Содержание статьи

В Python поиск конкретного слова в строке можно выполнить с помощью встроенных методов без подключения сторонних библиотек. Оператор in позволяет быстро проверить, содержится ли заданная последовательность символов в строке, возвращая True или False. Это удобно для условий и фильтров в коде.
Методы find() и index() дают возможность определить позицию слова внутри строки. При этом find() возвращает -1, если слово не найдено, а index() генерирует исключение, что важно учитывать при обработке ошибок.
Для поиска без учета регистра рекомендуется использовать lower() или upper(), преобразуя строку и слово к одному регистру. Метод count() позволяет быстро подсчитать количество вхождений, а split() разделяет строку на слова, облегчая точное сопоставление.
Даже для более сложных случаев, когда нужны шаблоны или частичные совпадения, простые методы часто оказываются быстрее и читаемее, чем регулярные выражения, особенно при обработке коротких строк и небольших текстовых массивов.
Использование оператора in для проверки наличия слова
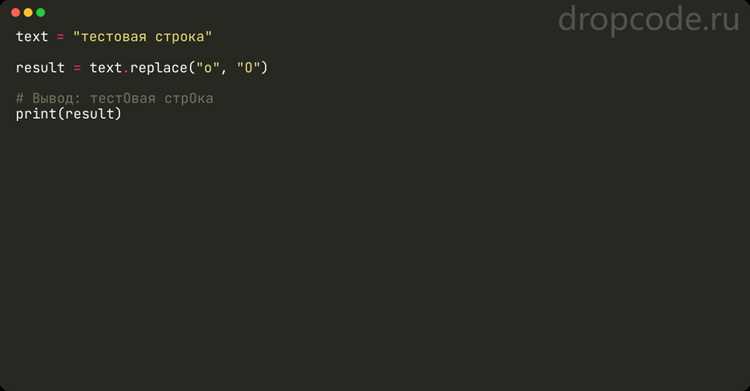
Оператор in позволяет проверить, содержится ли заданное слово в строке. Он возвращает True, если последовательность символов найдена, и False в противном случае. Например, выражение ‘Python’ in text вернет True, если в переменной text встречается слово «Python».
Для поиска без учета регистра строку и слово можно привести к одному регистру с помощью lower() или upper(). Например, ‘python’ in text.lower() найдет слово независимо от исходного регистра текста.
Оператор in удобен при фильтрации списков или словарей, когда необходимо оставить только элементы, содержащие определенное слово. Такой подход минимизирует использование дополнительных функций и сокращает количество строк кода.
При проверке наличия слова в больших текстах оператор in работает быстрее, чем методы поиска с обработкой исключений, и обеспечивает чистый и наглядный синтаксис, подходящий для условий и циклов.
Метод find() для нахождения позиции слова в строке
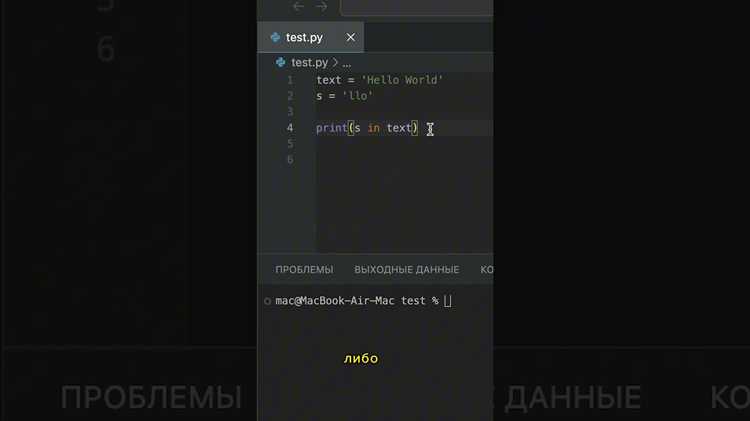
Метод find() возвращает индекс первого вхождения указанного слова в строке. Если слово не найдено, метод возвращает -1. Пример: text.find(‘Python’) вернет позицию первого символа слова «Python» в строке text, либо -1, если слово отсутствует.
