Содержание статьи

При работе со списками в Python часто возникает задача определить, какие значения встречаются более одного раза. Это может быть проверка входных данных, анализ логов, очистка пользовательского ввода или поиск ошибок в результатах вычислений. Неправильный выбор подхода приводит либо к лишним проходам по списку, либо к потере порядка элементов, что критично во многих сценариях.
Отдельного внимания требуют случаи, когда нужно вывести только те элементы, которые повторяются, но без повторов в самом результате, либо сохранить порядок первого появления. Также на практике часто встречаются списки строк, где важно учитывать или игнорировать регистр, и вложенные структуры, требующие предварительного разворачивания данных.
Поиск повторяющихся значений с помощью множества set
Множество set позволяет быстро определить, какие элементы списка встречаются более одного раза. Принцип основан на том, что множество хранит только уникальные значения, автоматически отбрасывая повторы. Это делает его удобным инструментом для первичной фильтрации данных.
Базовый подход строится на сравнении длины исходного списка и множества, созданного из него. Если размеры отличаются, значит в списке присутствуют повторы. Однако для получения самих повторяющихся значений требуется дополнительная логика.
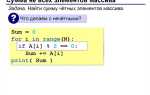
Один из распространённых вариантов – последовательный обход списка с проверкой наличия элемента в уже просмотренном множестве:
- создаётся пустое множество для уникальных значений;
- создаётся второе множество для найденных повторов;
- каждый элемент списка проверяется на наличие в первом множестве;
- при повторном обнаружении элемент добавляется во второе множество.
Такой способ возвращает только те значения, которые встретились минимум два раза, без дублирования в результате. Это удобно, когда нужен компактный список повторов, а порядок элементов не имеет значения.
Важно учитывать ограничения метода:
- элементы списка должны быть хешируемыми (числа, строки, кортежи);
- порядок исходного списка при использовании set не сохраняется;
- для вложенных списков требуется предварительное преобразование данных.
Использование множества оправдано в задачах быстрой проверки и получения набора повторяющихся значений, когда структура данных простая и не требуется учитывать последовательность элементов.
Определение дубликатов через подсчёт элементов в collections.Counter
Класс collections.Counter предназначен для подсчёта количества вхождений элементов в итерируемой последовательности. При передаче списка он формирует словарь, где ключом выступает элемент списка, а значением – число его появлений. Это даёт прямой доступ к информации о повторах без ручного обхода данных.
После создания объекта Counter дубликаты определяются простым условием: значение счётчика больше единицы. Такой подход удобен, когда нужно не только вывести повторяющиеся элементы, но и знать, сколько раз каждый из них встречается в списке.
Метод подходит для задач анализа данных, где требуется фильтрация по количеству вхождений. Например, можно получить все элементы, появившиеся более двух раз, или исключить значения, встретившиеся однократно.
При использовании Counter важно учитывать несколько моментов. Во-первых, элементы списка должны поддерживать хеширование. Во-вторых, порядок элементов в результирующей структуре зависит от версии Python: в современных версиях сохраняется порядок первого появления, но полагаться на это поведение в старом коде не стоит.
Этот способ оправдан в ситуациях, где требуется точный контроль над количеством повторов и дальнейшая обработка результатов, например сортировка по числу вхождений или объединение данных из нескольких списков.
Во многих задачах важен не только факт наличия повторов, но и их расположение в списке. Использование set или стандартных словарей без дополнительной логики приводит к потере исходной последовательности, поэтому требуется иной подход.
Важно заранее определить критерии отбора. Иногда требуется вывести все повторные появления элемента, а не только первое. В этом случае логика проверки меняется: в результат добавляется каждый элемент, который уже присутствует в наборе просмотренных значений.
Подход с сохранением порядка подходит для линейной обработки данных и хорошо сочетается с последующей фильтрацией или форматированием результата, особенно когда порядок элементов несёт смысловую нагрузку.
Получение списка дубликатов без повторов в результате
На практике применяются два устойчивых подхода. Первый основан на подсчёте вхождений элементов с последующей фильтрацией по количеству появлений. Второй использует проверку повторного обнаружения элемента при последовательном обходе списка с накоплением найденных дубликатов в отдельной структуре.
При использовании подсчёта удобно сразу задать критерий отбора, например выбрать только те значения, которые встречаются два и более раз. Такой способ подходит для аналитических задач, где важен сам факт повтора, а не позиция элемента в списке.
Выбор подхода зависит от требований к порядку и дальнейшему использованию результата. Если список дубликатов используется для сравнения, фильтрации или отчёта, отсутствие повторов в нём упрощает логику последующих операций.
Работа с повторяющимися элементами во вложенных списках

