Содержание статьи

Для точного анализа числовых данных в Pandas часто требуется контролировать количество знаков после запятой. Метод round() позволяет задать точность как для отдельного столбца, так и для всей таблицы, например df[‘сумма’].round(2) сохраняет два знака после запятой, что удобно при работе с финансовыми значениями.
При необходимости одновременного округления нескольких столбцов удобно использовать словарь с названием столбца и требуемой точностью: df.round({‘цена’: 2, ‘количество’: 0}). Такой подход исключает ручную обработку и ускоряет подготовку данных к визуализации или статистике.
Для нестандартного округления применяются функции NumPy: numpy.floor() округляет вниз, numpy.ceil() – вверх, а numpy.around() позволяет задать точность с любой степенью. Комбинация этих функций с apply() и лямбда-выражениями дает возможность реализовать уникальные правила округления для отдельных значений.
При работе с пропущенными данными важно учитывать, что округление не изменяет NaN. Перед расчетами рекомендуется заполнить пропуски с помощью fillna() или игнорировать их в агрегатных функциях, чтобы сохранить корректность средних, сумм и других статистических показателей.
Использование метода round() для числовых столбцов
Метод round() позволяет быстро изменить точность числовых значений в столбцах Pandas. Для одного столбца достаточно указать количество знаков после запятой: df[‘значение’].round(2) вернет значения с двумя десятичными.
Для применения к нескольким столбцам используется словарь, где ключ – имя столбца, а значение – количество знаков: df.round({‘цена’: 2, ‘количество’: 0}). Это сокращает количество кода и предотвращает ошибки при ручном округлении.
Метод возвращает новый DataFrame, поэтому если требуется изменить исходные данные, используется параметр присваивания: df[‘цена’] = df[‘цена’].round(2). Такой подход сохраняет структуру таблицы и упрощает последующую обработку.
Метод round() корректно обрабатывает отрицательные значения и NaN, оставляя пропуски без изменений. Это важно при работе с финансовыми и статистическими данными, где точность и сохранение структуры критичны.
Округление значений до целого числа
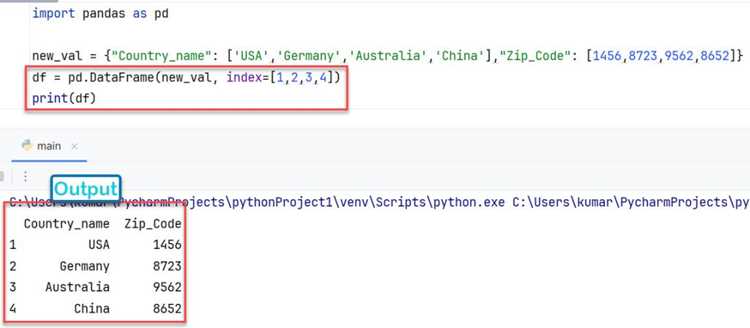
Для округления числовых столбцов до целого числа в Pandas используется метод round(0). Например, df[‘количество’].round(0) преобразует все значения столбца в целые, сохраняя при этом тип данных float, что удобно для последующих расчетов.
Если необходимо сразу получить тип int, применяется приведение: df[‘количество’] = df[‘количество’].round(0).astype(int). Такой подход упрощает работу с индексами, группировками и фильтрацией.
Метод корректно обрабатывает отрицательные числа: значения меньше нуля округляются к ближайшему целому в сторону нуля. Пропуски NaN сохраняются без изменений, что предотвращает потерю данных при агрегации.
Для быстрого применения к нескольким столбцам удобно использовать словарь: df.round({‘количество’: 0, ‘заказы’: 0}). Это сокращает код и минимизирует вероятность ошибок при ручном преобразовании каждого столбца.
Округление до заданного количества знаков после запятой
Метод round() позволяет задать точность округления до конкретного количества десятичных знаков. Например, df[‘цена’].round(3) оставляет три знака после запятой, что важно при работе с финансовыми и научными данными.
Для нескольких столбцов используется словарь с указанием точности: df.round({‘цена’: 2, ‘ставка’: 4}). Такой подход ускоряет обработку данных и предотвращает несоответствие точности между столбцами.
Если требуется сохранить исходный DataFrame без создания нового, применяют присваивание: df[‘цена’] = df[‘цена’].round(2). Это обеспечивает согласованность данных и упрощает дальнейшие вычисления.
Метод корректно работает с отрицательными числами и не изменяет NaN, что сохраняет структуру данных при вычислениях, агрегациях и визуализациях.
Применение округления к нескольким столбцам одновременно

