Сложные SQL-запросы часто появляются в отчетах, аналитике и бизнес-логике, где требуется объединить несколько источников данных, выполнить фильтрацию, агрегацию и расчеты в одном выражении. Со временем такой запрос разрастается: увеличивается количество JOIN, подзапросов и условий, а чтение и отладка начинают занимать больше времени, чем сама разработка.
Разбиение запроса на логические части позволяет управлять структурой вычислений и контролировать каждый этап обработки данных. Вместо одного монолитного выражения используются CTE, временные таблицы, представления или последовательные подзапросы, где каждая часть отвечает за конкретную задачу: подготовку данных, фильтрацию, агрегацию или финальный расчет.
Такой подход помогает быстрее находить ошибки в условиях JOIN, проверять промежуточные результаты и вносить изменения без риска затронуть всю логику сразу. Например, при работе с большими таблицами можно отдельно проверить корректность выборки за период, затем – правильность группировки, и только после этого собирать итоговый результат.
В статье рассматриваются практические способы декомпозиции SQL-запросов, примеры применения CTE и временных структур, а также приемы, которые упрощают поддержку кода при росте требований к отчетам и аналитике.
Выделение логических этапов выборки данных в одном запросе
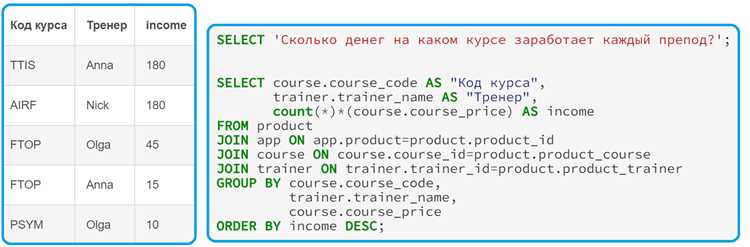
При работе с многоуровневой выборкой первый шаг – определить границы логических этапов, которые уже присутствуют в запросе. Обычно это отдельные операции: ограничение набора строк по периоду, связывание таблиц по ключам, расчет производных полей и финальная агрегация. Эти этапы не должны смешиваться в одном выражении SELECT, так как это усложняет контроль результата.
Практический прием – переписать исходный запрос на бумаге или в комментариях, разбив его на блоки «что отбирается», «как связывается» и «как считается». После этого каждый блок можно оформить как отдельный логический слой внутри одного запроса, например с помощью CTE или вложенных подзапросов, не меняя итоговый набор данных.
Фильтрацию по базовым условиям рекомендуется выполнять на самом раннем этапе. Это относится к датам, статусам, типам записей и другим полям с высокой селективностью. Если фильтр применяется после JOIN или агрегации, возрастает риск получить лишние строки и некорректные суммы.
Соединения таблиц лучше группировать по смыслу: сначала обязательные связи по первичным и внешним ключам, затем дополнительные JOIN для обогащения данных справочниками. Такое разделение упрощает проверку кратности строк и позволяет быстрее обнаружить ошибку, когда одна запись неожиданно размножается.
Расчеты и агрегатные функции следует выносить в отдельный этап, где входные данные уже проверены. Например, суммы, средние значения и оконные функции должны работать с предсказуемым набором строк. Это снижает вероятность логических ошибок и упрощает изменение формул без переработки всей выборки.
Четкое выделение логических этапов в одном запросе делает структуру прозрачной: каждый фрагмент можно проверить отдельным SELECT, сравнить промежуточные результаты и убедиться, что итоговый набор данных формируется осознанно, а не как побочный эффект сложного выражения.
Использование CTE для поэтапной обработки результатов
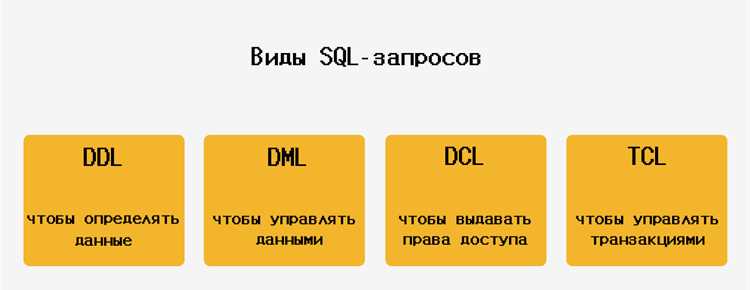
CTE (Common Table Expressions) позволяют разложить сложный SQL-запрос на последовательность связанных шагов, где каждый шаг опирается на результат предыдущего. Такой подход особенно полезен, когда в одном запросе сочетаются фильтрация, объединение таблиц, расчеты и агрегация.
Каждый CTE должен решать одну прикладную задачу и возвращать набор данных с понятной структурой. Практика показывает, что оптимальное количество колонок в одном CTE – только те, которые действительно нужны на следующем этапе, без промежуточных полей «на всякий случай».
