Содержание статьи

При работе с XML в C# часто возникает задача преобразовать данные из XmlDocument в типизированный класс. Это требуется при чтении конфигураций, обмене данными с внешними сервисами или разборе файлов, структура которых заранее известна. Использование классов вместо прямой работы с узлами XML упрощает доступ к данным и снижает количество ошибок при дальнейшем использовании.
В отличие от автоматической десериализации, прямое чтение XmlDocument даёт полный контроль над процессом: можно выбирать отдельные узлы через XPath, учитывать нестандартную структуру документа, обрабатывать отсутствующие элементы и атрибуты без исключений. Такой подход подходит для XML, который не соответствует строгой схеме или содержит избыточные данные.
На практике получение класса из XmlDocument сводится к последовательным шагам: загрузке XML, выборке нужных узлов, извлечению значений и присвоению их свойствам объекта. Особое внимание требуется при работе с вложенными элементами, коллекциями и типами данных, отличными от строки, такими как числа, даты и логические значения.
В статье разобран прикладной подход к преобразованию XML в объект C#: от чтения документа до заполнения готового класса с учётом атрибутов, вложенных структур и проверок на null. Примеры ориентированы на реальный код, который можно использовать без дополнительной адаптации.
Создание XmlDocument и загрузка XML из строки или файла

Класс XmlDocument используется для загрузки и разбора XML с произвольной структурой. Экземпляр создаётся через стандартный конструктор без параметров, после чего документ наполняется данными из файла, строки или потока. Выбор способа загрузки зависит от источника XML и условий выполнения кода.
Для чтения XML из файла применяется метод Load. Он принимает путь к файлу и сразу формирует DOM-дерево. Перед вызовом рекомендуется проверить существование файла и доступ к нему, так как метод выбрасывает исключение при ошибке чтения или некорректном формате XML.
Загрузка XML из строки выполняется через LoadXml. Этот вариант подходит для данных, полученных по сети, из базы данных или сформированных программно. Строка должна содержать корректный XML-документ с единственным корневым элементом, иначе будет выброшено исключение XmlException.
Если XML поступает из потока, например MemoryStream или FileStream, используется метод Load с передачей потока. Такой подход удобен при работе с архивами, сетевыми ответами или бинарными источниками, где нет прямого доступа к строке или файлу.
После загрузки XML важно проверить свойство DocumentElement. Оно указывает на корневой узел и используется как отправная точка для поиска элементов и заполнения класса. Отсутствие корневого элемента говорит о том, что документ пуст или загружен с ошибкой.
Для повышения устойчивости к ошибкам чтение XML обычно оборачивают в блок try-catch, отдельно обрабатывая ошибки синтаксиса и проблемы доступа к источнику. Это позволяет корректно реагировать на повреждённые данные до начала сопоставления XML с классами.
Поиск нужных узлов XmlDocument через SelectSingleNode и XPath
После загрузки XML доступ к данным выполняется через методы SelectSingleNode и SelectNodes, которые принимают XPath-выражение. Поиск обычно начинается от DocumentElement, так как абсолютные пути, начинающиеся с корня, дают предсказуемый результат при чтении данных для заполнения класса.
Метод SelectSingleNode возвращает первый найденный узел или null, если элемент отсутствует. Это удобно при получении одиночных значений, таких как идентификатор, имя или статус. Перед обращением к свойствам узла требуется проверка на null, чтобы избежать исключений.
XPath позволяет точно указать путь к элементу: через вложенность, имена узлов и фильтрацию по атрибутам. Например, выражение с условием по атрибуту помогает выбрать нужный элемент из набора однотипных узлов без дополнительной логики в коде.
Для доступа к атрибутам используется либо XPath с символом @, либо свойство Attributes найденного узла. Первый вариант удобен для чтения простых значений, второй – при необходимости проверить наличие атрибута перед получением данных.
Если XML содержит пространства имён, перед поиском требуется настроить XmlNamespaceManager и передать его в метод SelectSingleNode. Без этого XPath не найдёт элементы, даже если путь указан корректно.
При построении XPath выражений рекомендуется избегать относительных путей с двойным слэшем, если структура документа известна. Явные пути уменьшают риск выбора неверного узла и упрощают сопоставление XML с конкретными свойствами класса.
Ручное сопоставление XML-узлов со свойствами класса C

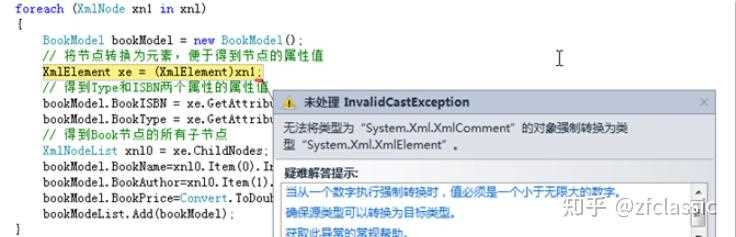
Ручное сопоставление применяется, когда структура XML не совпадает напрямую со структурой класса. В этом случае создаётся объект нужного типа, после чего его свойства заполняются значениями из узлов XmlNode, полученных через XPath.
