Содержание статьи

Механизм Copy on Write (COW) позволяет создавать копии объектов в памяти без немедленного дублирования данных. Первоначально все копии ссылаются на один и тот же участок памяти, а фактическое копирование выполняется только при попытке модифицировать объект. Такой подход снижает потребление оперативной памяти при работе с большими структурами данных, особенно когда большинство копий остаются неизменными.
В языках программирования, таких как C++ и Python, COW активно применяется для оптимизации строк, массивов и контейнеров. Например, стандартная реализация строк в C++ использует внутренние счетчики ссылок, чтобы отслеживать количество копий, и создает отдельную копию только при изменении содержимого. Это уменьшает накладные расходы на операции копирования при передаче объектов в функции или возврате из них.
В многопоточных приложениях COW обеспечивает дополнительное преимущество: неизменяемые объекты могут безопасно использоваться разными потоками без синхронизации. При этом создание новых версий данных при записи выполняется локально в памяти потока, что минимизирует блокировки и повышает производительность.
Использование COW в операционных системах и файловых системах позволяет оптимизировать работу с виртуальной памятью и снапшотами. Например, при клонировании процессов с помощью fork() в Unix-подобных системах память копируется только при изменении страниц, что значительно ускоряет создание новых процессов и экономит ресурсы.
Для внедрения COW в прикладных проектах важно отслеживать области, где объекты часто изменяются. В таких случаях накладные расходы на копирование могут превышать экономию памяти. Рекомендуется применять COW для больших неизменяемых структур, где копий создается много, а записи случаются редко.
Как работает механизм Copy on Write на уровне памяти

Механизм Copy on Write базируется на разделении ссылок на один участок памяти между несколькими объектами. При создании копии объект не дублируется сразу: оба экземпляра указывают на одну область памяти. Только при попытке записи в один из объектов система выделяет новую память и копирует данные, чтобы изменения не затронули другие копии.
На уровне памяти это реализуется через счетчики ссылок и защиту страниц. Каждый участок памяти снабжается счетчиком ссылок, который отслеживает количество объектов, ссылающихся на данные. Попытка записи вызывает проверку счетчика: если он больше 1, выделяется новый блок памяти и выполняется копирование.
Принцип работы можно представить в виде таблицы:
| Действие | Состояние памяти | Счетчик ссылок |
|---|---|---|
| Создание исходного объекта | Объект A занимает блок памяти X | X = 1 |
| Создание копии объекта | Объект B указывает на блок X | X = 2 |
| Изменение копии B | Выделяется новый блок памяти Y для B, копируются данные из X | X = 1, Y = 1 |
| Чтение объектов A и B | Каждый объект использует свой блок: A → X, B → Y | X = 1, Y = 1 |
Использование COW снижает нагрузку на систему при работе с большими структурами данных, особенно если большинство копий остаются неизменными. Для внедрения в проектах важно контролировать участки памяти с высокой частотой изменений: слишком частое копирование может нивелировать преимущества COW.
Различие между копированием при записи и обычным копированием объектов
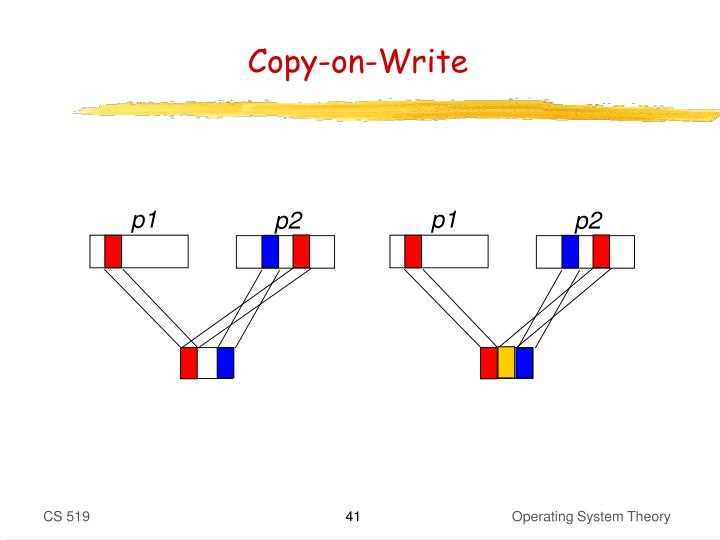
Обычное копирование объектов подразумевает немедленное дублирование всех данных в памяти при создании нового экземпляра. Каждая копия занимает отдельный блок памяти, независимо от того, будут данные изменяться или нет. Это увеличивает расход оперативной памяти и время выполнения операций копирования для больших структур.
