UTF-32 – это формат кодирования Unicode, в котором каждому символу всегда выделяется 4 байта. Независимо от того, используется ли латинская буква, кириллический символ, иероглиф или эмодзи, размер одной кодовой единицы остаётся неизменным – 32 бита.
Такой подход исключает переменную длину символов, характерную для UTF-8 и UTF-16. В UTF-32 один символ равен одному числу, что упрощает индексирование строк, подсчёт длины текста и работу с отдельными позициями символов в памяти.
Фиксированный размер напрямую влияет на объём данных. Строка из 100 символов в UTF-32 всегда занимает 400 байт без учёта служебных данных. Для текстов, содержащих в основном символы ASCII, это приводит к заметному перерасходу памяти по сравнению с UTF-8.
UTF-32 применяется редко и обычно ограничивается внутренними структурами программ, где важна прямая адресация символов по смещению. Для хранения файлов, передачи данных по сети и работы с пользовательским вводом такой формат выбирают только при наличии чётких технических причин.
UTF-32: сколько байт занимает один символ
В кодировке UTF-32 каждый символ занимает ровно 4 байта, что соответствует 32 битам. Это правило действует для всех кодовых точек Unicode без исключений, включая базовую латиницу, кириллицу, иероглифы и символы эмодзи.
Один символ в UTF-32 хранится как одно целое число, значение которого совпадает с кодовой точкой Unicode. Например, символ A имеет код U+0041 и в UTF-32 записывается как 0x00000041, а символ 😀 (U+1F600) – как 0x0001F600.
Отсутствие переменной длины упрощает вычисления. Смещение n-го символа в строке определяется формулой n × 4 байта, без анализа предыдущих данных. Это снижает сложность операций индексации и доступа к отдельным символам.
Фиксированный размер приводит к увеличению объёма данных. Текст из 1 000 символов всегда занимает 4 000 байт, даже если используются только символы ASCII. При работе с большими текстовыми массивами это увеличивает потребление памяти и нагрузку на кэш.
UTF-32 имеет смысл использовать в задачах, где критична прямая адресация символов и предсказуемый размер данных. Для хранения текстов и обмена данными обычно выбирают UTF-8 или UTF-16, где количество байт на символ может быть меньше.
Фиксированный размер кодовой единицы UTF-32

В UTF-32 кодовая единица всегда имеет размер 4 байта. Каждая такая единица соответствует одной кодовой точке Unicode и не зависит от диапазона значений символа. Дополнительные байты или составные последовательности отсутствуют.
Фиксированная длина устраняет различие между кодовой единицей и символом. В UTF-32 эти понятия совпадают, что исключает необходимость обработки суррогатных пар или многобайтовых последовательностей при работе со строками.
Порядок байтов определяется вариантом представления: UTF-32LE или UTF-32BE. В первом случае младший байт располагается первым, во втором – старший. На количество байт это не влияет, но учитывается при чтении бинарных данных и взаимодействии между системами.
При хранении данных в памяти фиксированный размер упрощает расчёт смещений и позволяет обращаться к любому символу за постоянное число операций. Это полезно при реализации парсеров, интерпретаторов и низкоуровневых текстовых структур.
Для файлов и сетевых протоколов фиксированная кодовая единица приводит к увеличению объёма данных. Использование UTF-32 оправдано только при контролируемом окружении, где размер текста предсказуем и не критичен.
Сколько байт выделяется на символ Unicode в UTF-32

В UTF-32 на каждый символ Unicode выделяется ровно 4 байта. Это правило применяется ко всем кодовым точкам диапазона U+0000–U+10FFFF без каких-либо исключений или специальных случаев.
Независимо от категории символа, объём памяти остаётся одинаковым:
- латинские буквы и цифры – 4 байта
- кириллица и другие алфавиты – 4 байта
- иероглифы CJK – 4 байта
- математические знаки и спецсимволы – 4 байта
- эмодзи и символы вне BMP – 4 байта
Каждый символ хранится как одно 32-битное значение, равное его кодовой точке Unicode. Например, символ «Ж» (U+0416) занимает 4 байта, как и эмодзи «🚀» (U+1F680), несмотря на разницу в числовом диапазоне.
