Содержание статьи

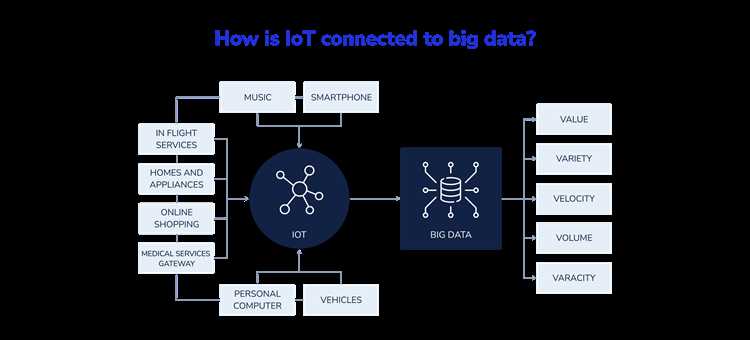
Интернет вещей формирует непрерывный поток данных от физических объектов: датчиков температуры, счетчиков электроэнергии, GPS-модулей, камер, промышленных контроллеров. Каждый такой источник передает измерения с заданной частотой – от раз в час до десятков тысяч событий в секунду. Без системной работы с этими массивами данные быстро теряют практический смысл и превращаются в неконтролируемый архив телеметрии.
Big Data в контексте IoT – это не абстрактный термин, а совокупность конкретных задач: прием событий в реальном времени, фильтрация шума, агрегация показателей, хранение исторических значений и последующий анализ. На практике применяются очереди сообщений, распределенные хранилища, колоночные базы данных и потоковая обработка, позволяющие работать с миллиардами записей без потери целостности данных.
Связка IoT и Big Data используется там, где требуется контроль процессов на основе фактических показателей. В промышленности это мониторинг оборудования и прогноз отказов, в энергетике – анализ потребления по временным интервалам, в логистике – отслеживание маршрутов и простоев транспорта. Для получения прикладного результата рекомендуется заранее определить перечень метрик, допустимую задержку обработки и правила хранения данных, чтобы архитектура системы соответствовала реальным сценариям эксплуатации.
При проектировании решений стоит учитывать объем трафика, требования к отказоустойчивости и правовые ограничения на работу с данными. Четкое разграничение задач сбора, хранения и анализа позволяет снизить нагрузку на инфраструктуру и упростить масштабирование. Без этого IoT-проект рискует остаться набором датчиков без управляемой аналитической части.
Что понимается под IoT и какие типы устройств входят в эту категорию
Базовую группу IoT-устройств составляют датчики, регистрирующие конкретные показатели: температуру, влажность, давление, вибрацию, уровень освещенности, концентрацию газов. В промышленности используются датчики тока, износа подшипников, оборотов валов. В городских системах – счетчики воды, газа и электроэнергии с удаленной передачей показаний.
Отдельную категорию образуют исполнительные устройства, которые не только передают данные, но и выполняют команды: реле, клапаны, приводы, умные розетки, системы управления освещением и климатом. Такие устройства получают управляющие сигналы на основе анализа поступающих данных и позволяют замыкать цикл «измерение – решение – действие».
К IoT также относятся встраиваемые контроллеры и шлюзы, объединяющие данные от нескольких источников. Они применяются для предварительной фильтрации, агрегации и преобразования данных перед отправкой в централизованные хранилища. Использование шлюзов снижает объем передаваемого трафика и упрощает интеграцию с платформами Big Data.
При выборе типа IoT-устройств рекомендуется учитывать частоту измерений, допустимую задержку передачи, условия эксплуатации и способы подключения (Wi-Fi, Ethernet, LPWAN, сотовые сети). Неправильный выбор класса устройств приводит к избыточному потоку данных или, наоборот, к нехватке информации для аналитических задач.
Как формируются потоки данных от IoT устройств и какие параметры в них содержатся

Потоки данных от IoT-устройств формируются как последовательность событий, передаваемых по расписанию, при изменении показателей или по запросу. Частота отправки задается на уровне прошивки и зависит от сценария использования: счетчики ресурсов фиксируют значения раз в 15–60 минут, промышленные датчики вибрации – десятки и сотни раз в секунду, трекеры транспорта – при смене координат или скорости.
