Содержание статьи

Фильтрация списков в Python позволяет отбирать только те элементы, которые соответствуют заданным условиям. Встроенная функция filter() и генераторы списков (list comprehensions) дают возможность создавать новые списки без изменения исходных данных. Такой подход помогает быстро обрабатывать большие наборы данных и снижает количество лишнего кода.
Примеры кода показывают, как использовать логические условия, встроенные функции и лямбда-выражения для фильтрации чисел, строк и объектов. Например, с помощью filter() можно выбрать только четные числа из списка, а генератор списков позволяет сразу создать новый список с элементами, удовлетворяющими нескольким условиям одновременно.
Важным аспектом является возможность комбинировать условия фильтрации для сложных структур данных. Это удобно при работе с файлами, API или базами данных, когда требуется выбрать конкретные элементы из множества объектов по нескольким критериям. Практическая работа с фильтрацией списков ускоряет обработку данных и повышает читаемость кода.
В статье представлены конкретные методы фильтрации, пошаговые примеры и рекомендации по их применению для различных типов данных. Использование этих подходов сокращает количество ошибок и упрощает написание скриптов, которые обрабатывают списки в Python.
Использование функции filter() для отбора элементов
Пример отбора четных чисел из списка:
numbers = [1, 2, 3, 4, 5, 6]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # [2, 4, 6]
Здесь лямбда-функция проверяет делимость на 2 и исключает все нечетные элементы.
Фильтрация строк возможна через предикаты, проверяющие длину или наличие подстроки. Например, выбрать слова длиной более 4 символов:
words = [‘apple’, ‘dog’, ‘banana’, ‘cat’]
long_words = list(filter(lambda w: len(w) > 4, words))
print(long_words) # [‘apple’, ‘banana’]
Для повышения читаемости можно использовать обычные функции вместо лямбда-выражений. Это упрощает отладку и повторное использование логики фильтрации. Например, функция def is_positive(x): return x > 0 позволяет фильтровать только положительные числа, сохраняя код структурированным и понятным.
Функция filter() удобна для последовательной обработки данных, особенно когда нужно применять одну и ту же проверку к разным спискам. Комбинирование с другими встроенными функциями Python, такими как map() или sorted(), расширяет возможности фильтрации без создания промежуточных циклов.
Фильтрация списков через генераторы списков (list comprehensions)
Генераторы списков позволяют создавать новые списки, применяя условие фильтрации к каждому элементу исходного списка в одной строке. Формат записи: [выражение for элемент in список if условие]. Это сокращает количество кода и исключает необходимость использования filter().
Пример фильтрации чисел больше 10:
| numbers = [5, 12, 7, 20, 3] |
| filtered = [x for x in numbers if x > 10] |
| print(filtered) # [12, 20] |
Для строковых данных можно использовать любые условия, включая проверку подстроки или длину слова. Например, выбрать слова, содержащие букву ‘a’:
| words = [‘apple’, ‘banana’, ‘kiwi’, ‘grape’] |
| contains_a = [w for w in words if ‘a’ in w] |
| print(contains_a) # [‘apple’, ‘banana’, ‘grape’] |
Генераторы списков удобны при комбинировании нескольких условий. Например, выбрать числа больше 5 и четные одновременно:
| numbers = [2, 4, 6, 7, 8, 10] |
| filtered = [x for x in numbers if x > 5 and x % 2 == 0] |
| print(filtered) # [6, 8, 10] |
Использование генераторов списков сокращает время обработки данных и повышает читаемость кода, особенно при работе с небольшими и средними наборами элементов, где важно быстро применять фильтры без создания дополнительных функций.
Применение лямбда-функций при фильтрации

Лямбда-функции позволяют определять короткие анонимные функции прямо в месте вызова фильтрации. Они удобны для одноразовых проверок без необходимости создавать отдельные именованные функции.