Копирование при записи (Copy on Write) откладывает дублирование до момента модификации объекта. До первой записи все копии разделяют один блок памяти, что снижает накладные расходы при передаче данных между функциями или потоками.
Основные различия можно представить в виде списка:
- Момент копирования: обычное копирование – сразу, COW – при изменении.
- Использование памяти: обычное копирование создает дубликаты, COW использует один блок для нескольких объектов до записи.
- Производительность: обычное копирование нагружает систему при каждом создании копий, COW снижает нагрузку, если изменения редки.
- Многопоточность: COW позволяет безопасно использовать неизменяемые объекты разными потоками без блокировок.
- Управление ссылками: COW требует счетчиков ссылок или аналогичных механизмов для отслеживания общего использования памяти.
Для практической реализации COW рекомендуется применять его к объектам с большими объемами данных и низкой частотой изменений. Если структура данных часто модифицируется, обычное копирование может быть более предсказуемым с точки зрения производительности.
Использование Copy on Write в строках и массивов в C++

В C++ Copy on Write (COW) применялся для оптимизации работы с объектами типа std::string и динамическими массивами до стандарта C++11. При создании копии строки или массива новый объект не выделял отдельный буфер, а ссылался на существующий блок памяти. Фактическое копирование выполнялось только при изменении содержимого.
Для строк это реализуется через внутренний счетчик ссылок и структуру данных, которая хранит указатель на массив символов, размер строки и количество ссылок. Пример поведения:
1. Создание строки str1 выделяет буфер и устанавливает счетчик ссылок = 1.
2. Копирование str2 = str1 увеличивает счетчик ссылок до 2, буфер общий.
3. Изменение str2[0] = ‘A’ вызывает выделение нового буфера для str2, копирование данных из исходного буфера и уменьшение счетчика ссылок у str1.
Для массивов COW применим в пользовательских контейнерах. Создание копии массива лишь увеличивает счетчик ссылок на общий буфер, а при записи выделяется отдельная память. Такой подход экономит память при работе с большими структурами, передаче в функции и возврате из них.
Рекомендации при использовании COW в C++:
— Применять для объектов с большим объемом данных и редкими изменениями.
— Для многопоточной среды использовать атомарные счетчики ссылок или блокировки при изменении.
— В современных стандартах C++ (C++11 и выше) стандартная реализация std::string отказалась от COW, поэтому при необходимости использовать собственные классы с COW.
Применение Copy on Write в многопоточном программировании
В многопоточных приложениях Copy on Write (COW) позволяет безопасно использовать общие данные без постоянных блокировок. Несколько потоков могут одновременно читать один объект, при этом модификация инициирует создание отдельной копии, исключая конфликты.
Основные принципы работы COW в многопоточном контексте:
1. Общие данные хранятся в памяти с атомарным счетчиком ссылок.
2. Чтение объектов не требует блокировок, так как данные неизменяемы до первой записи.
3. При записи поток выполняет выделение нового блока памяти и копирование содержимого, обновляя счетчик ссылок.
Рекомендации по внедрению COW в многопоточную среду:
— Использовать атомарные операции для счетчиков ссылок, чтобы избежать гонок данных.
— Применять COW для больших структур с частыми чтениями и редкими изменениями, чтобы снизить накладные расходы на синхронизацию.
— Для часто изменяемых объектов предпочтительнее использовать локальные копии, так как частые выделения памяти могут замедлять выполнение.
Примеры применения включают кеши конфигурационных данных, многопоточную обработку текстовых или бинарных буферов и реализацию безопасных immutable-контейнеров, где каждый поток получает собственную версию при изменении.
