Содержание статьи

Работа с файлами – основной источник данных для визуализации: CSV с показателями продаж, XLSX с финансовыми сводками, JSON из API или TXT с логами. Для чтения таких форматов на практике используют pandas, где одна строка кода read_csv() или read_excel() формирует таблицу с типами столбцов, индексами и пропусками. Уже на этом этапе стоит проверять разделитель, кодировку (UTF-8 vs CP1251) и типы данных, чтобы числовые ряды не оказались строками.
Построение графика начинается с выбора задачи: линия для временных рядов, столбцы для сравнения категорий, точки для поиска корреляций. В matplotlib базовые конструкции plt.plot(), plt.bar() и plt.scatter() покрывают большинство сценариев. Для файлов с десятками тысяч строк полезно заранее агрегировать данные через groupby() и resample(), снижая шум и ускоряя отрисовку.
Корректная шкала и подписи – вопрос читаемости. Даты из файлов следует приводить к datetime и задавать формат оси X, числовые значения – округлять и подписывать единицы измерения. При загрузке данных с пропусками применяют dropna() или fillna() с фиксированным правилом, а не автоматически. Для сохранения результата используют plt.savefig() с DPI не ниже 150 для веба и 300 для печати.
Автоматизация упрощает повторяемость: один и тот же скрипт читает обновлённый файл и строит график без ручных правок. Хранение путей к файлам и параметров визуализации в конфигурации избавляет от правок кода, а проверка входных данных перед построением снижает число ошибок при смене формата или структуры таблицы.
Выбор формата файла и требований к структуре данных
Для построения графиков в Python наиболее часто используют CSV, XLSX и JSON. CSV подходит для табличных данных с фиксированными разделителями; важно проверять правильность разделителя, наличие заголовков и кодировку UTF-8 или CP1251. XLSX удобен для сложных таблиц с несколькими листами, формулами и форматированием, при этом каждая таблица должна содержать четкий заголовок столбцов и единый тип данных в колонках.
JSON используют при работе с вложенными структурами, например, временными рядами или массивами объектов. Для визуализации данные нужно привести к плоской таблице через нормализацию (json_normalize), чтобы каждая строка содержала значения всех переменных.
Структура данных критична: числовые ряды должны быть в колонках с однородными типами (int или float), даты – в формате datetime, а категории – как строки. Пропуски лучше обозначать NaN и обрабатывать до построения графика. Наличие уникальных заголовков для всех столбцов упрощает выбор осей и подписи графика.
Для больших файлов стоит избегать избыточных столбцов и вложенных структур без необходимости. Минимальная оптимизация: удалить лишние колонки, привести числовые типы к float32 или int32, чтобы ускорить чтение и визуализацию, особенно при построении динамических графиков.
Чтение данных из CSV файла с помощью pandas
Для работы с CSV-файлами используют функцию pandas.read_csv(). Основные параметры – sep для разделителя, encoding для кодировки, header для указания строки с заголовками и dtype для явного задания типов столбцов. Например, даты удобно загружать с parse_dates=['Дата'], чтобы сразу получить тип datetime.
После чтения важно проверить структуру таблицы. Для этого используют df.info() и df.head(), чтобы убедиться в корректности типов данных и отсутствии пропусков. Если требуется быстро оценить распределение значений по колонкам, полезна функция df.describe().
Пример структуры данных для графика:
| Дата | Продажи | Категория |
|---|---|---|
| 2025-01-01 | 150 | Электроника |
| 2025-01-02 | 200 | Электроника |
| 2025-01-01 | 120 | Одежда |
| 2025-01-02 | 180 | Одежда |
Для больших CSV-файлов используют chunksize, чтобы читать данные порциями, и usecols для выбора только нужных столбцов, что ускоряет обработку. Пропуски обозначают NaN и при необходимости заполняют fillna() или исключают dropna(), чтобы график строился на корректных данных.
Загрузка данных из Excel файла и выбор нужного листа
Для чтения Excel-файлов в Python применяют pandas.read_excel(). Важный параметр – sheet_name, позволяющий выбрать конкретный лист по имени или индексу. Если файл содержит несколько листов, их можно получить через pd.ExcelFile('файл.xlsx').sheet_names и выбрать нужный.
