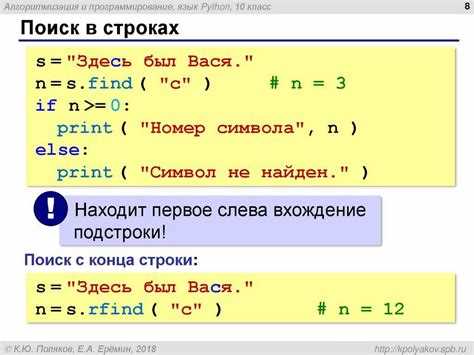
В Python разбиение строки на отдельные слова является частой задачей при обработке текстовых данных. Основной инструмент для этого – метод split(), который позволяет разделять строку по заданному символу или пробелу по умолчанию. Например, вызов text.split() создаст список слов, автоматически игнорируя последовательные пробелы.
Для более сложных случаев, когда строки содержат запятые, точки или другие разделители, стандартного split() может быть недостаточно. В таких ситуациях удобнее использовать модуль re и функцию re.split(), позволяющую задавать несколько символов-разделителей одновременно и исключать пустые элементы.
При работе с текстом важно учитывать регистр и наличие лишних пробелов. Методы strip() и lower() помогают очищать слова и приводить их к единому виду для дальнейшей обработки, например, при анализе частоты встречаемости слов или подготовке текста к машинному обучению.
Кроме того, иногда требуется сохранять знаки препинания или разделять строку по определённым шаблонам, что также решается с помощью регулярных выражений. Правильный выбор метода разбиения строки зависит от структуры текста и целей обработки данных.
Использование метода split для простых строк
Метод split() разделяет строку на части по заданному разделителю и возвращает их в виде списка. Если разделитель не указан, используется пробел. Например, text = «Python изучение строк» и words = text.split() создадут список [‘Python’, ‘изучение’, ‘строк’].
Метод split() корректно обрабатывает последовательные пробелы: лишние пробелы игнорируются и не создают пустых элементов в списке. В случае необходимости разделения по конкретному символу, например запятой, можно использовать text.split(‘,’), что вернёт список слов, отделённых этим символом.
Для строк с потенциальными пробелами в начале или конце рекомендуется применять strip() перед разбиением: text.strip().split(). Это предотвращает появление пустых элементов в начале или конце списка. Такой подход подходит для быстрого получения слов из простого текста без сложной обработки знаков препинания.
Разделение строки по нескольким символам-разделителям
Для случаев, когда строка содержит разные разделители, стандартный метод split() недостаточен. Удобное решение – использование модуля re и функции re.split(). Она позволяет задавать несколько символов-разделителей через регулярное выражение. Например, re.split(r'[ ,;]’, text) разделит строку по пробелам, запятым и точкам с запятой одновременно.
При применении re.split() важно учитывать возможность появления пустых элементов, если разделители идут подряд. Для их удаления можно использовать генератор списков: [word for word in re.split(r'[ ,;]’, text) if word]. Это создаст чистый список слов без пустых строк.
Регулярные выражения также позволяют исключать специфические символы, например точки, скобки или кавычки, при разделении. Такой подход подходит для подготовки текста к анализу и обработке данных, когда структура строки включает разнообразные разделители.
Применение регулярных выражений для сложных случаев
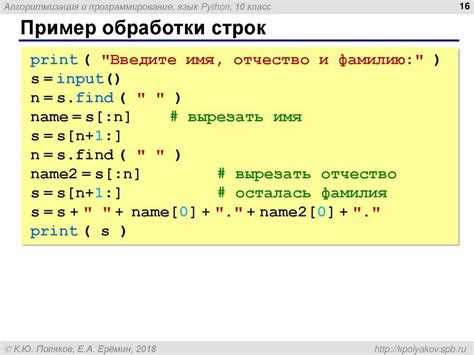
Регулярные выражения позволяют разделять строки в ситуациях, когда используются нестандартные или смешанные разделители, а также когда нужно учитывать или исключать определённые символы. Для этого применяется функция re.split() из модуля re.
Примеры применения:
- Разделение по пробелам, запятым, точкам с запятой и тире: re.split(r'[ ,;–]’, text).
- Удаление пустых элементов при последовательных разделителях: [word for word in re.split(r'[ ,;–]’, text) if word].
- Сохранение определённых символов, например апострофов в сокращениях: re.split(r»[ ,;–]+(?.
Регулярные выражения также позволяют:
- Игнорировать регистр при разделении: re.split(r'[ ,;]’, text, flags=re.IGNORECASE).
- Ограничивать количество разбиений, например, только на первые три слова: re.split(r’\s+’, text, maxsplit=3).
- Комбинировать с strip() для очистки полученных слов от пробелов и переносов строк.
Использование регулярных выражений обеспечивает гибкость при обработке текстов с разнородными форматами и сложными структурами, что особенно важно при подготовке данных для анализа или парсинга документов.