Copy on Write в операционных системах и виртуальной памяти
В операционных системах Copy on Write используется для оптимизации работы с виртуальной памятью, особенно при клонировании процессов. При вызове fork() в Unix-подобных системах память родительского процесса не копируется сразу. Обе задачи ссылаются на один набор страниц, помеченных как только для чтения. Изменение любой страницы вызывает ее копирование, что минимизирует расход памяти и ускоряет создание процессов.
Механизм COW в виртуальной памяти реализован через таблицы страниц. Каждая страница снабжена битом COW, который блокирует запись. Попытка записи инициирует исключение (page fault), при котором система выделяет новую страницу, копирует содержимое и обновляет таблицу страниц для процесса, инициировавшего запись.
Применение COW в ОС позволяет:
— Уменьшить объем используемой физической памяти при множественных копиях процессов.
— Снизить задержки при запуске новых процессов.
— Поддерживать быстрые снапшоты файловых систем, например в ZFS или Btrfs, где изменяются только измененные блоки.
Рекомендации при разработке приложений с учетом COW в ОС:
— Минимизировать ненужные записи в разделяемых структурах данных, чтобы сохранять преимущества COW.
— При проектировании больших процессов учитывать, что частые модификации разделяемых страниц приводят к дополнительным копированием и накладным расходам.
— Использовать COW в файловых системах для реализации резервных копий и снапшотов, чтобы сократить использование дискового пространства.
Реализация Copy on Write в библиотеках и фреймворках
Библиотеки и фреймворки используют Copy on Write для оптимизации работы с большими данными и упрощения управления памятью. В C++ STL до стандарта C++11 std::string применял COW для хранения символов, используя внутренние счетчики ссылок и отложенное копирование при записи.
В языках с управляемой памятью, таких как Java и .NET, COW реализуется через специализированные контейнеры, например CopyOnWriteArrayList. Все операции чтения выполняются без блокировок, а при записи создается новая копия массива, что позволяет безопасно работать в многопоточной среде.
В JavaScript и TypeScript COW применяется в некоторых библиотеках для управления состоянием, например, в Immutable.js. Структуры данных разделяют неизменяемые блоки, а изменение инициирует копирование только изменяемой части, сохраняя предыдущие версии объектов.
Рекомендации по использованию COW в библиотеках:
— Применять для коллекций и структур данных с большим числом чтений и редкими модификациями.
— Проверять, как библиотека реализует счетчики ссылок и копирование, чтобы избежать скрытых накладных расходов.
— В многопоточной среде использовать только проверенные реализации COW, где операции записи атомарны или синхронизированы.
Проблемы и ограничения при использовании Copy on Write
Использование Copy on Write (COW) снижает расход памяти и повышает производительность при чтении, но имеет ряд ограничений и потенциальных проблем:
- Частые модификации: если объект часто изменяется, накладные расходы на выделение памяти и копирование могут превысить преимущества COW.
- Сложности в многопоточности: счетчики ссылок должны быть атомарными, иначе возможны гонки данных и повреждение памяти.
- Совместимость с современными стандартами: некоторые стандартные контейнеры, например std::string в C++11 и выше, отказались от COW из-за проблем с потокобезопасностью.
- Скрытые накладные расходы: управление счетчиками ссылок и обработка исключений при записи увеличивает сложность реализации и может снижать предсказуемость производительности.
- Память при частичном копировании: большие объекты с множеством копий могут неожиданно потреблять много памяти, если изменения происходят одновременно в нескольких местах.
Рекомендации для применения COW:
- Использовать для объектов с большим объемом данных и редкими изменениями.
- В многопоточных приложениях применять только проверенные реализации с атомарными счетчиками ссылок.
- Анализировать частоту изменений и структуру данных перед внедрением COW, чтобы избежать излишних операций копирования.
Примеры оптимизации ресурсов с Copy on Write на практике
Механизм Copy on Write позволяет экономить память и ускорять выполнение операций в случаях, когда данные создаются в большом объеме и редко изменяются.
