть директорию как pkl.
При работе с относительными путями стоит приводить их к абсолютным с помощью os.path.abspath() или Path.resolve(). Это исключает ошибки при запуске скрипта из разных директорий и гарантирует корректное нахождение файла.
Импорт необходимых модулей для работы с pkl

Для работы с pkl файлами в Python основной модуль – pickle. Его подключение выполняется командой import pickle. Этот модуль позволяет сохранять и загружать любые объекты Python, включая словари, списки и пользовательские классы.
При обработке таблиц и структурированных данных удобно использовать pandas. Подключение выполняется как import pandas as pd. Функция pd.read_pickle(‘путь_к_файлу’) сразу возвращает объект DataFrame, готовый к анализу.
Для работы с путями и проверки существования файлов требуется модуль pathlib. Его подключение: from pathlib import Path. Методы Path.exists() и Path.is_file() обеспечивают точную проверку доступности pkl файлов.
Дополнительно полезен модуль os для совместимости со старыми скриптами и функциями os.path.exists() и os.path.abspath(). Он помогает преобразовывать относительные пути в абсолютные и избегать ошибок при открытии файлов.
Чтение pkl файла с помощью pickle
Для загрузки pkl файла используется функция pickle.load(). Файл необходимо открыть в бинарном режиме чтения с помощью open(‘путь_к_файлу’, ‘rb’). После выполнения pickle.load(file) объект Python будет восстановлен в исходное состояние.
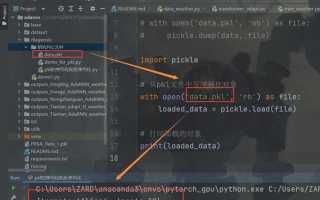
Пример базового кода для чтения pkl файла:
import pickle
with open('data.pkl', 'rb') as file:
data = pickle.load(file)
|
После загрузки рекомендуется проверять тип объекта с помощью type(data). Это помогает определить, с чем работать: словарь, список, набор или пользовательский класс.
При чтении данных из внешних источников следует учитывать риск выполнения вредоносного кода. Для файлов, полученных из ненадёжных источников, безопаснее использовать модуль pickletools или рассматривать альтернативные форматы хранения.
Ошибки при чтении, например EOFError или UnpicklingError, обычно возникают при повреждённом файле или несоответствии версии Python. В таких случаях рекомендуется проверять целостность файла и версию Python, использованную для его создания.
Использование pandas для загрузки pkl файлов с таблицами
Для pkl файлов, содержащих структурированные данные, удобнее всего использовать pandas. Функция pd.read_pickle(‘путь_к_файлу’) автоматически восстанавливает объект DataFrame, позволяя сразу применять фильтры и операции анализа.
Пример чтения pkl файла с таблицей:
- import pandas as pd
- df = pd.read_pickle(‘table.pkl’)
Рекомендации при работе с pandas и pkl:
- Проверять размер и форму таблицы через df.shape.
- Анализировать типы столбцов с помощью df.dtypes для корректного применения функций.
- Использовать df.info() для проверки пропущенных значений и структуры данных.
- При необходимости сохранять изменения обратно через df.to_pickle(‘новый_файл.pkl’).
Такой подход упрощает работу с большими наборами данных и исключает необходимость ручного преобразования вложенных структур Python в таблицы.
Обработка ошибок при открытии pkl файлов

При работе с pkl файлами часто возникают ошибки, связанные с отсутствием файла, повреждением данных или несовпадением версий Python. Для их обработки рекомендуется использовать конструкцию try…except.
Пример обработки основных ошибок:
import pickle
from pathlib import Path
file_path = Path('data.pkl')
try:
with open(file_path, 'rb') as file:
data = pickle.load(file)
except FileNotFoundError:
print(f"Файл {file_path} не найден")
except EOFError:
print(f"Файл {file_path} повреждён или пуст")
except pickle.UnpicklingError:
print(f"Невозможно загрузить объект из {file_path}")
Рекомендации по минимизации ошибок:
- Проверять существование файла через Path.exists() перед открытием.
- Использовать абсолютные пути для избежания конфликтов при запуске скриптов из разных директорий.
- Для файлов из ненадёжных источников избегать автоматической загрузки, чтобы предотвратить выполнение вредоносного кода.
- Создавать резервные копии pkl файлов перед внесением изменений или повторной сериализацией.
Проверка содержимого после загрузки
После загрузки pkl файла важно убедиться, что данные восстановлены корректно и соответствуют ожидаемому типу. Первичная проверка выполняется через функции type() и len(), которые показывают тип объекта и количество элементов.
Для структурированных данных и словарей рекомендуется:
- Проверять значения на наличие None или аномальных типов с помощью isinstance().
- Для списков и множеств – анализировать длину и уникальные элементы через len() и set().
Если pkl содержит DataFrame из pandas:
- Использовать df.head() для визуальной проверки первых строк.
- Анализировать типы столбцов через df.dtypes.
- Проверять пропуски и статистику через df.info() и df.describe().
- Применять фильтры и выборку данных, чтобы убедиться, что структура соответствует ожиданиям.
Такая проверка предотвращает ошибки в последующих операциях и помогает выявить повреждённые или некорректно сериализованные объекты на ранней стадии.
Сохранение изменений обратно в pkl файл

