Содержание статьи

При работе с данными в Python часто требуется сформировать новый список из уже имеющегося набора элементов. Такой приём позволяет изменить структуру данных, отобрать нужные значения, подготовить массивы для вычислений или преобразовать формат хранения информации. Правильный выбор способа влияет на скорость обработки и удобство дальнейшей работы.
Python предлагает несколько инструментов, среди которых срезы, конструктор list(), выражения list comprehension, функции filter() и map(). Каждый из них подходит под свою задачу: копирование, фильтрация, преобразование или сбор элементов по определённому критерию.
Перед выбором метода стоит учитывать глубину вложенности, тип данных, а также то, требуется ли полностью изолировать новый список от исходного. Например, поверхностная копия подходит для плоских структур, тогда как при работе со вложенными объектами приходится использовать дополнительные инструменты для создания независимых копий.
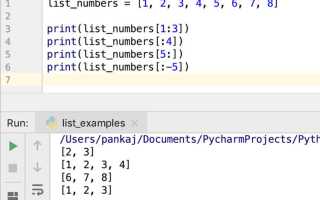
Копирование списка через срез для независимой работы с данными
Срез вида a[:] создаёт новый список, в котором сохраняются те же элементы, что и в исходном. Такой приём удобен, когда нужно изменить порядок, добавить или удалить элементы, не затрагивая исходную структуру. Операция выполняется быстро и не требует дополнительных модулей.
Срез копирует только внешний уровень списка. Если внутри находятся списки или другие изменяемые объекты, то изменения внутри вложенных структур отразятся в обеих копиях. Чтобы избежать этого, срез применяют только к плоским данным или используют дополнительные средства для глубокой копии.
При создании вспомогательных списков через a[:] стоит учитывать объём исходного массива. Для больших коллекций операция создаёт такой же по размеру массив в памяти, поэтому перед применением полезно уточнить, действительно ли требуется полная копия.
Создание нового списка при помощи list() для преобразования и копирования
Конструктор list() удобно использовать, когда требуется получить список из любого итерируемого объекта: строки, множества, генератора, результата функции. Такой подход позволяет быстро преобразовать структуру данных к формату последовательности и продолжить обработку в виде обычного списка.
При передаче существующего списка в list() создаётся новая копия внешнего уровня. Это подходит для случаев, когда нужно сохранить исходный порядок, но при этом получить независимый объект. В отличие от среза, list() работает с любым типом источника, поэтому часто применяется для преобразования данных, поступающих в виде итераторов.
Используя list() с генераторами, можно зафиксировать вычислённые значения в памяти. Это полезно, когда источник данных выдаёт элементы по одному и позже не сможет быть прочитан повторно. Такой приём помогает сохранить результаты перед дальнейшими преобразованиями или фильтрацией.
Формирование списка с условиями через list comprehension
List comprehension позволяет создавать новый список на основе существующего с применением точного условия отбора. Такой подход удобен, когда нужно оставить только элементы, удовлетворяющие проверке, например цифры выше заданного порога или строки с определённым шаблоном.
Выражение вида [x for x in data if x > 0] читается короче аналогичного цикла и не требует промежуточных переменных. Условие может включать несколько проверок, в том числе вызовы функций и методы строк. Это помогает собрать список, сразу приведённый к нужному формату.
Комбинация проверки и преобразования внутри одного выражения ускоряет обработку: [func(x) for x in data if check(x)]. Такой приём уменьшает количество шагов в коде и снижает риск ошибок при ручном построении вспомогательных структур.
Генерация списка на основе преобразования элементов существующего
Когда требуется изменить формат данных или получить значения в рассчитанном виде, удобнее всего применять преобразование каждого элемента исходного списка. Простейший вариант – использовать выражение вида [transform(x) for x in source], где функция или выражение в transform задаёт нужное преобразование.
Этот подход помогает быстро подготовить данные: округлить числа, извлечь фрагменты строк, собрать результаты вычислений. Например, конструкция [x.lower() for x in words] формирует список в едином регистре, а [len(item) for item in items] даёт массив длины элементов без промежуточных циклов.
При выполнении нескольких преобразований подряд можно объединить их в одну цепочку внутри выражения. Это снижает количество проходов по данным и делает структуру более предсказуемой. Важно следить, чтобы итоговое выражение оставалось читаемым; при сложных вычислениях преобразование лучше вынести в отдельную функцию.
Отбор уникальных значений для построения нового списка
Чтобы сформировать список без повторов и при этом сохранить порядок появления элементов, применяют проход по исходной последовательности с промежуточным множеством для контроля встреченных значений. Такой подход позволяет исключить дубликаты без преобразования в set, которое теряет порядок.
Базовая схема: создать пустые структуры seen = set() и result = [], затем добавлять элемент в result только при отсутствии его в seen. Этот вариант подходит для чисел, строк и любых объектов, поддерживающих хеширование.
Если требуется сравнение по конкретному признаку, например длине строки или части значения, используют дополнительную функцию, возвращающую ключ сравнения. Это помогает отобрать уникальные элементы по выбранному критерию, не нарушая исходную логику обработки данных.
| Задача | Подход |
|---|---|
| Убрать дубликаты с сохранением порядка | Контроль через множество и сформированный список |
| Отбор по признаку | Использование ключевой функции для вычисления уникального критерия |
| Работа с неизменяемыми объектами | Обычное множество set |
| Работа с изменяемыми объектами | Создание уникального ключа вручную |
Сбор элементов по индексу или маске из исходного списка

