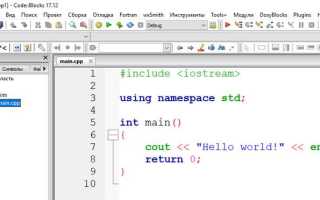
Директива #include в языке C позволяет подключать файлы с готовыми алгоритмами и функциями, обеспечивая доступ к ним в любом месте программы. Это включает как стандартные библиотеки, так и пользовательские заголовочные файлы, что упрощает повторное использование кода и поддержку проектов.
Стандартные заголовочные файлы, например stdlib.h, string.h или math.h, содержат алгоритмы для работы с памятью, строками, массивами, математическими вычислениями и сортировкой. Их подключение через #include исключает необходимость ручной реализации базовых операций и повышает точность вычислений.
Пользовательские файлы с алгоритмами создаются с расширением .h и включаются в основной код через #include «имя_файла.h». Для предотвращения повторного включения следует использовать защиту через #ifndef, #define и #endif, что предотвращает конфликты и ошибки компиляции при масштабировании проекта.
Правильное структурирование include упрощает чтение кода и уменьшает количество зависимостей между файлами. Разделение алгоритмов на отдельные заголовочные файлы позволяет быстро обновлять функциональность и интегрировать новые методы без изменения основной программы.
Зачем подключать алгоритмы с помощью include в C
Подключение алгоритмов через #include позволяет использовать готовые функции для сортировки, поиска, работы с массивами и строками без повторной реализации. Это снижает количество ошибок и ускоряет процесс разработки.
Использование стандартных библиотек, таких как stdlib.h или string.h, дает доступ к проверенным алгоритмам, что повышает надежность программы и уменьшает нагрузку на тестирование.
Подключение пользовательских файлов с алгоритмами упрощает структуру проекта: функции хранятся отдельно, основной код остается компактным, а обновление алгоритмов не требует изменений в основной программе.
Через include легко управлять зависимостями между модулями. Защита от повторного включения с помощью #ifndef и #define предотвращает конфликты и ошибки компиляции при масштабировании проекта.
Синтаксис директивы #include для стандартных библиотек
Для подключения стандартных библиотек в C используется директива #include с угловыми скобками: #include <имя_библиотеки.h>. Скобки указывают компилятору искать файл в системных каталогах.
Например, подключение библиотеки для работы с памятью выполняется так: #include <stdlib.h>, а для работы со строками – #include <string.h>. После этого функции библиотеки становятся доступными в коде.
Директива #include вставляет содержимое указанного файла в момент компиляции. Это позволяет использовать алгоритмы без ручного копирования кода и гарантирует соответствие стандартам языка.
При использовании нескольких стандартных библиотек важно учитывать порядок подключений, чтобы избежать конфликтов имен и дублирования функций. Каждая библиотека должна подключаться только один раз.
Подключение пользовательских файлов с алгоритмами
В языке C для повторного использования алгоритмов рекомендуется создавать отдельные заголовочные файлы с расширением .h и соответствующие реализации в .c. Это позволяет структурировать код и облегчает сопровождение.
Основные шаги подключения пользовательских файлов с алгоритмами:
- Создание заголовочного файла: в
algorithm_utils.hобъявляются функции и структуры данных. Пример:
#ifndef ALGORITHM_UTILS_H
#define ALGORITHM_UTILS_H
int find_max(int arr[], int size);
void sort_array(int arr[], int size);
#endif
- Создание файла реализации: в
algorithm_utils.cописываются функции, объявленные в заголовочном файле.
#include "algorithm_utils.h"
int find_max(int arr[], int size) {
int max = arr[0];
for(int i = 1; i < size; i++) {
if(arr[i] > max) max = arr[i];
}
return max;
}
void sort_array(int arr[], int size) {
for(int i = 0; i < size - 1; i++) {
for(int j = 0; j < size - i - 1; j++) {
if(arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
- Подключение в основном файле: используйте директиву
#include "algorithm_utils.h"для доступа к функциям.
#include <stdio.h>
#include "algorithm_utils.h"
int main() {
int data[] = {5, 2, 9, 1};
int max = find_max(data, 4);
printf("Максимум: %d\n", max);
sort_array(data, 4);
return 0;
}
Рекомендации:
- Использовать защиту от повторного включения с
#ifndefи#define. - Разделять интерфейс (
.h) и реализацию (.c). - Соблюдать единый стиль именования функций и файлов.
- При работе с несколькими проектами создавать библиотечные файлы для повторного использования.
Разница между <> и «» при include
В языке C директива #include может использовать два типа оформления имени файла: угловые скобки <> и двойные кавычки "". Разница заключается в порядке поиска файлов компилятором.
| Тип включения | Описание | Пример |
|---|---|---|
| <> | Компилятор ищет файл сначала в стандартных системных каталогах, где хранятся заголовочные файлы языка C или сторонних библиотек. | #include <stdio.h> |
| «» | Компилятор сначала ищет файл в каталоге текущего проекта или там, где находится исходный файл, затем в системных каталогах. | #include "my_algorithm.h" |
Рекомендации:
- Используйте
<>для стандартных и внешних библиотек. - Используйте
""для собственных файлов проекта. - Для повышения переносимости указывайте относительные пути внутри кавычек, если структура каталогов сложная.
- Не смешивайте стили без необходимости, чтобы избежать конфликтов при компиляции.
Ошибки при include и способы их исправления
Наиболее частые ошибки при использовании директивы #include связаны с путями к файлам, повторным включением и несовместимостью заголовков.
Основные типы ошибок:
- Файл не найден: возникает при указании неправильного имени файла или пути.