Для одновременного округления нескольких столбцов в Pandas используется метод round() с передачей словаря, где ключ – имя столбца, а значение – количество знаков после запятой. Пример:
- df.round({‘цена’: 2, ‘количество’: 0, ‘ставка’: 4}) – округляет столбцы с разной точностью за один вызов.
Для сохранения изменений в исходном DataFrame применяется присваивание:
- df[[‘цена’, ‘количество’, ‘ставка’]] = df[[‘цена’, ‘количество’, ‘ставка’]].round({‘цена’: 2, ‘количество’: 0, ‘ставка’: 4})
Такой подход исключает необходимость обрабатывать каждый столбец отдельно и снижает риск ошибок. Метод корректно работает с NaN и отрицательными числами, сохраняя структуру данных.
Если необходимо динамически задавать столбцы и точность, можно использовать цикл по списку имен и словарь с точностью, что упрощает масштабирование для больших таблиц.
Использование numpy для кастомного округления
Библиотека NumPy предоставляет функции для гибкого округления числовых столбцов Pandas:
| Функция | Описание | Пример использования |
|---|---|---|
| numpy.around() | Округление до заданного количества десятичных знаков | df[‘цена’] = np.around(df[‘цена’], 2) |
| numpy.floor() | Округление вниз до ближайшего целого числа | df[‘количество’] = np.floor(df[‘количество’]) |
| numpy.ceil() | Округление вверх до ближайшего целого числа | df[‘заказы’] = np.ceil(df[‘заказы’]) |
Для кастомного округления с уникальными правилами можно использовать комбинацию apply() и функций NumPy. Например, округление до ближайшего четного числа реализуется через df[‘значение’] = df[‘значение’].apply(lambda x: np.round(x/2)*2). Такой подход позволяет учитывать специфические требования к данным и управлять точностью для каждого значения.
Округление с помощью функций apply() и lambda

Функция apply() позволяет применять пользовательские правила округления к каждому значению столбца. С помощью lambda можно реализовать нестандартные схемы, которые не поддерживаются методами round() или NumPy.
Пример округления до ближайшего четного числа:
df[‘значение’] = df[‘значение’].apply(lambda x: round(x/2)*2)
Для округления с учетом порога используется условие внутри lambda:
df[‘цена’] = df[‘цена’].apply(lambda x: int(x)+1 if x%1 >= 0.5 else int(x))
Такой подход дает полный контроль над процессом округления и позволяет учитывать сложные правила для отдельных значений без изменения остальных столбцов. Метод корректно обрабатывает NaN, оставляя пропуски без изменений.
Замена исходных значений округленными без создания нового столбца
Для изменения данных непосредственно в существующем столбце используется присваивание с методом round(). Например, df[‘цена’] = df[‘цена’].round(2) заменяет все значения столбца на округленные с двумя знаками после запятой.
Если требуется сразу применить округление к нескольким столбцам, используют списки и словари: df[[‘цена’,’количество’]] = df[[‘цена’,’количество’]].round({‘цена’:2,’количество’:0}). Это исключает создание промежуточных столбцов и сохраняет структуру DataFrame.
Метод корректно обрабатывает отрицательные числа и пропуски NaN, оставляя их без изменений. Такой подход упрощает последующую обработку данных, снижает объем кода и предотвращает дублирование информации.
Обработка пропущенных значений при округлении

Пропущенные значения NaN не вызывают ошибок при использовании методов округления, но их присутствие может влиять на агрегатные вычисления и визуализацию.
Рекомендованные подходы:
- Заполнение пропусков перед округлением с помощью fillna():
- df[‘цена’] = df[‘цена’].fillna(0).round(2) – заменяет NaN на ноль и округляет.
- Игнорирование пропусков при применении функций NumPy или lambda:
- df[‘количество’] = df[‘количество’].apply(lambda x: np.floor(x) if pd.notna(x) else x)
- Заполнение пропусков средним или медианой столбца:
- df[‘ставка’] = df[‘ставка’].fillna(df[‘ставка’].mean()).round(3)
Выбор метода зависит от требований к точности и особенностей анализа. Обработка NaN перед округлением обеспечивает корректность агрегатных функций и предотвращает искажения данных.
Вопрос-ответ:
Как округлить значения одного столбца до двух знаков после запятой в Pandas?
Для округления числового столбца до двух десятичных знаков используется метод round(). Например, df[‘цена’] = df[‘цена’].round(2) заменяет все значения столбца на округленные с двумя знаками после запятой, сохраняя тип данных float.
Можно ли округлять несколько столбцов с разной точностью за один шаг?
Да, метод round() принимает словарь, где ключ — название столбца, а значение — количество знаков после запятой. Пример: df.round({‘цена’: 2, ‘количество’: 0, ‘ставка’: 4}) округляет каждый столбец с указанной точностью, не создавая новых столбцов.
Как использовать NumPy для нестандартного округления в Pandas?
Функции NumPy, такие как np.floor(), np.ceil() и np.around(), позволяют контролировать направление округления и точность. Например, df[‘количество’] = np.floor(df[‘количество’]) округляет значения вниз, а df[‘цена’] = np.around(df[‘цена’], 3) оставляет три знака после запятой.
Как применить индивидуальные правила округления к значениям столбца?
Для кастомного округления используют apply() с лямбда-функцией. Например, округление до ближайшего четного числа выполняется так: df[‘значение’] = df[‘значение’].apply(lambda x: round(x/2)*2). Этот способ позволяет задавать уникальные правила для каждого значения без изменения остальных столбцов.
Как обрабатывать пропущенные значения при округлении?
Пропущенные значения NaN не вызывают ошибок при округлении, но могут влиять на расчеты. Можно использовать fillna() для замены пропусков перед округлением, например: df[‘цена’] = df[‘цена’].fillna(0).round(2), либо применять условие внутри apply(), чтобы оставлять NaN без изменений.