Для выборки конкретных элементов используют индексы или булевы маски. Простое извлечение по списку индексов реализуется через [source[i] for i in indices], где indices – набор числовых позиций. Такой подход удобен, когда известны точные позиции нужных элементов.
При работе с логическим критерием создаётся маска той же длины, что и исходный список, содержащая True для элементов, которые должны войти в новый список. Пример: [x for x, flag in zip(source, mask) if flag]. Это позволяет формировать списки на основе сложных условий без изменения исходной последовательности.
Комбинация индексов и масок полезна при частичном обновлении или фильтрации данных. Например, можно сначала выбрать элементы по позиции, а затем применить маску для отбора по значению. Такой подход снижает количество циклов и делает код более читаемым.
Создание вложенных списков при помощи comprehension с несколькими циклами

Вложенные списки позволяют представлять данные в виде матриц, таблиц или комбинаций элементов. Для их генерации в Python удобно использовать list comprehension с несколькими циклами внутри одного выражения.
Пример создания матрицы 3×3 с вычислением произведений индексов:
[[i * j for j in range(3)] for i in range(3)]
Пошаговые рекомендации:
- Первый цикл формирует внешний список, каждый элемент которого будет внутренним списком.
- Внутренний цикл создаёт элементы для каждого подсписка.
- Можно добавлять условие в любой цикл для фильтрации элементов по критерию.
- Использование нескольких циклов позволяет объединять разные наборы данных, например, пары элементов из двух списков: [[x, y] for x in list1 for y in list2].
- При работе с большими вложенными структурами рекомендуется проверять потребление памяти и при необходимости использовать генераторы.
Построение списка на основе фильтрации функциями filter() и lambda

Функция filter() применяет переданную функцию к каждому элементу последовательности и возвращает только те элементы, для которых функция вернула True. Использование вместе с lambda позволяет задавать короткие условия без объявления отдельной функции.
Пример фильтрации чисел больше 10:
filtered_list = list(filter(lambda x: x > 10, numbers))
Рекомендации по применению:
- Использовать lambda для простых проверок, например сравнения, проверки принадлежности множеству или длины строки.
- Для сложных условий лучше объявлять отдельную функцию, чтобы повысить читаемость и облегчить отладку.
- Применение list() к результату filter() позволяет получить полноценный список для дальнейшей обработки.
- Фильтрация может быть комбинирована с map(), если требуется одновременно преобразовать элементы и отобрать нужные.
- Подходит для больших наборов данных, так как filter() лениво обрабатывает элементы, создавая экономию памяти до вызова list().
Вопрос-ответ:
Чем отличается копирование списка через срез от использования list() в Python?
Срез a[:] создаёт новый список с теми же элементами, что и исходный, и подходит для плоских структур. Конструктор list() может принимать любой итерируемый объект и создаёт отдельный список. Разница проявляется в гибкости: list() позволяет сразу преобразовать строки, множества, генераторы или результаты функций в список, а срез работает только с существующими списками.
Как получить новый список с элементами, соответствующими определённому условию?
Для фильтрации используют list comprehension с условием. Например, [x for x in numbers if x > 5] создаст список чисел больше 5. Можно добавлять несколько условий или использовать функции для проверки, например [x for x in data if is_valid(x)]. Такой способ позволяет сразу формировать новый список с нужными элементами без промежуточных переменных.
Можно ли создать список только из уникальных значений исходного списка и сохранить порядок?
Да. Для этого создают пустое множество seen и список result. Проходя по исходному списку, добавляют элемент в result только если он отсутствует в seen. Такой метод работает с хешируемыми объектами и позволяет сохранить порядок появления уникальных элементов.
Как собрать элементы по индексу или маске, если известны позиции или критерии?
Если известны индексы, используют конструкцию [source[i] for i in indices]. Если есть булева маска, создают новый список через [x for x, flag in zip(source, mask) if flag]. Такой подход подходит для частичной выборки элементов и позволяет применять фильтры без изменения исходного списка.
Какие преимущества использования filter() с lambda при формировании нового списка?
Функция filter() позволяет отобрать элементы, удовлетворяющие определённому условию, без явного цикла. В сочетании с lambda можно быстро задать проверку, например list(filter(lambda x: x > 0, numbers)). Этот метод экономит память при работе с большими последовательностями, так как filter() создаёт итератор и элементы вычисляются по мере необходимости.