Игнорирование лишних пробелов и пустых элементов
При разбиении строк на слова часто возникают пустые элементы из-за лишних пробелов в начале, конце или между словами. Для их устранения рекомендуется использовать комбинацию методов strip() и split(): text.strip().split(). Это удаляет пробелы по краям и создаёт список только с реальными словами.
Если строка разбивается с помощью регулярных выражений, пустые элементы могут появляться при последовательных разделителях. Для их удаления применяется генератор списков: [word for word in re.split(r'[ ,;]’, text) if word]. Такой подход исключает пустые строки без дополнительной обработки.
Для динамических или многопользовательских данных рекомендуется всегда применять очистку слов после разбиения: [word.strip() for word in words]. Это позволяет избежать ошибок при дальнейшей обработке, например подсчёте частоты слов или формировании словарей.
Разбиение строк с сохранением пунктуации

Иногда необходимо сохранить знаки препинания при разбиении строки на слова. В таких случаях стандартный split() не подходит, так как он удаляет все разделители. Для решения используется модуль re с функцией re.findall(), которая позволяет извлекать слова и знаки препинания отдельно. Пример: re.findall(r»\w+|[.,!?;]», text) создаст список слов и пунктуации.
Такой подход полезен при анализе текста, когда важны контекстные связи между словами и знаками препинания. Можно комбинировать с lower() для унификации регистра слов, оставляя пунктуацию без изменений: [token.lower() if token.isalpha() else token for token in tokens].
Для сложных случаев с сокращениями или апострофами применяются более точные регулярные выражения: re.findall(r»[A-Za-z0-9′]+|[.,!?;]», text). Это позволяет корректно разбивать текст, не теряя важных символов внутри слов.
Преобразование строки в список слов с учётом регистра
При разбиении строки на слова важно учитывать регистр, если анализ текста требует различения заглавных и строчных букв. Метод split() сохраняет исходный регистр, но для унификации можно использовать lower() или upper() для всех элементов списка.
Пример преобразования строки в список с учётом регистра:
| Строка | Разделение | Результат |
|---|---|---|
| «Python изучение Python» | text.split() | [‘Python’, ‘изучение’, ‘Python’] |
| «Python изучение Python» | [word.lower() for word in text.split()] | [‘python’, ‘изучение’, ‘python’] |
| «Python изучение Python» | [word.upper() for word in text.split()] | [‘PYTHON’, ‘ИЗУЧЕНИЕ’, ‘PYTHON’] |
При использовании регулярных выражений также можно применять lower() к результату re.findall() для единообразного представления слов, сохраняя при этом структуру исходного текста и разделители при необходимости.
Вопрос-ответ:
Как в Python разделить строку на слова по пробелам?
Для простых случаев используется метод split() без аргументов: words = text.split(). Он автоматически разделяет строку по пробелам и игнорирует лишние пробелы между словами, создавая список только с реальными словами.
Можно ли разделять строки по нескольким символам одновременно?
Да, для этого используется модуль re и функция re.split(). Например, re.split(r'[ ,;]’, text) разделит строку по пробелам, запятым и точкам с запятой одновременно. Чтобы удалить пустые элементы, возникающие при последовательных разделителях, используется генератор списков: [word for word in re.split(r'[ ,;]’, text) if word].
Как сохранять пунктуацию при разбиении строки на слова?
Для сохранения знаков препинания применяют re.findall() с регулярным выражением, которое выделяет слова и символы: re.findall(r»\w+|[.,!?;]», text). Это создаёт список, где отдельно присутствуют слова и знаки препинания, что полезно при анализе контекста текста.
Как убрать пустые строки после разбиения с помощью регулярных выражений?
После разбиения по нескольким разделителям могут появляться пустые строки. Их удаляют с помощью генератора списков: [word for word in re.split(r'[ ,;]’, text) if word]. Это создаёт чистый список слов, готовый к дальнейшей обработке без лишних элементов.
Как учесть регистр слов при разбиении строки?
Метод split() сохраняет исходный регистр. Для унификации можно применять lower() или upper() к каждому слову: [word.lower() for word in text.split()]. Это помогает при подсчёте частоты слов или создании словарей, когда нужно рассматривать слова одинаково, независимо от регистра.
Как разделить строку на слова, если в тексте встречаются разные разделители и лишние пробелы?
Для строк с несколькими разделителями, например пробелами, запятыми и точками с запятой, используют модуль re и функцию re.split(). Пример: re.split(r'[ ,;]’, text) разделит строку по пробелам, запятым и точкам с запятой. Чтобы исключить пустые элементы, возникающие при последовательных разделителях или лишних пробелах, применяют генератор списков: [word for word in re.split(r'[ ,;]’, text) if word]. Для приведения слов к единому виду можно использовать lower() или upper(), например: [word.lower() for word in re.split(r'[ ,;]’, text) if word]. Такой подход позволяет получить чистый список слов, пригодный для анализа текста или дальнейшей обработки.