Пример фильтрации положительных чисел из списка с помощью filter() и лямбда-функции:
numbers = [-3, 5, 0, -1, 8]
positive = list(filter(lambda x: x > 0, numbers))
print(positive) # [5, 8]
Лямбда-функции можно комбинировать с генераторами списков для более сложных условий. Например, выбрать числа, которые больше 5 и делятся на 3:
numbers = [2, 3, 6, 9, 12]
filtered = [x for x in numbers if (lambda y: y > 5 and y % 3 == 0)(x)]
print(filtered) # [6, 9, 12]
Использование лямбда-функций повышает компактность кода и позволяет быстро применять специфические условия фильтрации без создания вспомогательных функций. Рекомендуется использовать их для коротких выражений, когда предикат не требует повторного использования.
Удаление элементов по условию с помощью циклов
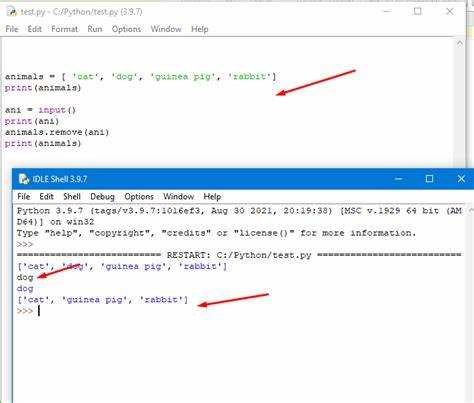
Удаление элементов из списка по условию можно выполнить через стандартный цикл for с использованием метода remove() или созданием нового списка. Прямое удаление внутри цикла требует аккуратности, чтобы избежать пропуска элементов.
Пример удаления отрицательных чисел через создание нового списка:
numbers = [4, -2, 7, -5, 0]
filtered = []
for x in numbers:
if x >= 0:
filtered.append(x)
print(filtered) # [4, 7, 0]
Прямое удаление с использованием remove() требует обхода копии списка, чтобы избежать ошибок при изменении исходного списка во время итерации:
numbers = [4, -2, 7, -5, 0]
for x in numbers[:]:
if x < 0:
numbers.remove(x)
print(numbers) # [4, 7, 0]
Циклы позволяют использовать сложные условия фильтрации, включая проверку нескольких параметров или работу с вложенными структурами. Такой подход полезен, когда требуется гибкая обработка списка без использования встроенных функций фильтрации.
Фильтрация числовых списков с помощью встроенных функций
Python предоставляет ряд встроенных функций, которые помогают фильтровать числовые списки без написания дополнительных предикатов. Функции min(), max(), sum() и abs() позволяют выбирать элементы по конкретным критериям или вычислять показатели для последующей фильтрации.
Пример фильтрации чисел выше среднего значения списка:
numbers = [4, 10, 7, 3, 8]
average = sum(numbers) / len(numbers)
filtered = [x for x in numbers if x > average]
print(filtered) # [10, 7, 8]
Функция abs() полезна для отбора элементов по модулю. Например, выбрать числа с абсолютным значением меньше 5:
numbers = [-7, -3, 2, 6, 0]
filtered = [x for x in numbers if abs(x) < 5]
print(filtered) # [-3, 2, 0]
Для диапазонов чисел удобно использовать встроенные функции range() и проверку попадания в интервал. Например, выбрать числа от 5 до 15 включительно:
numbers = [2, 5, 10, 17, 12]
filtered = [x for x in numbers if 5 <= x <= 15]
print(filtered) # [5, 10, 12]
Использование встроенных функций сокращает количество кода и упрощает фильтрацию без создания дополнительных функций или сложных предикатов, особенно при работе с числовыми данными.
Работа с фильтрацией строк и текстовых данных

Фильтрация строк позволяет отбирать элементы списка по содержимому, длине или наличию определённых символов. В Python это удобно реализовать через генераторы списков и встроенные методы строк.
Примеры условий фильтрации:
- Проверка длины слова: [w for w in words if len(w) > 4]
- Наличие подстроки: [w for w in words if ‘a’ in w]
- Начало или конец слова: [w for w in words if w.startswith(‘p’)]
- Проверка регистра: [w for w in words if w.isupper()]
Пример фильтрации списка слов по длине и наличию подстроки одновременно:
- words = [‘apple’, ‘dog’, ‘banana’, ‘cat’, ‘grape’]
- filtered = [w for w in words if len(w) > 3 and ‘a’ in w]
- print(filtered) # [‘apple’, ‘banana’, ‘grape’]
Методы строк startswith(), endswith(), isalpha() и isdigit() позволяют фильтровать текстовые данные по формату и содержимому. Их можно комбинировать с условиями для сложной фильтрации.