Каждое сообщение от устройства имеет структурированный формат и включает не только измеренное значение, но и служебные поля, необходимые для обработки и последующего анализа. Типовой состав передаваемых данных можно представить в виде набора параметров.
- Идентификатор устройства – уникальный код датчика или контроллера, используемый для привязки данных к объекту учета.
- Метка времени – фиксирует момент измерения, а не момент передачи, что позволяет корректно выстраивать временные ряды.
- Измеряемые показатели – числовые или категориальные значения: температура, давление, уровень заряда, координаты, состояние реле.
- Единицы измерения – градусы, вольты, проценты, метры, что упрощает агрегацию данных из разных источников.
- Техническое состояние – данные о качестве сигнала, уровне батареи, ошибках сенсора.
Для снижения нагрузки на сеть и хранилища часто применяется предварительная обработка данных. На стороне устройства или шлюза выполняются операции агрегации, округления или отсечения значений, выходящих за заданные диапазоны. Такой подход особенно актуален для систем с тысячами источников телеметрии.
При проектировании потоков данных рекомендуется заранее определить, какие параметры действительно нужны для анализа, а какие можно исключить. Избыточная детализация увеличивает объем хранимых данных и усложняет обработку, тогда как недостаточный набор показателей ограничивает возможности аналитики и прогнозирования.
Что относится к Big Data при работе с данными интернета вещей
Big Data в IoT включает огромные объемы разнообразных данных, генерируемых тысячами устройств в режиме непрерывной передачи. Это многомерные временные ряды, поступающие с разной частотой – от миллисекунд до минут, что требует масштабируемых систем хранения и обработки.
Основные компоненты Big Data в IoT:
- Потоковые данные – события, поступающие в реальном времени, такие как телеметрия датчиков, сигналы состояния оборудования, координаты перемещения.
- Исторические записи – накопленные временные ряды для анализа трендов и прогнозирования с сохранением данных на месяцы и годы.
- Разнородные форматы – числовые показатели, текстовые логи, бинарные файлы и мультимедиа, собранные с различных типов устройств.
- Метаданные – идентификаторы устройств, характеристики моделей, данные о местоположении и настройках.
Для управления такими данными применяются распределённые базы и системы потоковой обработки (например, Apache Kafka, Hadoop, Apache Flink), обеспечивающие параллельную загрузку, фильтрацию и агрегацию.
Рекомендуется внедрять многоуровневую архитектуру хранения: первичные, детализированные данные удерживать ограниченное время, а агрегированные показатели – дольше для аналитики. Это снижает требования к ресурсам и ускоряет получение результатов.
Качество Big Data определяется точностью временных меток, полнотой записей и согласованностью форматов. Несоблюдение этих параметров ведёт к снижению надёжности анализа и ошибкам в прогнозах.
Как происходит сбор, хранение и обработка данных IoT на практике
Сбор данных начинается с подключения IoT-устройств к сети с помощью протоколов MQTT, CoAP, HTTP или через специализированные шлюзы. Устройства отправляют сообщения на серверы или облачные платформы, где происходит первичная проверка и фильтрация данных для исключения некорректных значений.
Для хранения данных применяются распределённые базы, ориентированные на работу с временными рядами (InfluxDB, TimescaleDB) и масштабируемые хранилища (Hadoop, Amazon S3). Архитектура разделяет горячие данные, доступные для мгновенного анализа, и холодные – архивные записи с длительным сроком хранения.
Обработка данных реализуется в несколько этапов:
- Потоковая обработка – фильтрация, агрегация, детекция аномалий в реальном времени с помощью инструментов Apache Kafka, Apache Flink, Spark Streaming.
- Пакетная обработка – периодический анализ больших объемов для построения моделей, прогнозов и генерации отчетов.
- Визуализация и интеграция – передача обработанных данных в BI-системы, дашборды и внешние сервисы для принятия решений.
Рекомендуется проектировать систему с учетом масштабируемости и отказоустойчивости: использовать балансировщики нагрузки, резервные узлы, и автоматическое переключение при сбоях. Это минимизирует потери данных и позволяет сохранять непрерывность мониторинга.
Для обеспечения качества аналитики важна синхронизация временных меток, унификация форматов сообщений и регулярная проверка целостности данных. Без этого корректный анализ и построение моделей становятся невозможными.
