Содержание статьи

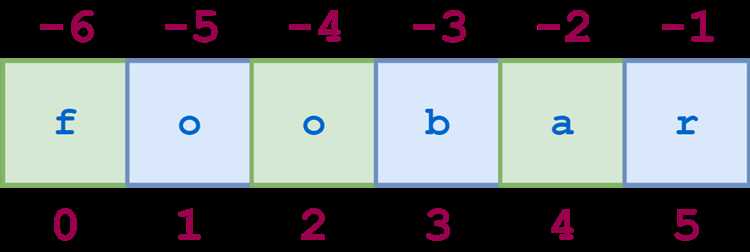
Срез строки в Python позволяет извлекать конкретные части текста без создания дополнительных переменных или сложных конструкций. Операция использует синтаксис str[start:stop:step], где start указывает начальный индекс, stop – конечный, а step задаёт шаг. Например, строка длиной 10 символов может быть обрезана с третьего по седьмой символ включительно с помощью выражения my_string[2:7].
При работе с срезами важно учитывать отрицательные индексы, которые позволяют считать позиции с конца строки. Это полезно, когда необходимо получить последние символы или удалить завершающие символы без вычисления длины строки. Например, my_string[-4:-1] вернёт три предпоследних символа.
Шаг среза помогает пропускать символы или переворачивать строку. С выражением my_string[::2] вы получите каждый второй символ, а my_string[::-1] полностью перевернёт строку. Такие подходы ускоряют обработку текстовых данных и позволяют создавать компактные решения для анализа строк.
Срезы удобно комбинировать с методами строк для удаления пробелов, замены символов или проверки подстрок. Например, my_string.strip()[2:10] сначала удалит пробелы, а затем извлечёт нужный диапазон символов. Это позволяет избегать лишних промежуточных операций и упрощает код.
Использование срезов особенно полезно при работе с логами, CSV-файлами и длинными текстами, где требуется быстро извлечь определённые сегменты. Практика с конкретными индексами и шагами помогает лучше понимать структуру строки и ускоряет разработку скриптов для обработки данных.
Создание простого среза по индексам
Простой срез строки в Python создаётся с помощью синтаксиса str[start:stop]. Параметр start указывает индекс первого символа, который включается в срез, а stop – индекс, до которого берутся символы, не включая его. Например, text[1:5] извлечёт символы со второго по пятый.
Если start пропущен, Python автоматически начнёт срез с нулевого индекса. Выражение text[:4] вернёт первые четыре символа строки. Аналогично, если stop не указан, срез продолжается до конца строки: text[3:] даст все символы, начиная с четвёртого.
Использование индексов в пределах длины строки предотвращает ошибки IndexError. Для динамических данных рекомендуется проверять длину строки с помощью len(text), чтобы корректно задавать start и stop при создании срезов.
Простые срезы позволяют извлекать подстроки для анализа данных, преобразования форматов или подготовки текста к дальнейшей обработке. Например, text[2:8] удобно использовать для выделения кода или даты из строки фиксированной структуры.
Использование отрицательных индексов для среза
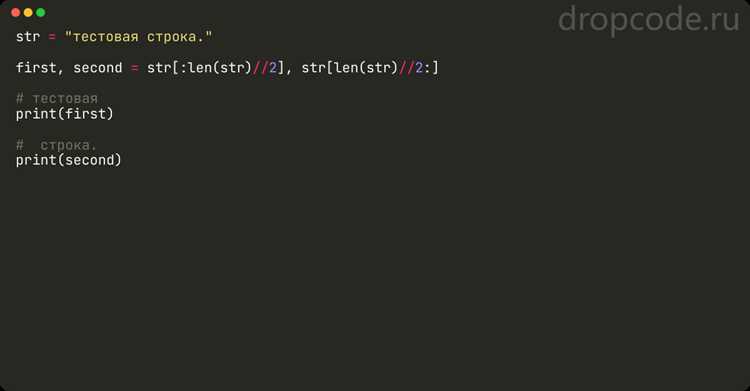
Отрицательные индексы в Python позволяют считать позиции символов с конца строки. Например, text[-1] возвращает последний символ, text[-3] – третий с конца. Это удобно для извлечения данных, когда длина строки заранее неизвестна.
С отрицательными индексами можно создавать срезы: text[-5:-1] вернёт четыре символа, начиная с пятого с конца до предпоследнего. Такой подход сокращает вычисления длины строки и упрощает обработку динамических данных.
Если start отрицательный, а stop пропущен, срез продолжается до конца строки: text[-4:] извлечёт последние четыре символа. Аналогично, text[:-3] вернёт все символы кроме трёх последних.
Отрицательные индексы полезны для извлечения окончаний строк с фиксированной структурой, таких как расширения файлов, коды, последние цифры или символы в логах. Их сочетание с простыми срезами позволяет создавать компактные и наглядные выражения.
Пропуск символов с шагом при срезе

В Python можно задать шаг среза с помощью третьего параметра синтаксиса str[start:stop:step]. Положительный шаг пропускает символы вперед: text[0:10:2] извлечёт каждый второй символ с нулевого по девятый индекс.
Отрицательный шаг позволяет получать символы в обратном порядке. Например, text[10:0:-1] вернёт символы с десятого по первый в обратном порядке. Полностью развернуть строку можно с помощью text[::-1].