Каждое свойство класса рекомендуется заполнять отдельно, извлекая значение через InnerText или Value. Такой подход упрощает контроль над типами данных и позволяет обрабатывать пустые узлы без выброса исключений.
Преобразование строковых значений в числовые типы, даты или логические значения следует выполнять явно с использованием int.TryParse, DateTime.TryParse и аналогичных методов. Это защищает код от некорректных данных в XML и упрощает диагностику ошибок.
Если имя XML-узла не совпадает с именем свойства класса, сопоставление выполняется вручную без попыток автоматического связывания. Такой вариант удобен при работе с внешними форматами, где наименования элементов зафиксированы и не подлежат изменению.
Для вложенных объектов сначала извлекается родительский узел, после чего создаётся отдельный экземпляр класса и заполняется его содержимое. Полученный объект присваивается соответствующему свойству основного класса.
Чтобы код оставался читаемым, логику сопоставления часто выносят в отдельный метод или конструктор, принимающий XmlNode. Это упрощает повторное использование и тестирование преобразования XML в объект.
Преобразование атрибутов XML в поля и свойства класса
Атрибуты XML считываются из объекта XmlAttributeCollection, доступного через свойство Attributes узла. Перед получением значения необходимо проверить наличие нужного атрибута, так как обращение к несуществующему элементу возвращает null.
Для извлечения данных используется свойство Value атрибута. Полученное строковое значение присваивается полю или свойству класса напрямую либо с предварительным преобразованием типа, если свойство не является строковым.
Числовые и логические значения из атрибутов следует преобразовывать через методы TryParse, чтобы корректно обработать пустые или некорректные данные. Это особенно актуально для XML, поступающего из внешних источников.
Если атрибут является необязательным, для свойства класса заранее задаётся значение по умолчанию. При наличии атрибута это значение переопределяется, при отсутствии объект остаётся в корректном состоянии.
При большом количестве атрибутов удобно использовать вспомогательные методы, принимающие имя атрибута и возвращающие типизированное значение. Такой подход сокращает дублирование кода и упрощает сопровождение логики заполнения класса.
Работа с вложенными элементами и коллекциями при заполнении класса
Вложенные элементы XML обычно соответствуют составным свойствам класса или спискам объектов. Для начала извлекается родительский узел, внутри которого выполняется поиск дочерних элементов через SelectNodes. Каждый найденный узел обрабатывается отдельно.
При заполнении коллекций создаётся список нужного типа, после чего выполняется перебор узлов XmlNodeList. Для каждого элемента создаётся новый объект класса, его свойства заполняются значениями из XML, затем объект добавляется в коллекцию.
Если вложенный элемент представлен одиночным узлом, а не набором, логика аналогична, но без цикла. Такой узел используется как источник данных для отдельного объекта, который присваивается свойству основного класса.
При работе с глубокой вложенностью рекомендуется строго придерживаться структуры XML и не использовать относительные XPath-выражения. Это снижает риск чтения данных из неверного уровня документа.
| Структура XML | Тип свойства класса | Подход к обработке |
|---|---|---|
| Одиночный вложенный элемент | Класс | Создание объекта и заполнение из одного XmlNode |
| Повторяющиеся элементы | List<T> | Перебор XmlNodeList и добавление объектов в список |
| Многоуровневая вложенность | Классы с вложенными свойствами | Последовательная обработка каждого уровня XML |
После заполнения всех вложенных объектов и коллекций рекомендуется проверить их на null и пустые списки, чтобы дальнейшая работа с классом не требовала дополнительных проверок.
Обработка отсутствующих узлов и значений по умолчанию
При сопоставлении XML с классом часто встречаются отсутствующие узлы или атрибуты. Для корректного заполнения свойств рекомендуется проверять результат методов SelectSingleNode и Attributes на null перед присвоением значения.
Если узел отсутствует, свойство класса можно оставить с заранее установленным значением по умолчанию. Для числовых и логических типов это обычно 0 или false, для строк – пустая строка. Такой подход предотвращает выброс исключений и сохраняет консистентность объекта.
Для атрибутов применяется аналогичная проверка: сначала выполняется поиск атрибута по имени, затем, только если атрибут найден, извлекается его Value и преобразуется в нужный тип. При отсутствии атрибута свойство остаётся без изменений или получает значение по умолчанию.
Если отсутствующие узлы критичны для логики работы программы, стоит использовать логирование или выбрасывать исключение с подробным описанием проблемы. Это помогает выявлять ошибки в исходных данных и предотвращает некорректное заполнение объектов.
При работе с коллекциями и вложенными объектами отсутствие элементов обрабатывается созданием пустых списков или объектов с минимальными значениями. Это обеспечивает одинаковую структуру класса независимо от наличия данных в XML.