Метод принимает дополнительные параметры start и end, позволяющие ограничить область поиска. Например, text.find(‘Python’, 10, 50) ищет слово только между 10 и 50 символами строки.
Для поиска без учета регистра можно применять lower() или upper(), например: text.lower().find(‘python’). Это позволяет корректно находить слова в тексте с разными регистрами.
Метод find() особенно полезен при необходимости определить позицию слова для последующей обработки, например, извлечения подстроки или замены конкретного фрагмента текста.
Метод index() и обработка исключений при поиске слова

Метод index() возвращает индекс первого вхождения указанного слова в строке. В отличие от find(), если слово не найдено, index() генерирует исключение ValueError, что требует явной обработки ошибок.
Рекомендации по использованию метода:
- Оборачивайте вызов index() в блок try-except, чтобы избежать прерывания программы.
- Используйте start и end для ограничения области поиска: text.index(‘Python’, 5, 50).
- Для поиска без учета регистра преобразуйте строку и слово к одному регистру: text.lower().index(‘python’).
Пример обработки исключения:
- Попытка найти слово с помощью index().
- Если слово найдено, метод возвращает позицию, которую можно использовать для извлечения или замены фрагмента строки.
Использование index() целесообразно, когда необходимо гарантированно определить позицию слова и обработать ситуацию его отсутствия через исключения.
Поиск слова с учетом регистра с помощью lower() или upper()
Методы lower() и upper() позволяют привести строку и слово к одному регистру перед поиском, что упрощает проверку наличия слова без учета исходного регистра. Например, ‘python’ in text.lower() найдет слово «Python», «PYTHON» или «PyThOn».
Применение этих методов совместимо с любыми стандартными способами поиска:
- Оператор in: ‘data’ in text.upper() вернет True, если слово встречается в любом регистре.
- Метод find(): text.lower().find(‘example’) вернет индекс первого вхождения слова без учета регистра.
- Метод index(): text.upper().index(‘STRING’) вернет позицию слова или вызовет исключение, если оно отсутствует.
Рекомендации:
- Используйте lower() или upper() для унификации текста и ключевого слова перед поиском.
- При работе с большими текстами преобразование к одному регистру незначительно влияет на производительность, но повышает точность поиска.
- Комбинируйте с методами подсчета вхождений или извлечения подстрок для более гибкой обработки текста.
Использование метода count() для подсчета вхождений слова

Метод count() позволяет определить, сколько раз заданное слово встречается в строке. Он возвращает целое число, отражающее количество вхождений. Пример: text.count(‘Python’) вернет число, равное количеству повторов слова «Python» в переменной text.
Метод принимает два необязательных параметра: start и end, позволяющие ограничить область поиска. Например, text.count(‘Python’, 10, 50) посчитает вхождения только между 10 и 50 символами строки.
Для поиска без учета регистра строку и слово можно привести к одному регистру с помощью lower() или upper(), например: text.lower().count(‘python’).
Пример использования метода count() для анализа текста:
| Строка | Слово | Количество вхождений |
|---|---|---|
| Python изучается в разных курсах. Python удобен для автоматизации. | Python | 2 |
| Регулярные выражения помогают искать текст. Python упрощает работу с текстом. | Python | 1 |
Использование count() удобно при подсчете ключевых слов, фильтрации данных и анализе частоты встречаемости слов в текстовых блоках.
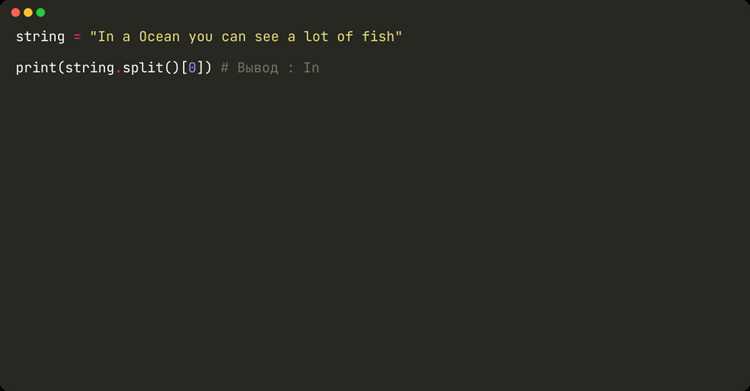
Применение метода split() для поиска слова среди отдельных слов
Метод split() разделяет строку на список отдельных слов по заданному разделителю. По умолчанию используется пробел. Это позволяет выполнять точный поиск слова среди элементов списка, исключая частичные совпадения внутри других слов.