Общий размер строки рассчитывается прямым умножением:
- количество символов × 4 байта
- служебные данные строки учитываются отдельно
Такой расчёт полезен при работе с буферами, бинарными форматами и интерфейсами низкого уровня. Для текстовых файлов и обмена данными по сети UTF-32 выбирают только при заранее известном объёме текста и отсутствии строгих ограничений по размеру.
Как хранятся символы BMP и вне BMP в UTF-32

В UTF-32 символы из плоскости BMP (U+0000–U+FFFF) и символы вне BMP (U+10000–U+10FFFF) хранятся одинаковым способом. Каждый символ представлен одним 32-битным значением, без разделения на части и без дополнительных служебных кодов.
Для символов BMP используется полный 32-битный слот, хотя фактически задействуются только младшие 16 бит. Например, символ «Я» с кодовой точкой U+042F в UTF-32 записывается как 0x0000042F, при этом старшие байты заполняются нулями.
Символы вне BMP, включая эмодзи и редкие иероглифы, также занимают 4 байта. Кодовая точка U+1F4A9 хранится напрямую как 0x0001F4A9, без суррогатных пар, которые применяются в UTF-16.
Отсутствие различий в хранении упрощает обработку строк. Проверка принадлежности символа к BMP не требуется, так как доступ к любому элементу строки осуществляется одинаково, по фиксированному смещению.
При работе с бинарными данными следует учитывать порядок байтов. Варианты UTF-32LE и UTF-32BE влияют на расположение байтов в памяти, но не меняют объём данных и принцип хранения символов.
Влияние UTF-32 на размер текста и файлов

UTF-32 увеличивает объём текста по сравнению с UTF-8 и UTF-16, так как каждый символ занимает 4 байта. Строка из 1 000 символов всегда занимает 4 000 байт, даже если большинство символов входят в диапазон ASCII, который в UTF-8 занимает всего 1 байт.
При хранении документов или передачи данных это приводит к значительному увеличению размера файлов. Например, текст на русском языке в UTF-32 будет примерно в 2–4 раза больше, чем в UTF-8, в зависимости от количества символов вне ASCII.
Использование UTF-32 оправдано только для внутренних структур программ, где требуется быстрый доступ к символам по смещению и точный расчёт длины строк. Для архивирования, сетевых протоколов и хранения больших текстов лучше выбирать UTF-8 или UTF-16, чтобы уменьшить расход памяти и пропускную способность.
При конвертации текстов в UTF-32 необходимо учитывать объём оперативной памяти и дискового пространства. Оптимальным решением является выбор формата кодирования исходя из типа символов и объёма текста, чтобы минимизировать избыточное использование байтов.
Сравнение количества байт на символ: UTF-32, UTF-16 и UTF-8
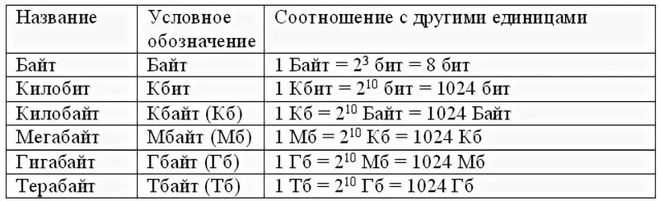
Количество байт, которое занимает один символ, сильно зависит от выбранной кодировки:
- UTF-32: всегда 4 байта на символ, независимо от диапазона Unicode.
- UTF-16: 2 байта для символов BMP (U+0000–U+FFFF) и 4 байта для символов вне BMP (используются суррогатные пары).
- UTF-8: 1 байт для ASCII (U+0000–U+007F), 2 байта для большинства европейских символов, 3 байта для большинства символов BMP и 4 байта для символов вне BMP.