Рекомендации при работе с Excel:
- Указывать
usecolsдля загрузки только необходимых столбцов и ускорения обработки. - Задавать
dtypeдля числовых и категориальных данных, чтобы избежать автоматической конвертации строк в объект. - Использовать
skiprows, если первые строки содержат примечания или пустые значения. - Обрабатывать пропуски сразу с помощью
fillna()илиdropna().
Пример загрузки:
- Список листов:
xls = pd.ExcelFile('данные.xlsx'); xls.sheet_names - Выбор листа:
df = pd.read_excel('данные.xlsx', sheet_name='Продажи', usecols='A:C', dtype={'Продажи': float}) - Проверка данных:
df.info(),df.head()
Такой подход позволяет работать только с нужной информацией, экономит память и упрощает подготовку данных для построения графика.
Очистка и преобразование данных перед построением графика

Перед визуализацией важно привести данные к однородному формату. Пропуски обрабатывают через dropna() для удаления строк с отсутствующими значениями или fillna() с фиксированным значением или средним по колонке. Для числовых столбцов применяют преобразование типов astype(float) или astype(int), чтобы исключить ошибки при построении графиков.
Даты из файлов переводят в тип datetime через pd.to_datetime(), что позволяет корректно масштабировать ось X и использовать агрегирование по дням, месяцам или годам. Категориальные данные лучше привести к типу category для ускорения группировки и построения столбчатых графиков.
Дополнительно выполняют следующие преобразования:
- Переименование столбцов для ясности: df.rename(columns={‘Старое_имя’:’Новое_имя’}).
- Фильтрация выбросов: df[df[‘Продажи’] <= 1000] для исключения аномальных значений.
- Агрегация данных: df.groupby(‘Категория’)[‘Продажи’].sum().reset_index() для упрощения визуализации.
- Создание новых столбцов для расчета показателей, например, скользящей средней: df[‘SMA_7’] = df[‘Продажи’].rolling(7).mean().
Такая подготовка обеспечивает корректное отображение данных, ускоряет построение графика и повышает информативность визуализации.
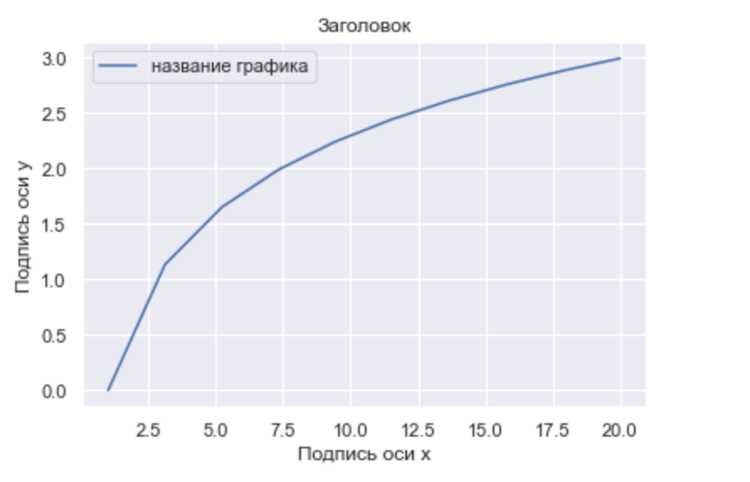
Построение линейного графика с использованием matplotlib
Для построения линейного графика применяют matplotlib.pyplot. Основная функция – plt.plot(x, y), где x – значения по оси X, y – по оси Y. Если данные из файла загружены через pandas, можно передавать столбцы напрямую: plt.plot(df['Дата'], df['Продажи']).
Рекомендации для корректного графика:
- Добавлять подписи осей:
plt.xlabel('Дата')иplt.ylabel('Продажи'). - Применять форматирование дат с помощью
plt.gcf().autofmt_xdate()для удобного отображения на оси X. - Использовать заголовок графика:
plt.title('Продажи по дням')для пояснения данных. - Настраивать цвет и стиль линии через параметры color, linestyle, marker:
plt.plot(x, y, color='blue', linestyle='-', marker='o'). - Добавлять сетку для визуального анализа:
plt.grid(True).