После внесения изменений в объект Python его можно сохранить обратно в pkl файл с помощью pickle.dump(). Файл открывается в бинарном режиме записи: open(‘путь_к_файлу’, ‘wb’). Это перезапишет существующий файл или создаст новый, если его нет.
Пример сохранения объекта:
import pickle
with open('data.pkl', 'wb') as file:
pickle.dump(data, file)
Для объектов pandas можно использовать метод to_pickle(‘путь_к_файлу’), который автоматически сериализует DataFrame:
import pandas as pd
df.to_pickle('table.pkl')
Рекомендации:
- Создавать резервную копию исходного файла перед перезаписью, чтобы избежать потери данных.
- Использовать бинарный режим записи ‘wb’ и закрывать файл через контекстный менеджер with, чтобы исключить повреждение данных.
- Проверять доступность директории и права на запись, чтобы избежать PermissionError.
- После сохранения проверять размер файла и корректность загрузки через pickle.load() или pd.read_pickle().
Вопрос-ответ:
Что такое pkl файл и для чего он используется в Python?
Файл с расширением .pkl — это бинарный объект, созданный с помощью модуля pickle. Он используется для сохранения любых объектов Python, включая списки, словари, множества и пользовательские классы. Такой файл позволяет восстановить структуру данных и значения без ручного преобразования, что удобно для хранения моделей, конфигураций и промежуточных результатов вычислений.
Как правильно открыть pkl файл и проверить, что он существует?
Перед открытием файла рекомендуется проверить его наличие. В стандартном Python можно использовать os.path.exists(‘путь_к_файлу’), а современный способ — Path(‘путь_к_файлу’).exists() из модуля pathlib. После этого файл открывают в бинарном режиме чтения ‘rb’ через open(). Такая проверка помогает избежать ошибок FileNotFoundError.
Какая разница между использованием pickle и pandas для загрузки pkl файлов?
Модуль pickle позволяет восстановить любой объект Python, включая сложные структуры. Он универсален, но требует ручной проверки типов и структуры данных после загрузки. pandas удобно использовать для таблиц и датафреймов, так как pd.read_pickle() сразу возвращает DataFrame, готовый к фильтрации и анализу. Выбор метода зависит от типа содержимого файла.
Какие ошибки могут возникнуть при чтении pkl файла и как их обработать?
Основные ошибки: FileNotFoundError — файл не найден; EOFError — файл пуст или повреждён; UnpicklingError — данные не соответствуют ожидаемому формату. Для обработки используют конструкцию try…except. Рекомендуется проверять путь к файлу, создавать резервные копии и ограничивать загрузку данных из ненадёжных источников.
Как сохранить изменения обратно в pkl файл и проверить корректность сохранения?
Изменённый объект можно сохранить с помощью pickle.dump(data, file) в бинарном режиме ‘wb’ или для DataFrame через df.to_pickle(‘путь_к_файлу’). После записи рекомендуется проверять размер файла и повторно загружать его через pickle.load() или pd.read_pickle(), чтобы убедиться, что данные восстановились корректно. Также полезно создавать резервные копии перед перезаписью.
Как правильно открыть pkl файл, чтобы не потерять данные?
Для открытия pkl файла нужно использовать модуль pickle и открывать файл в бинарном режиме чтения: open(‘путь_к_файлу’, ‘rb’). После этого объект восстанавливается с помощью pickle.load(file). Перед открытием важно проверить существование файла через Path(‘путь_к_файлу’).exists() или os.path.exists(), чтобы избежать ошибок FileNotFoundError. Для проверки содержимого применяют функции type() и len(), чтобы убедиться, что структура данных соответствует ожиданиям.
Можно ли редактировать данные в pkl файле и как сохранить изменения?
Да, данные можно изменить после загрузки. Внесённый объект сохраняют обратно с помощью pickle.dump(data, file), открыв файл в бинарном режиме записи ‘wb’. Для pandas DataFrame применяется df.to_pickle(‘путь_к_файлу’). После сохранения рекомендуется проверять корректность записи, повторно загрузив файл через pickle.load() или pd.read_pickle(). Перед перезаписью лучше создавать резервную копию, чтобы избежать потери информации при ошибках записи.