- Первый CTE – ограничение исходных данных по датам, статусам и типам записей.
- Второй CTE – объединение с основными таблицами по ключам.
- Третий CTE – расчеты производных полей и подготовка значений для агрегации.
- Финальный SELECT – группировка и формирование результата для отчета.
Такое разбиение упрощает контроль логики. Каждый CTE можно выполнить отдельно, временно закомментировав остальные, и проверить объем строк, дубликаты и корректность вычислений. Это особенно полезно при работе с оконными функциями и сложными условиями JOIN.
Рекомендуется давать CTE осмысленные имена, отражающие их назначение, а не технические детали. Например, filtered_orders или orders_with_payments читаются заметно лучше, чем cte1 и cte2.
- Не смешивать фильтрацию и агрегацию в одном CTE.
- Избегать повторного использования одних и тех же расчетов в разных CTE.
- Проверять планы выполнения, если CTE используется несколько раз.
Поэтапная обработка через CTE делает запрос предсказуемым при доработках: добавление нового расчета или условия затрагивает конкретный шаг, а не всю конструкцию целиком.
Разделение вложенных подзапросов на отдельные представления

Вынос вложенного подзапроса в отдельное представление позволяет зафиксировать результат конкретного шага и работать с ним как с обычной таблицей. Представление описывает бизнес-смысл выборки, а не техническую реализацию, что упрощает чтение основного запроса.
Практический признак для создания представления – подзапрос используется в нескольких местах или содержит сложную логику фильтрации и JOIN. В таких случаях представление снижает риск расхождений, когда одно и то же условие переписывается вручную с ошибками.
Рекомендуется выносить в представления подзапросы, которые: формируют базовый набор данных, рассчитывают агрегаты по устойчивым правилам или объединяют основные таблицы предметной области. Финальные фильтры и сортировки лучше оставлять в основном запросе, чтобы не ограничивать повторное использование представления.
При проектировании представления стоит явно задавать список колонок и избегать SELECT *. Это упрощает контроль изменений структуры таблиц и снижает вероятность неожиданных конфликтов имен при дальнейшем JOIN.
Разделение вложенных подзапросов на представления превращает сложный SQL в цепочку понятных операций, где каждый уровень можно анализировать, тестировать и переиспользовать без погружения в многоуровневую вложенность.
Замена длинных JOIN-цепочек временными таблицами

Длинные цепочки JOIN из пяти и более таблиц быстро усложняют запрос: растет количество условий соединения, сложнее контролировать кратность строк и проверять корректность промежуточных данных. В таких случаях разумно выделить часть логики во временную таблицу и работать уже с подготовленным набором.
Временная таблица фиксирует результат объединения нескольких таблиц на конкретном этапе. Это позволяет один раз проверить связи по ключам и дальше использовать результат без повторного описания всей JOIN-логики. Такой прием особенно полезен при отчетах, где одни и те же объединения применяются для разных расчетов.
Чаще всего во временную таблицу выносятся обязательные JOIN между основными сущностями: заказы, клиенты, платежи, статусы. Дополнительные справочники и фильтры подключаются уже на следующем шаге, что упрощает чтение запроса.
| Подход | Особенности | Когда применять |
|---|---|---|
| Длинная JOIN-цепочка | Вся логика в одном SELECT, много условий соединения | Простые запросы без повторного использования |
| Временная таблица | Фиксированный набор данных после объединения | Сложные отчеты и многошаговые расчеты |
При создании временной таблицы важно сразу задать корректные индексы по полям, которые будут использоваться в последующих JOIN и фильтрах. Это снижает нагрузку при повторных обращениях к данным в рамках одного сценария.
Также стоит ограничивать состав колонок временной таблицы только теми полями, которые реально участвуют в дальнейших операциях. Избыточные данные увеличивают объем и усложняют контроль структуры.
Замена длинных JOIN-цепочек временными таблицами делает запросы более предсказуемыми: каждый шаг можно проверить отдельным SELECT, а основная логика перестает зависеть от громоздкого блока соединений.