Применение IoT и Big Data в промышленности и производственных системах

В промышленности IoT используется для мониторинга состояния оборудования в режиме реального времени с помощью вибрационных датчиков, термодатчиков, датчиков давления и тока. Анализ поступающих данных позволяет прогнозировать износ узлов и предотвращать аварии за счет планового обслуживания.
Big Data обрабатывает большие объемы телеметрии с производственных линий, выявляя закономерности в работе станков и автоматизируя контроль качества продукции. Системы распознают отклонения от нормы и формируют отчеты для оптимизации технологических процессов.
Сбор данных с нескольких объектов осуществляется через промышленные шлюзы и протоколы OPC UA, Modbus и MQTT. Для хранения используются распределённые хранилища, способные выдерживать интенсивные потоки информации с минимальной задержкой.
Реализация цифровых двойников – виртуальных моделей оборудования – базируется на данных IoT и Big Data. Это позволяет проводить испытания в виртуальной среде и оптимизировать режимы работы без риска простоев и повреждений.
Внедрение IoT и Big Data требует стандартизации данных и интеграции с существующими ERP и MES системами, что повышает прозрачность производственных процессов и ускоряет принятие управленческих решений.
Использование IoT и Big Data в городских сервисах, транспорте и быту

В городских сервисах IoT применяют для мониторинга инфраструктуры: уличного освещения, систем водоснабжения, утилизации отходов. Датчики фиксируют расход ресурсов, состояние коммуникаций и уровень заполненности контейнеров, данные передаются в аналитические платформы для оптимизации работы служб.
В транспорте сенсоры отслеживают положение и скорость транспортных средств, состояние дорожного полотна и пробки в реальном времени. Анализ больших данных позволяет корректировать маршруты, снижать время ожидания и повышать безопасность на дорогах.
| Сфера | Типы устройств | Основные параметры | Применение |
|---|---|---|---|
| Городские сервисы | Датчики воды, газа, мусорные контейнеры с уровнями заполнения | Объем потребления, заполненность, давление в трубах | Оптимизация графиков обслуживания, снижение потерь ресурсов |
| Транспорт | GPS-трекеры, датчики скорости, системы контроля топлива | Координаты, скорость, расход топлива, пробег | Оптимизация маршрутов, предотвращение аварий, снижение затрат |
| Быт | Умные счетчики, термостаты, системы безопасности | Потребление электроэнергии, температура, движение | Автоматизация управления, сокращение расходов, повышение комфорта |
В бытовых условиях IoT и Big Data обеспечивают контроль энергопотребления и автоматизацию систем отопления и безопасности. Анализ данных помогает выявлять неэффективные режимы работы и предлагать корректировки для экономии ресурсов и улучшения удобства.
Вопрос-ответ:
Что включает в себя термин «Интернет вещей» и как отличить IoT-устройства от обычных гаджетов?
Интернет вещей — это сеть физических объектов, оснащенных датчиками и средствами связи для автоматической передачи данных. В отличие от обычных гаджетов, IoT-устройства работают автономно, собирают информацию о состоянии окружающей среды или оборудования и передают её в централизованные системы без постоянного участия человека.
Какие особенности потоков данных создают сложности при их обработке в IoT-проектах?
Потоки данных IoT характеризуются высокой частотой поступления, разнообразием форматов и большим объемом. Часто данные идут в реальном времени и требуют быстрой фильтрации и агрегации. Это создает необходимость использования распределённых систем и специальных протоколов для сохранения целостности и своевременной обработки информации.
Какие практические задачи решаются с помощью анализа больших данных, получаемых от IoT?
Анализ больших данных IoT помогает прогнозировать поломки оборудования, оптимизировать потребление ресурсов, повышать безопасность на объектах и в транспорте. Также используется для контроля качества продукции, управления логистикой и улучшения работы городских служб через мониторинг инфраструктуры.
Какие требования предъявляются к хранению данных IoT, чтобы обеспечить их доступность и качество анализа?
Хранение должно разделять данные на краткосрочные и долговременные хранилища, поддерживать масштабирование при увеличении объема информации, обеспечивать целостность и точность временных меток. Также важно применять методы сжатия и агрегации, чтобы снизить нагрузку на системы и ускорить доступ к ключевым показателям.