Вложенные списки усложняют поиск повторов, так как элементы могут находиться на разных уровнях структуры. Прямое применение set или collections.Counter невозможно без предварительного приведения данных к плоскому виду. Первый шаг – определить глубину вложенности и формат элементов, с которыми предстоит работать.
На практике чаще всего используют разворачивание структуры в один список. Это делается либо последовательным обходом с проверкой типа элемента, либо рекурсивной обработкой, если глубина заранее неизвестна. После разворачивания применяются стандартные приёмы поиска дубликатов, как и для обычного списка.
Если вложенные списки содержат сложные объекты, например списки внутри списков или словари, требуется дополнительное преобразование. Нехешируемые элементы приводят к кортежам или строковому представлению, чтобы обеспечить корректное сравнение значений.
В задачах, где важен контекст появления повтора, имеет смысл сохранять информацию об уровне вложенности или исходной позиции элемента. Для этого вместе со значением фиксируется путь до него, например индекс внешнего и внутреннего списка.
Обработка повторов в списке строк с учётом регистра

Списки строк требуют особого подхода к определению повторов, так как регистр символов влияет на сравнение. Например, строки «Python» и «python» будут восприниматься как разные значения при стандартной проверке. В зависимости от задачи можно учитывать регистр или приводить все строки к единому виду.
Для игнорирования регистра применяют метод str.lower() или str.upper() при добавлении элементов в множество или при подсчёте с помощью collections.Counter. Такой подход позволяет корректно выявить повторы, которые отличаются только регистром символов.
Если регистр важен, сравнение выполняется напрямую без преобразования. При этом повторы фиксируются только для полностью идентичных строк, что полезно для логов, тегов или имён, где каждая вариация несёт смысл.
Рекомендуется хранить исходное значение строки в результате, а преобразованную для проверки – во вспомогательной структуре. Это сохраняет точность данных при одновременном контроле повторов с учётом или без учёта регистра.
Такой метод упрощает фильтрацию, отчёты и последующую обработку строк, позволяя точно контролировать, какие элементы считать повторяющимися в конкретном контексте.
Вопрос-ответ:
Как с помощью Python определить, какие элементы списка повторяются?
Для поиска повторяющихся элементов можно использовать множество set или класс collections.Counter. При использовании множества создают пустое множество для уникальных элементов и второе для найденных повторов. Каждый элемент проверяют: если он уже в первом множестве, добавляют во второе. С Counter создаётся словарь с подсчётом вхождений, после чего выбирают элементы с количеством больше одного.
Можно ли сохранить порядок элементов при выводе повторов?
Да. Для сохранения порядка применяют обход списка с двумя множествами: одно хранит уже встреченные элементы, другое — элементы, добавленные в результат. Элемент добавляется в результат только при первом повторе, что сохраняет исходную последовательность без повторов.
Как обрабатывать повторяющиеся строки с разным регистром?
Если регистр не важен, перед проверкой все строки приводят к единому виду с помощью str.lower() или str.upper(). Это позволяет корректно определить повторы вроде «Python» и «python». При необходимости учитывать регистр сравнение выполняют напрямую, и только полностью идентичные строки будут считаться дубликатами.
Что делать, если список содержит вложенные списки?
Сначала вложенные списки разворачивают в один плоский список. Это можно сделать рекурсивно или с использованием генераторов. После разворачивания применяют обычные методы поиска повторов. Если нужно сохранить контекст, можно хранить путь до элемента, например индексы внешнего и внутреннего списка.
Как получить список повторяющихся элементов без дублирования в результате?
Используют либо подсчёт с Counter, выбирая элементы с количеством больше одного, либо обход списка с накоплением найденных повторов в отдельный список. Элемент добавляется в результат только при первом повторе. Такой подход формирует список уникальных повторяющихся значений без лишних повторов.
Как быстро найти повторяющиеся элементы в списке чисел в Python?
Можно использовать множество set для отслеживания уникальных элементов. Создаём пустое множество для уникальных значений и второе для повторов. Проходим по списку: если элемент уже есть в первом множестве, добавляем его во второе. В результате второе множество содержит только повторяющиеся значения без дубликатов.
Можно ли вывести повторяющиеся строки в списке, сохранив их исходный порядок?
Да. Для этого создают два множества: одно хранит все встреченные элементы, другое — элементы, уже добавленные в результат. При обходе списка каждый элемент проверяют: если он уже встречался и ещё не добавлен в результат, включают в итоговый список. Такой метод сохраняет порядок появления повторов и исключает лишние дубликаты.