Пример практического расчёта:
- Строка из 100 латинских букв:
- UTF-32 – 400 байт
- UTF-16 – 200 байт
- UTF-8 – 100 байт
- Строка из 100 эмодзи (U+1F600):
- UTF-32 – 400 байт
- UTF-16 – 400 байт (суррогатные пары)
- UTF-8 – 400 байт
Выбор кодировки зависит от характера текста и требований к объёму данных. UTF-32 обеспечивает простое и предсказуемое смещение символов, UTF-16 и UTF-8 экономят память при работе с текстами, содержащими преимущественно BMP или ASCII.
Практические случаи, где важен точный размер символа в UTF-32
Точный размер символа в UTF-32 используется в задачах, где требуется предсказуемое смещение и прямой доступ к отдельным символам без вычисления длины многобайтовых последовательностей. Это важно для обработки больших текстовых массивов и бинарных данных.
Примеры применения:
| Сценарий | Описание | Преимущество UTF-32 |
|---|---|---|
| Парсеры и интерпретаторы | Чтение символов по индексу без расчёта длины многобайтовых последовательностей | Фиксированное смещение 4 байта на символ упрощает доступ и ускоряет обработку |
| Редактирование текста в памяти | Манипуляции с отдельными символами, включая эмодзи и редкие иероглифы | Каждый символ занимает один слот, нет необходимости объединять или разделять байты |
| Сетевые протоколы и бинарные форматы | Передача данных с предсказуемым размером элементов | Упрощение расчёта объёма передаваемой информации |
| Тестирование и отладка | Контроль точного расположения символов в памяти и файлах | Лёгкая проверка и сравнение данных, исключение ошибок смещений |
Использование UTF-32 оправдано, когда важна точная адресация символов и известен объём текста. Для хранения больших объёмов данных вне внутренних структур программ чаще применяют UTF-8 или UTF-16 для экономии памяти.
Вопрос-ответ:
Почему UTF-32 всегда использует 4 байта на символ?
UTF-32 предназначен для фиксированного кодирования символов Unicode. Каждая кодовая точка представлена одним 32-битным значением, что делает размер символа постоянным. Это упрощает доступ к символам по индексу, исключая необходимость вычислять длину многобайтовых последовательностей.
Как размер символа в UTF-32 влияет на объём текста в памяти?
Поскольку каждый символ занимает 4 байта, текст, содержащий много символов ASCII или других символов BMP, будет занимать больше памяти, чем в UTF-8 или UTF-16. Например, строка из 1 000 латинских букв в UTF-32 займёт 4 000 байт, тогда как в UTF-8 она займёт только 1 000 байт.
Существуют ли отличия в хранении символов BMP и вне BMP в UTF-32?
Отличий нет. Символы BMP и вне BMP хранятся одинаково — как одно 32-битное значение. Символ вне BMP, такой как эмодзи, занимает столько же места, сколько обычная буква, что упрощает доступ и обработку текста.
В каких случаях стоит выбирать UTF-32 для работы с текстом?
UTF-32 удобен для обработки строк в памяти, когда требуется прямой доступ к символам по индексу и точный расчёт длины строк. Он позволяет быстро извлекать отдельные символы без анализа многобайтовых последовательностей, но для хранения больших текстов использование UTF-32 увеличивает объём данных.
Как правильно рассчитать размер файла с текстом в UTF-32?
Для расчёта размера достаточно умножить количество символов на 4 байта. Например, текст из 2 500 символов займёт 10 000 байт. Этот метод работает для любых символов Unicode, включая BMP и вне BMP, так как каждый символ имеет одинаковый размер.
Почему UTF-32 всегда занимает 4 байта на символ и чем это отличается от UTF-8 и UTF-16?
UTF-32 использует фиксированную длину 4 байта для каждого символа, независимо от его диапазона Unicode. В UTF-16 символы BMP занимают 2 байта, а символы вне BMP — 4 байта с помощью суррогатных пар. В UTF-8 длина символа варьируется от 1 до 4 байт в зависимости от кодовой точки. Фиксированный размер UTF-32 упрощает прямой доступ к символам по индексу и расчёт длины строк, но увеличивает объём текста в памяти и файлах по сравнению с UTF-8 и UTF-16.