Комбинация шагов и отрицательных индексов облегчает извлечение подстрок с регулярным пропуском символов, например, для выборки каждого третьего символа с конца: text[-1:-10:-3].
Использование шага упрощает преобразование форматов текста, подготовку данных для анализа или генерацию шаблонов без дополнительных циклов. Это снижает количество кода и повышает читаемость скриптов.
Извлечение подстроки до или после определённого символа
Срезы удобно использовать для получения части строки до или после конкретного символа. Для этого сначала определяют индекс символа с помощью метода find() или rfind():
- text.find(‘символ’) – возвращает индекс первого вхождения символа.
- text.rfind(‘символ’) – возвращает индекс последнего вхождения символа.
После получения индекса можно создавать срез:
- До символа: text[:index] – извлекает все символы перед указанным.
- После символа: text[index+1:] – извлекает символы, идущие после найденного.
Примеры применения:
- Выделение имени файла без расширения: filename[:filename.rfind(‘.’)].
- Получение домена из email: email[email.find(‘@’)+1:].
- Извлечение содержимого после определённого разделителя в логе: line[line.find(‘|’)+1:].
Такой подход минимизирует ошибки при работе со строками переменной длины и упрощает обработку текстовых данных.
Обрезка пробелов и лишних символов с помощью среза
Срезы позволяют удалять лишние символы с начала и конца строки без создания дополнительных переменных. Например, text[1:-1] убирает первый и последний символ, что удобно для удаления кавычек или скобок.
Для очистки пробелов можно комбинировать срез с методами строк. Выражение text.strip()[1:-1] сначала удаляет пробелы с концов, затем убирает ограничивающие символы. Это особенно полезно при обработке CSV или текстовых данных, где поля содержат пробелы или обрамляющие символы.
Если необходимо удалить фиксированное количество символов только с одной стороны, используют срез с одним индексом. Например:
- text[2:] – удаляет первые два символа.
- text[:-3] – удаляет три последних символа.
Такой подход ускоряет предварительную обработку строк, сокращает количество лишних вызовов методов и позволяет легко управлять структурой текста.
Комбинирование срезов с методами строк
Срезы становятся более гибкими при использовании вместе с методами строк. Это позволяет одновременно изменять и извлекать подстроку без создания промежуточных переменных. Например, text.strip()[2:10] удаляет пробелы и сразу извлекает нужный диапазон символов.
Ниже приведена таблица с примерами комбинаций срезов и методов строк:
| Операция | Пример | Результат |
|---|---|---|
| Удаление пробелов + срез | text.strip()[1:-1] | Строка без крайних пробелов и первого/последнего символа |
| Приведение к нижнему регистру + срез | text.lower()[0:5] | Первые пять символов в нижнем регистре |
| Замена символов + срез | text.replace(‘-‘, »)[2:8] | Извлечение подстроки без дефисов с третьего по восьмой символ |
| Удаление пробелов и приведение регистра + срез | text.strip().upper()[3:10] | Срез с четвертого по десятый символ в верхнем регистре без пробелов |
Комбинации срезов с методами строк повышают точность обработки данных и позволяют писать компактный и читаемый код, особенно при работе с логами, CSV или текстовыми файлами.
Применение срезов к динамическим строкам
Срезы особенно полезны при работе с динамическими строками, длина которых заранее неизвестна. Для таких строк удобно использовать отрицательные индексы и методы поиска символов, чтобы извлекать нужные сегменты без ошибок.
Примеры использования:
- Извлечение последних N символов: text[-N:]. Независимо от длины строки, всегда получаем последние N символов.
- Обрезка первых M символов: text[M:]. Полезно для удаления префиксов или кодов, добавленных динамически.
- Срез после определённого символа: text[text.find(‘:’)+1:]. Позволяет выделять часть строки после разделителя, даже если его позиция меняется.
Для динамических данных рекомендуется проверять длину строки перед созданием среза с помощью len(text), чтобы избежать выхода за пределы индексов. Комбинация поиска символов и срезов делает код адаптивным и упрощает обработку разнообразных текстовых данных.
Вопрос-ответ:
Как извлечь часть строки с определённого индекса по другой индекс в Python?
Для этого используется синтаксис среза str[start:stop]. Например, text[2:7] вернёт символы с третьего по седьмой включительно. Индекс start указывает, с какого символа начинать, а stop — до какого символа извлекать, не включая его.
Можно ли использовать отрицательные индексы при срезе строки?
Да, отрицательные индексы позволяют считать символы с конца строки. Например, text[-4:-1] вернёт три предпоследних символа. Это удобно, когда длина строки заранее неизвестна и нужно извлечь последние символы.
Как пропускать символы при срезе строки?
Срезы поддерживают третий параметр — шаг. Выражение text[0:10:2] извлечёт каждый второй символ с нулевого по девятый индекс. Если указать отрицательный шаг, символы будут извлекаться в обратном порядке, например text[10:0:-1].
Как получить часть строки до или после определённого символа?
Сначала находят индекс символа с помощью find() или rfind(). Чтобы извлечь подстроку до символа, используют text[:index], а после — text[index+1:]. Пример: для email email[email.find(‘@’)+1:] вернёт домен.
Можно ли комбинировать срезы с методами строк для обработки текста?
Да, методы строк можно применять до или после среза. Например, text.strip()[2:10] сначала удаляет пробелы, а затем извлекает диапазон символов. Другой вариант: text.replace(‘-‘, »)[1:8] убирает дефисы и возвращает нужные символы.