Использование генераторов списков с методами строк повышает читаемость кода и позволяет быстро создавать новые списки, удовлетворяющие конкретным требованиям без использования дополнительных циклов.
Комбинирование нескольких условий для отбора элементов
Фильтрация по нескольким условиям позволяет создавать более точные списки, отбирая элементы, которые удовлетворяют сразу нескольким критериям. В Python это реализуется через логические операторы and, or и not внутри генераторов списков или предикатов для filter().
Пример отбора чисел, которые больше 5 и делятся на 2:
numbers = [2, 4, 6, 7, 8, 10]
filtered = [x for x in numbers if x > 5 and x % 2 == 0]
print(filtered) # [6, 8, 10]
Можно комбинировать условия для строк, например, выбрать слова длиной более 3 символов, содержащие букву ‘a’:
words = [‘apple’, ‘dog’, ‘banana’, ‘cat’, ‘kiwi’]
filtered = [w for w in words if len(w) > 3 and ‘a’ in w]
print(filtered) # [‘apple’, ‘banana’]
Для более сложной фильтрации используются вложенные условия и функции. Например, выбрать положительные числа, кратные 3, но не кратные 5:
numbers = [3, 5, 6, 9, 10, 15]
filtered = [x for x in numbers if x > 0 and x % 3 == 0 and x % 5 != 0]
print(filtered) # [3, 6, 9]
Комбинирование условий позволяет точно контролировать отбор элементов и создавать списки, которые соответствуют сложным критериям без использования множества отдельных фильтров.
Вопрос-ответ:
Как использовать функцию filter() для отбора элементов из списка чисел?
Функция filter() принимает два аргумента: функцию-предикат и список. Предикат возвращает True для элементов, которые нужно оставить. Например, чтобы выбрать четные числа из списка numbers = [1, 2, 3, 4, 5, 6], можно написать: even_numbers = list(filter(lambda x: x % 2 == 0, numbers)). Результат будет [2, 4, 6].
В чем отличие фильтрации через генераторы списков от использования filter()?
Генераторы списков позволяют отбирать элементы и одновременно создавать новый список в одной строке, используя синтаксис [выражение for элемент in список if условие]. В отличие от filter(), они дают больше гибкости для комбинирования условий и работы с выражениями, не требуя преобразования результата в список.
Как фильтровать строки по длине и наличию определенной подстроки?
Для фильтрации строк можно использовать генераторы списков с методами строк. Например, чтобы выбрать слова длиной больше 4 символов, содержащие букву ‘a’: filtered = [w for w in words if len(w) > 4 and ‘a’ in w]. Если words = [‘apple’, ‘dog’, ‘banana’, ‘cat’], результат будет [‘apple’, ‘banana’].
Можно ли использовать несколько условий одновременно при фильтрации числового списка?
Да, можно использовать логические операторы and, or, not для комбинирования условий. Например, чтобы выбрать положительные числа, кратные 3, но не кратные 5: filtered = [x for x in numbers if x > 0 and x % 3 == 0 and x % 5 != 0]. Такой подход позволяет гибко отбирать элементы по сложным критериям.
Когда удобнее использовать циклы для удаления элементов по условию вместо встроенных функций?
Циклы подходят, когда условия фильтрации сложные или зависят от нескольких параметров, особенно при работе с вложенными списками. Для безопасного удаления элементов лучше обходить копию списка, например: for x in numbers[:]: if x < 0: numbers.remove(x). Это предотвращает пропуск элементов при изменении исходного списка.
Как выбрать из списка только уникальные числа, превышающие определённое значение?
Для фильтрации уникальных чисел сначала можно преобразовать список в множество с помощью set(), чтобы удалить повторения. Затем применяют генератор списков или filter() для отбора элементов, превышающих нужное значение. Например, numbers = [2, 5, 7, 5, 10, 2], минимальное значение 5: filtered = [x for x in set(numbers) if x > 5]. Результат будет [7, 10]. Такой подход позволяет одновременно исключить дубликаты и выбрать только элементы, удовлетворяющие условию.