Декомпозиция агрегатных вычислений по уровням
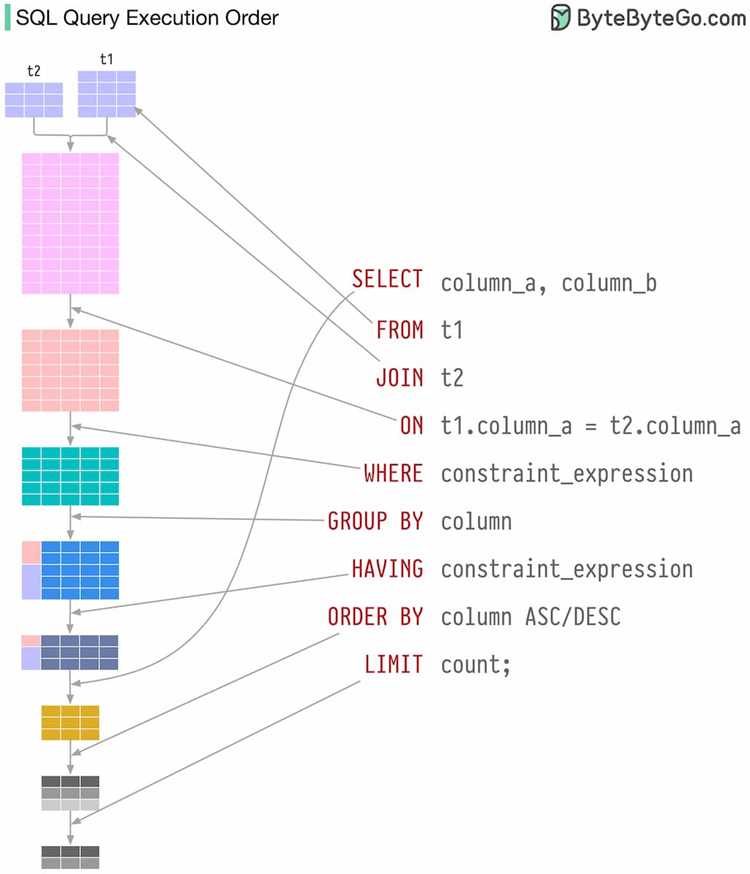
Сложные агрегатные вычисления часто объединяют несколько функций в одном запросе: суммы, средние значения, минимумы и максимумы, иногда с условиями по разным группировкам. Когда все операции выполняются одновременно, сложно контролировать корректность результатов и находить ошибки в промежуточных этапах.
Рекомендуется разбивать вычисления по уровням: сначала формируется базовый набор данных с фильтрацией и первичными расчетами, затем создаются агрегаты на промежуточных уровнях, и только после этого – итоговые показатели. Такой подход позволяет проверять каждый шаг отдельно и уменьшает вероятность логических ошибок.
Например, при расчете выручки по регионам сначала вычисляют сумму продаж по магазинам (уровень 1), затем объединяют эти суммы по регионам (уровень 2), а на финальном уровне рассчитывают среднюю выручку и долю каждого региона в общей сумме (уровень 3).
Для реализации удобно использовать CTE или временные таблицы, где каждый уровень представлен отдельным блоком. Это облегчает тестирование и отладку: промежуточные результаты можно проверить SELECT отдельно, сравнивая с ожидаемыми значениями.
При декомпозиции агрегатных вычислений важно избегать повторного пересчета одних и тех же показателей на разных уровнях. Для этого промежуточные агрегаты фиксируются в отдельной структуре и используются повторно, что ускоряет выполнение и снижает нагрузку на сервер.
Вопрос-ответ:
Зачем разбивать сложный SQL-запрос на части, если он работает правильно?
Даже если запрос возвращает корректный результат, монолитная конструкция усложняет проверку, доработку и сопровождение. Разделение на логические этапы позволяет проверять промежуточные данные, облегчает поиск ошибок в JOIN и фильтрах, а также упрощает внесение изменений без риска нарушить всю логику.
Какие подходы лучше использовать для поэтапной обработки данных: CTE или временные таблицы?
CTE удобны для логической декомпозиции и кратковременной работы с данными внутри одного запроса, особенно если этапы не повторяются многократно. Временные таблицы полезны, когда один и тот же результат используется в нескольких запросах или для больших объемов данных, где важно контролировать индексы и производительность.
Как определить, какие подзапросы стоит вынести в отдельные представления?
Подзапросы выносят в представления, если они повторяются в нескольких местах, содержат сложные условия или формируют устойчивый набор данных. Представление фиксирует результат определенного этапа и позволяет повторно использовать его без переписывания логики, снижая вероятность ошибок при объединении с другими таблицами.
Можно ли комбинировать декомпозицию агрегатов с разделением JOIN-цепочек?
Да, это стандартная практика. Сначала создают отдельные JOIN-цепочки через временные таблицы или CTE, чтобы получить корректный набор строк. Затем на этих данных выполняют агрегатные вычисления по уровням. Такой подход позволяет проверить как правильность объединений, так и точность итоговых показателей.
Какие ошибки чаще всего возникают при неправильном разбиении запроса на части?
Наиболее частые ошибки: дублирование строк из-за некорректных JOIN, применение фильтров после агрегации вместо предварительного этапа, повторный пересчет одних и тех же агрегатов, а также потеря контроля над промежуточными результатами. Разделение запроса на логические блоки снижает риск этих проблем.