Содержание статьи

В pandas для анализа данных часто требуется определить все уникальные значения в столбце. Метод unique() возвращает массив numpy, содержащий неповторяющиеся элементы, что позволяет быстро оценить разнообразие данных в колонке.
Если важно не только увидеть уникальные значения, но и подсчитать их количество, применяется value_counts(). Этот метод возвращает Series с индексами уникальных элементов и их частотой, упрощая идентификацию наиболее и наименее распространенных значений.
Для работы с несколькими столбцами одновременно используется комбинация drop_duplicates() и указание нужных колонок. Это позволяет создавать срезы таблицы с уникальными комбинациями данных, что полезно при подготовке сводных таблиц или выявлении дубликатов.
Результаты можно преобразовать в список с помощью tolist() и отсортировать методом sort(). Это упрощает дальнейшее использование уникальных значений в циклах, функциях или для построения визуализаций.
Пропущенные значения в столбцах pandas обозначаются NaN. Методы dropna() или параметр dropna=False в value_counts() позволяют контролировать их включение или исключение при получении уникальных значений.
Использование метода unique для одного столбца
Метод unique() возвращает массив numpy с неповторяющимися значениями указанного столбца. Например, df[‘column_name’].unique() сразу покажет все уникальные элементы, включая числа, строки и даты.
Метод сохраняет порядок появления элементов в столбце. Это удобно для анализа временных данных или категорий, где важен оригинальный порядок. Для больших наборов данных результат можно сразу преобразовать в список с tolist() для дальнейшей обработки.
Если столбец содержит пропущенные значения (NaN), они также будут включены в массив. Чтобы исключить их, применяется dropna() перед вызовом unique(): df[‘column_name’].dropna().unique(). Это обеспечивает чистый набор неповторяющихся данных.
Метод unique() не подсчитывает количество элементов. Для анализа распределения значений лучше использовать value_counts() после получения уникальных данных, если требуется определить частоту каждого элемента.
Применение value_counts для подсчета уникальных значений
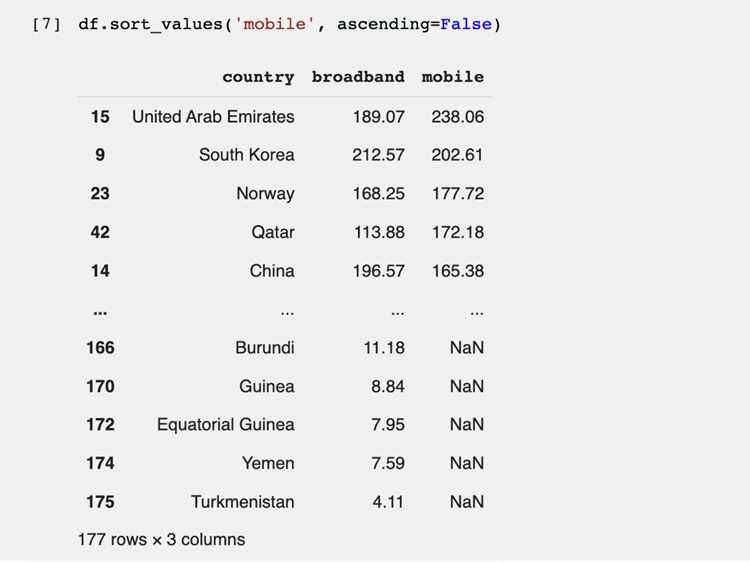
Метод value_counts() возвращает Series, где индексы – уникальные значения столбца, а значения – количество их появлений. Пример: df[‘column_name’].value_counts() покажет распределение категорий или числовых значений.
По умолчанию результаты сортируются по убыванию частоты. Для сортировки по индексам используется параметр sort_index=True. Для включения пропущенных значений (NaN) добавляется dropna=False.
Результаты можно представить в виде таблицы для наглядного анализа:
| Значение | Количество |
|---|---|
| Apple | 15 |
| Banana | 8 |
| Orange | 12 |
| NaN | 2 |
Для дальнейшей обработки результаты value_counts() можно преобразовать в DataFrame через reset_index(), что позволяет использовать их в объединениях, фильтрации и визуализациях.
Получение уникальных значений нескольких столбцов сразу
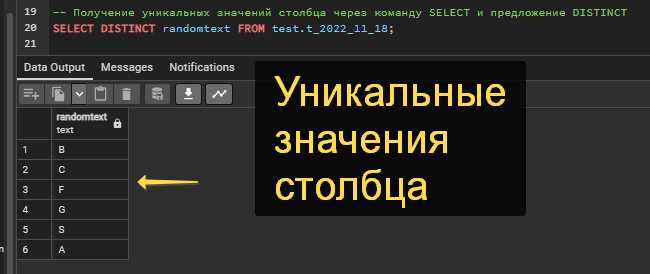
Для анализа комбинаций значений в нескольких столбцах используется метод drop_duplicates(). Он возвращает DataFrame с уникальными строками по указанным колонкам.
Пример: df[[‘column1’, ‘column2’]].drop_duplicates() создаст набор уникальных пар значений, игнорируя дубли.
Рекомендации по использованию:
- Для включения всех столбцов достаточно вызвать df.drop_duplicates() без указания колонок.
- Чтобы сохранить порядок строк, используйте keep=’first’ или keep=’last’, что оставляет первую или последнюю встречающуюся комбинацию.
- Для удаления пропущенных значений применяйте dropna() перед вызовом drop_duplicates().
Полученные уникальные комбинации можно преобразовать в список словарей для удобного обхода в циклах:
- Вызвать drop_duplicates() на выбранных столбцах.