Для сохранения графика используют plt.savefig('график.png', dpi=300), что позволяет сохранить изображение высокого качества для веба и печати. После построения обязательно вызывают plt.show() для отображения графика в интерактивном окне.
Сохранение построенного графика в файл изображения
После построения графика его можно сохранить с помощью matplotlib.pyplot.savefig(). Важные параметры позволяют контролировать качество и формат изображения.
Рекомендации по сохранению:
- Имя файла и путь: указывать полный путь или относительный путь к директории, например:
plt.savefig('output/график.png'). - Формат: задается расширением файла – PNG, JPEG, SVG, PDF. Для векторной графики используют SVG или PDF, для растровой – PNG с высоким разрешением.
- DPI: параметр
dpiконтролирует разрешение. Для веба достаточно 150, для печати – 300 и выше:plt.savefig('график.png', dpi=300). - Прозрачный фон: при необходимости прозрачного фона используют
transparent=True. - Обрезка лишнего пространства:
bbox_inches='tight'позволяет удалить пустые поля вокруг графика.
Пример полной команды сохранения:
plt.savefig('график_продаж.png', dpi=300, bbox_inches='tight', transparent=False)- После сохранения вызывают
plt.close()для освобождения памяти при построении нескольких графиков в цикле.
Соблюдение этих рекомендаций обеспечивает четкость изображения, корректное отображение подписей и экономит ресурсы при работе с большими наборами данных.
Вопрос-ответ:
Какие форматы файлов лучше использовать для построения графиков в Python?
Для построения графиков чаще всего используют CSV, XLSX и JSON. CSV подходит для простых таблиц с разделителями, XLSX — для нескольких листов и сложных таблиц, JSON удобен для структурированных данных с вложенными объектами. Выбор зависит от структуры данных и удобства их предварительной обработки.
Как правильно читать CSV-файл с помощью pandas?
Для чтения CSV используют pandas.read_csv(). Нужно указать разделитель через sep, кодировку через encoding, и при необходимости заголовки через header. Даты лучше сразу преобразовать с помощью parse_dates, а числовые колонки указать через dtype. После загрузки рекомендуется проверить структуру таблицы через df.info() и df.head().
Как выбрать нужный лист в Excel-файле при загрузке данных?
При работе с Excel используют pandas.read_excel() и параметр sheet_name. Можно передать имя листа или его индекс. Чтобы увидеть все листы, используют pd.ExcelFile('файл.xlsx').sheet_names. Дополнительно полезно выбирать только нужные столбцы через usecols и пропускать ненужные строки с skiprows.
Какие шаги нужно выполнить для подготовки данных перед построением графика?
Необходимо очистить данные от пропусков через dropna() или fillna(), преобразовать типы числовых колонок через astype, а даты привести к типу datetime. Категории лучше преобразовать в тип category для группировки. Часто применяют фильтрацию выбросов, переименование столбцов и агрегацию данных через groupby() или вычисление скользящей средней через rolling().mean().
Как сохранить построенный график в файл с нужным качеством?
Используют plt.savefig(), указывая имя файла и формат (PNG, JPEG, SVG, PDF). Для высокого качества задают dpi — 150 для веба и 300 для печати. Параметр bbox_inches='tight' убирает лишние поля, а transparent=True делает фон прозрачным. После сохранения рекомендуется вызвать plt.close() при работе с несколькими графиками.
Как правильно обрабатывать пропуски и некорректные значения в данных перед построением графика в Python?
Перед построением графика важно убедиться, что данные не содержат пустых или некорректных значений. Пропуски можно удалить с помощью dropna() или заменить подходящими значениями через fillna(), например, средним, медианой или нулем. Для числовых колонок нужно проверить тип данных и при необходимости преобразовать через astype(float) или astype(int). Даты следует привести к типу datetime, чтобы их корректно отображать на оси X. Если есть выбросы, их можно отфильтровать с помощью условий, например: df[df['Продажи'] <= 1000]. Такие действия обеспечивают правильное построение графика и точность визуализации.