- Повторное включение: одна и та же библиотека включена несколько раз без защиты от дублирования.
- Конфликты типов или объявлений: разные версии заголовочных файлов содержат одинаковые имена функций или структур.
Способы исправления:
- Проверять точность имени файла и путь. Для файлов проекта использовать относительные пути:
#include "folder/my_header.h". - Добавлять защиту от повторного включения с помощью
#ifndef,#defineи#endif: - Следить за совместимостью и версией заголовочных файлов при работе с внешними библиотеками.
- Для системных библиотек использовать
<>, для пользовательских –"", чтобы избежать конфликтов поиска. - В больших проектах использовать единообразную структуру каталогов для заголовков и исходников.
- Компиляторы часто поддерживают флаги для указания дополнительных директорий поиска, например
-Iв GCC.
#ifndef MY_HEADER_H
#define MY_HEADER_H
…объявления…
#endif
Регулярная проверка путей и корректное оформление заголовочных файлов предотвращает большинство ошибок при include.
Примеры использования стандартных алгоритмов после include
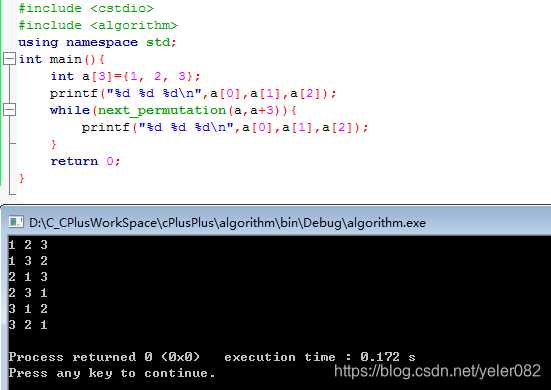
Подключение стандартных библиотек C позволяет применять встроенные алгоритмы для работы с массивами, строками и структурами данных. Наиболее часто используется #include <algorithm> в C++ для сортировки, поиска и манипуляций с последовательностями.
Примеры:
- Сортировка массива:
- Поиск элемента:
- Обратный порядок элементов:
#include <algorithm>
#include <vector>
#include <iostream>
int main() {
std::vector<int> v = {4, 1, 3, 2};
std::sort(v.begin(), v.end());
for(int i : v) std::cout << i << " ";
return 0;
}
#include <algorithm>
#include <vector>
#include <iostream>
int main() {
std::vector<int> v = {5, 2, 9, 1};
auto it = std::find(v.begin(), v.end(), 9);
if(it != v.end()) std::cout << "Найден: " << *it << std::endl;
return 0;
}
#include <algorithm>
#include <vector>
#include <iostream>
int main() {
std::vector<int> v = {1, 2, 3, 4};
std::reverse(v.begin(), v.end());
for(int i : v) std::cout << i << " ";
return 0;
}
Рекомендации:
- Использовать
begin() для указания диапазона элементов. - Для работы с C-массивами применять
std::begin() из<iterator>. - Выбирать алгоритмы из стандартной библиотеки вместо ручной реализации для повышения надежности и читаемости кода.
Как организовать несколько include для одного проекта
При работе с крупными проектами на C важно правильно структурировать подключение заголовочных файлов, чтобы избежать конфликтов, дублирования и ошибок компиляции.
Основные подходы:
- Разделение на модули: каждый функциональный блок проекта оформляется отдельным заголовочным (
.h) и исходным (.c) файлом. Например,math_utils.h/math_utils.c,string_utils.h/string_utils.c. - Защита от повторного включения: использовать
#ifndef,#define,#endifв каждом заголовочном файле: - Последовательность include: сначала системные библиотеки (
<stdio.h>,<stdlib.h>), затем внешние библиотеки, в конце – собственные заголовочные файлы проекта. Это снижает вероятность конфликтов и ошибок поиска. - Единая структура каталогов: хранить заголовочные файлы в отдельных папках, например
include/, а исходники – вsrc/. Подключение через относительные пути:#include "include/math_utils.h". - Использование предкомпилированных заголовков: для часто используемых библиотек и модулей создаются отдельные заголовочные файлы, включаемые в каждый исходник, что ускоряет компиляцию.
- Контроль версий и зависимости: при изменении одного заголовочного файла проверять все модули, которые его используют, чтобы избежать ошибок из-за несовместимости функций или структур.
#ifndef MATH_UTILS_H
#define MATH_UTILS_H
…объявления функций…
#endif
Вопрос-ответ:
Что делает директива #include в языке C?
Директива #include позволяет подключать содержимое других файлов, обычно заголовочных (.h), к исходному коду. Это дает доступ к функциям, структурам и константам, определенным в подключаемых файлах, без необходимости копировать код вручную.
В чем разница между include с угловыми скобками и с кавычками?
При использовании угловых скобок #include <file> компилятор ищет файл в стандартных системных каталогах. Кавычки #include "file" сначала проверяют каталог текущего проекта, а затем системные пути. Для системных библиотек используют скобки, для собственных файлов — кавычки.
Как подключать несколько пользовательских файлов с алгоритмами без ошибок?
Для каждого модуля создают отдельный заголовочный (.h) и исходный (.c) файл. В заголовочных файлах используют защиту от повторного включения с #ifndef, #define и #endif. Файлы подключают в основном коде через #include, соблюдая последовательность: сначала системные, затем внешние, в конце свои.
Какие стандартные алгоритмы можно использовать после include <algorithm>?
Библиотека <algorithm> содержит функции сортировки (sort), поиска (find), перестановки (reverse), удаления дубликатов и другие. Они работают с диапазонами элементов через begin() и end(), что упрощает обработку массивов, векторов и других последовательностей.