- Использовать to_dict(‘records’) для конвертации DataFrame в список словарей.
- Обрабатывать данные в цикле или передавать в функции для анализа.
Перед получением уникальных значений часто требуется исключить ненужные строки. Для этого применяются логические условия или метод query(). Например, df[df[‘column’] > 10][‘column’].unique() вернет уникальные значения, превышающие 10.
Для фильтрации категориальных данных удобно использовать оператор isin(). Пример: df[df[‘column’].isin([‘A’,’B’])][‘column’].unique() покажет уникальные значения только из выбранного списка.
Пропущенные значения (NaN) можно удалить с помощью dropna(): df[‘column’].dropna().unique(). Это предотвращает включение пустых элементов в массив уникальных значений.
Комбинация фильтров позволяет учитывать несколько условий одновременно. Например:
df[(df[‘column1’] > 5) & (df[‘column2’] == ‘X’)][‘column1’].unique() – возвращает уникальные значения первого столбца для строк, где второй столбец равен ‘X’ и первый больше 5.
Сортировка и преобразование уникальных значений в список

После получения уникальных значений с помощью unique() или drop_duplicates() часто требуется упорядочить их. Для этого используется метод sort() для массивов numpy или sort_values() для Series. Пример: np.sort(df[‘column’].unique()) вернет массив отсортированных элементов.
Для преобразования результата в список применяется tolist(). Пример: sorted(df[‘column’].unique()).tolist() создаст отсортированный список уникальных значений, готовый для обхода в циклах или передачи в функции.
Сортировка полезна при построении графиков или создании фильтров, где важен упорядоченный набор категорий. Она также упрощает сравнение данных между разными столбцами или таблицами.
Если необходимо сохранить исходный порядок появления элементов, достаточно вызвать df[‘column’].unique().tolist() без сортировки. Это позволяет анализировать последовательность появления значений.
Обработка пропущенных значений при получении уникальных данных
В столбцах pandas пропущенные значения обозначаются NaN. При вызове unique() они включаются в результат, что может искажать анализ. Для исключения NaN используется dropna(): df[‘column’].dropna().unique().
Метод value_counts() по умолчанию игнорирует NaN. Для их учета добавляется параметр dropna=False: df[‘column’].value_counts(dropna=False), что позволяет видеть частоту пропущенных элементов вместе с уникальными значениями.
При фильтрации нескольких столбцов пропуски можно удалить через комбинацию dropna(subset=[…]). Например: df.dropna(subset=[‘column1′,’column2’]).drop_duplicates() возвращает уникальные комбинации без пустых значений.
Для последующей замены NaN на конкретные значения применяется fillna(). Пример: df[‘column’].fillna(‘Unknown’).unique() – все пропуски заменяются на ‘Unknown’ перед анализом уникальных данных.
Вопрос-ответ:
Как вывести все уникальные значения одного столбца в pandas?
Для получения уникальных значений столбца используется метод unique(). Пример: df[‘column_name’].unique() возвращает массив numpy с неповторяющимися элементами. Если необходимо исключить пропуски, примените dropna(): df[‘column_name’].dropna().unique(). Результат можно преобразовать в список через tolist() для дальнейшей обработки.
Чем отличается unique() от value_counts() при работе с уникальными значениями?
Метод unique() возвращает только список уникальных элементов без подсчета их количества, сохраняя порядок появления. value_counts() возвращает Series, где индексы — уникальные значения, а значения — количество их повторов. Например, df[‘column’].value_counts() покажет, сколько раз встречается каждый элемент, включая возможность учета пропущенных значений через dropna=False.
Как получить уникальные комбинации значений нескольких столбцов одновременно?
Используется метод drop_duplicates() на выбранных столбцах: df[[‘column1′,’column2’]].drop_duplicates(). Он возвращает DataFrame с неповторяющимися комбинациями. Для удаления пропусков перед анализом применяется dropna(subset=[‘column1′,’column2’]), а параметр keep=’first’ позволяет сохранить первую встречающуюся строку из повторяющихся комбинаций.
Как фильтровать данные перед получением уникальных значений?
Для фильтрации используются логические условия или метод query(). Например, df[df[‘column’] > 10][‘column’].unique() вернет уникальные значения больше 10. Для категорий удобно применять isin(): df[df[‘column’].isin([‘A’,’B’])][‘column’].unique(). Такая фильтрация позволяет исключить лишние строки и получить точный набор уникальных данных.
Как обработать пропущенные значения при анализе уникальных данных?
Пропуски обозначаются NaN и включаются в массив уникальных значений при использовании unique(). Чтобы их исключить, применяют dropna(): df[‘column’].dropna().unique(). Для учета пропусков при подсчете частоты используется value_counts(dropna=False). Также можно заменить NaN на конкретные значения через fillna(), например: df[‘column’].fillna(‘Unknown’).unique().
Как получить уникальные значения столбца с пропущенными данными в pandas?
Метод unique() возвращает все неповторяющиеся элементы столбца, включая NaN. Чтобы исключить пропуски, используют dropna(): df[‘column’].dropna().unique(). Если требуется учитывать пропуски при подсчете частоты, применяется value_counts(dropna=False), что позволяет видеть, сколько строк содержат пустые значения.
Можно ли получить уникальные комбинации значений сразу из нескольких столбцов?
Да, для этого используют drop_duplicates() с указанием нужных колонок. Пример: df[[‘column1′,’column2’]].drop_duplicates() возвращает DataFrame с уникальными парами значений. Для удаления строк с пропусками применяется dropna(subset=[‘column1′,’column2’]). Параметр keep=’first’ позволяет оставить первую встречающуюся комбинацию, если она повторяется.