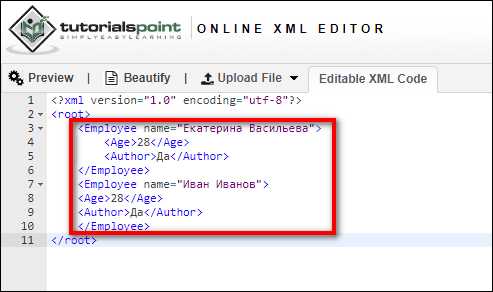
Пример готового класса и заполнения данных из XmlDocument
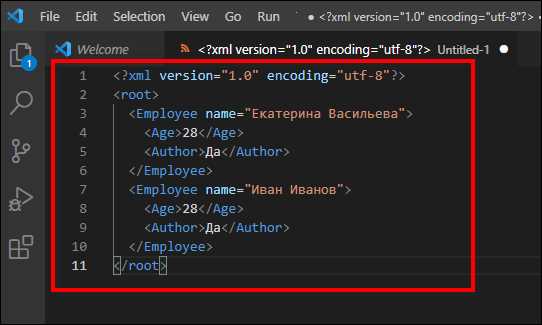
Для демонстрации сопоставления XML с классом создадим простой класс Product с полями и свойствами:
- Id – числовой идентификатор
- Name – название продукта
- Price – стоимость
- Tags – список тегов
Заполнение класса выполняется в несколько шагов:
- Создать объект XmlDocument и загрузить XML через Load или LoadXml.
- Извлечь основной узел продукта через SelectSingleNode с указанием XPath к элементу Product.
- Присвоить значения свойствам класса, проверяя наличие узлов и атрибутов:
- Id – преобразование текста узла в int через int.TryParse
- Name – присвоение InnerText узла
- Price – преобразование текста узла в decimal через decimal.TryParse
- Tags – перебор узлов Tag внутри элемента Tags и добавление в список
- Проверить отсутствие критичных узлов и задать значения по умолчанию для отсутствующих данных.
Результат – полностью заполненный объект Product, готовый к использованию в коде без дальнейших преобразований.
Вопрос-ответ:
Как создать XmlDocument и загрузить XML из файла или строки?
Для работы с XML в C# создайте экземпляр класса XmlDocument. Для загрузки из файла используйте метод Load, передав путь к файлу. Для загрузки из строки применяйте LoadXml. В обоих случаях XML преобразуется в DOM-дерево, с которым можно работать через узлы и атрибуты. Перед загрузкой файла проверьте его существование и корректность данных, чтобы избежать исключений.
Как выбрать конкретный элемент или атрибут в XmlDocument?
Выбор узлов выполняется через метод SelectSingleNode для одного узла или SelectNodes для множества узлов. XPath-выражение указывает путь к элементу, включая вложенность и фильтры по атрибутам. Если XML использует пространства имён, нужно создать XmlNamespaceManager и передать его в метод. Атрибуты можно получать через @имя в XPath или через коллекцию Attributes узла.
Как преобразовать значения XML-узлов и атрибутов в свойства класса C?
Для каждого свойства создаётся соответствующее сопоставление с узлом или атрибутом. Значения извлекаются через InnerText для узлов и Value для атрибутов. Строковые данные присваиваются напрямую, числовые и логические значения преобразуются через TryParse, чтобы избежать исключений при некорректных данных. Для вложенных объектов создаются отдельные экземпляры класса, которые заполняются аналогично.
Как работать с вложенными элементами и списками в XML при заполнении класса?
Если XML содержит повторяющиеся элементы, создаётся список нужного типа. Сначала выбирается родительский узел, затем перебираются дочерние узлы через SelectNodes. Для каждого узла создаётся объект класса, заполняется свойствами и добавляется в список. Для одиночных вложенных элементов создаётся один объект, который присваивается соответствующему свойству класса. Глубокая вложенность обрабатывается последовательно по уровням.
Что делать, если в XML отсутствуют узлы или атрибуты, необходимые для класса?
Перед присвоением значений всегда проверяйте наличие узла или атрибута на null. Для чисел и логических значений можно задавать 0 или false по умолчанию, для строк — пустую строку. В коллекциях создаются пустые списки. Если данные критичны для работы программы, лучше зафиксировать отсутствие узла через логирование или исключение, чтобы корректно обработать проблему в коде.
Как правильно преобразовать данные из XmlDocument в объект класса C# при наличии вложенных элементов и атрибутов?
Для заполнения объекта класса данными из XmlDocument сначала создаётся экземпляр класса, затем выбираются нужные узлы через SelectSingleNode или SelectNodes с использованием XPath. Значения отдельных узлов присваиваются свойствам класса через InnerText, атрибуты — через Attributes[«имя»].Value. Для чисел и логических свойств применяется явное преобразование через TryParse. Вложенные элементы обрабатываются отдельно: создаются новые объекты или списки объектов, которые заполняются аналогично, после чего присваиваются соответствующим свойствам основного класса. Перед присвоением всегда проверяется наличие узлов и атрибутов, чтобы избежать ошибок при отсутствии данных.