В C++ строки и массивы можно копировать без немедленного выделения новой памяти. Копия ссылается на существующий буфер, а реальное копирование выполняется только при записи. Такой подход снижает расход оперативной памяти при передаче объектов в функции и возврате из них.
В Java контейнер CopyOnWriteArrayList обеспечивает безопасное чтение в многопоточной среде. Все записи создают отдельную копию массива, не блокируя потоки, выполняющие чтение. Это особенно полезно для кешей и неизменяемых коллекций с редкими модификациями.
Файловые системы Btrfs и ZFS используют COW для создания снапшотов. Изменяются только блоки, подвергшиеся записи, а неизменные блоки остаются общими, что экономит дисковое пространство и ускоряет резервное копирование.
В Unix-подобных системах вызов fork() использует COW для памяти процесса. Новый процесс разделяет страницы с родителем до первой записи, что снижает потребление памяти и ускоряет клонирование процессов.
Рекомендации по практическому применению COW:
— Использовать для больших структур данных с редкими изменениями.
— В многопоточной среде выбирать реализации с атомарными счетчиками ссылок.
— Анализировать частоту записи, чтобы избежать лишнего копирования и накладных расходов.
Вопрос-ответ:
Что такое Copy on Write и как он работает на уровне памяти?
Copy on Write (COW) — это механизм управления памятью, при котором копии объекта создаются без немедленного дублирования данных. Все копии сначала ссылаются на один блок памяти, а фактическое копирование выполняется только при изменении содержимого. На уровне памяти это реализуется с помощью счетчиков ссылок и защиты страниц: попытка записи в объект с общим блоком вызывает выделение нового блока памяти и копирование данных, а счетчик ссылок исходного блока уменьшается.
В каких ситуациях Copy on Write дает наибольшую пользу?
Наибольшую выгоду COW приносит при работе с большими объектами, которые часто копируются, но редко изменяются. Примеры включают строки и массивы в C++, многопоточные коллекции в Java, кеши неизменяемых данных и снапшоты файловых систем. В таких сценариях экономится оперативная память, а операции копирования становятся менее ресурсоемкими, поскольку дублирование выполняется только при записи.
Какие ограничения есть у Copy on Write при многопоточном программировании?
В многопоточном контексте COW требует безопасного управления счетчиками ссылок, чтобы избежать гонок данных. Чтение объектов можно выполнять без блокировок, но запись должна инициировать выделение нового блока. Частые записи в разделяемых объектах могут привести к высокому количеству копирований и снижению производительности. Поэтому COW лучше использовать для структур с преобладанием чтения над записью.
Почему современные реализации std::string в C++ отказались от Copy on Write?
До стандарта C++11 строки использовали COW для экономии памяти при копировании. В современных реализациях отказ от COW объясняется проблемами с потокобезопасностью и непредсказуемыми накладными расходами при записи. Атомарное управление счетчиками ссылок и обработка исключений при изменении данных усложняли реализацию и могли снижать производительность в многопоточных приложениях, поэтому современные версии std::string создают независимые копии сразу.
Как Copy on Write используется в файловых системах и процессах?
В файловых системах, таких как Btrfs и ZFS, COW применяется для создания снапшотов: изменяются только измененные блоки данных, а неизменные остаются общими. Это экономит дисковое пространство и ускоряет резервное копирование. В Unix-подобных системах при вызове fork() новый процесс разделяет страницы памяти с родителем до первой записи, что снижает расход оперативной памяти и ускоряет клонирование процессов, так как копирование происходит только при необходимости.
Как Copy on Write влияет на расход памяти и производительность при работе с большими структурами данных?
Copy on Write снижает расход памяти за счет того, что несколько копий объекта сначала ссылаются на один блок данных. Фактическое копирование происходит только при изменении содержимого. Это особенно полезно для больших массивов, строк или объектов, которые часто передаются между функциями или потоками без изменения. В таких случаях количество операций копирования и использование памяти уменьшается, а чтение данных выполняется быстро. Однако при частых изменениях накладные расходы на выделение новой памяти и копирование могут нивелировать преимущества, поэтому важно анализировать характер изменений в данных перед применением COW.