Пример использования:
- Разделяем строку на слова: words = text.split().
- Проверяем наличие слова: ‘Python’ in words вернет True, если слово встречается как отдельный элемент.
Рекомендации:
- Для удаления знаков препинания используйте strip() или модули re перед поиском.
- Если необходимо искать без учета регистра, преобразуйте слова: [w.lower() for w in text.split()].
- Метод split() подходит для фильтрации и подсчета отдельных слов, особенно в текстах с большим количеством пробелов или пунктуации.
Применение split() позволяет точно выделять слова, избегая ложных совпадений, которые могут возникнуть при использовании in или find() на всей строке.
Сравнение поиска с использованием регулярных выражений и простых методов
Регулярные выражения (re) позволяют искать сложные шаблоны и частичные совпадения в строках. Пример: re.search(r’\bPython\b’, text) находит слово «Python» как отдельное, игнорируя подстроки внутри других слов.
Простые методы Python, такие как in, find(), index(), count() и split(), обеспечивают прямой поиск и подсчет слов без написания шаблонов. Они быстрее и проще в использовании для коротких и структурированных строк.
Сравнение по критериям:
- Сложность текста: для длинных документов с разными форматами регулярные выражения удобнее, для коротких строк простые методы быстрее и нагляднее.
- Точность поиска: регулярные выражения точнее при поиске отдельных слов, границ и шаблонов, простые методы подходят для прямого совпадения.
- Производительность: простые методы минимизируют накладные расходы и работают быстрее при обработке больших списков коротких строк.
- Читаемость кода: использование in или find() делает код понятным, тогда как регулярные выражения требуют дополнительного изучения синтаксиса.
Рекомендации:
- Использовать простые методы для быстрого поиска отдельных слов или подсчета вхождений.
- Применять регулярные выражения при необходимости искать шаблоны, границы слов или сложные комбинации символов.
- Комбинировать подходы: для предварительной фильтрации использовать простые методы, а для точного соответствия – регулярные выражения.
Вопрос-ответ:
Как проверить наличие конкретного слова в строке Python?
Для проверки наличия слова в строке можно использовать оператор in. Он возвращает True, если слово встречается в строке, и False в противном случае. Пример: ‘Python’ in text вернет True, если строка text содержит слово «Python». Для поиска без учета регистра сначала преобразуйте строку и слово к одному регистру с помощью lower() или upper().
В чем отличие методов find() и index() при поиске слова?
Метод find() возвращает индекс первого вхождения слова или -1, если слово не найдено. Метод index() возвращает индекс, но при отсутствии слова генерирует исключение ValueError. Использование try-except позволяет безопасно обрабатывать ошибки при применении index(). Оба метода поддерживают параметры start и end для ограничения области поиска.
Как подсчитать количество вхождений слова в строке?
Для подсчета вхождений можно использовать метод count(). Он возвращает число повторов заданного слова в строке. Пример: text.count(‘Python’) покажет, сколько раз слово «Python» встречается в переменной text. Для поиска без учета регистра примените lower() или upper() к строке и слову.
Можно ли искать слова среди отдельных слов, а не подстрок?
Да, для точного поиска отдельных слов удобно использовать метод split(). Он разбивает строку на список слов по пробелам или другому разделителю. Например: words = text.split(), затем проверяем наличие слова с помощью ‘Python’ in words. Чтобы игнорировать регистр, примените lower() к каждому элементу списка.
Когда стоит использовать регулярные выражения вместо простых методов?
Регулярные выражения позволяют искать сложные шаблоны, учитывать границы слов и частичные совпадения. Простые методы подходят для прямого поиска, подсчета и выделения слов в коротких строках. Для больших текстов или сложных условий поиска регулярные выражения обеспечивают гибкость, но для коротких и структурированных строк удобнее использовать in, find(), index(), count() или split() без лишнего синтаксиса.