Содержание статьи

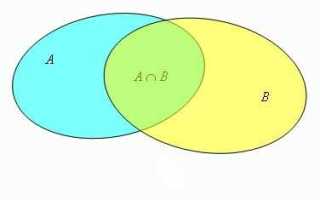
При работе с данными нередко требуется найти общие элементы в нескольких наборах. Python предоставляет прямые инструменты для такой задачи, позволяя использовать как встроенные методы, так и операторные формы. Это упрощает обработку массивов чисел, строковых значений и структур, полученных из файлов или API.
Пересечение удобно применять при анализе логов, отборе совпадающих идентификаторов, проверке пересечений результатов вычислений. Встроенный метод intersection() работает с любым количеством входных множеств, что снижает объём дополнительного кода. Оператор & подходит для кратких выражений, когда важна читаемость.
При подготовке набора данных стоит учитывать тип элементов. Python не принимает изменяемые объекты внутри множеств, поэтому списки и словари требуется преобразовывать. Это особенно полезно при работе с вложенными структурами, когда значения необходимо сначала перевести к хешируемому виду, например, к кортежам.
Применение пересечения также помогает ускорить фильтрацию данных. Вместо многократных проверок по условию можно заранее сформировать множество кандидатов и сравнить его с другими наборами. Такой подход уменьшает количество операций и делает код короче.
Пересечение трёх и более множеств через метод intersection()
Метод intersection() принимает неограниченное количество аргументов, что позволяет обрабатывать сразу несколько наборов данных. Например, set_a.intersection(set_b, set_c, set_d) возвращает элементы, присутствующие во всех переданных множествах. Такая форма удобна, когда источники данных поступают из разных модулей или файлов.
При работе с большим количеством множеств стоит заранее проверять их размеры. Оптимальный порядок – передавать первым набор с наименьшим числом элементов. Это сокращает число сравнений. Для автоматизации можно использовать sorted(list_of_sets, key=len) и последовательно передать их в метод.
Если множества создаются из внешних структур, полезно заранее исключить пустые наборы. Вызов intersection() с пустым множеством сразу даст пустой результат, что скажется на последующей логике. Проверка на уровне подготовки данных предотвращает лишние операции.
Метод подходит для случаев, когда данные нужно сверить по нескольким критериям. Например, фильтрация идентификаторов, одновременно встречающихся в журналах ошибок, отчётах мониторинга и экспортируемых таблицах. В таких ситуациях intersection() позволяет получить итог без дополнительных циклов.
Использование оператора & для объединённого пересечения
Оператор & позволяет получить пересечение нескольких множеств в виде цепочки выражений. Такая запись удобна при работе с краткими вычислениями и последующей передачей результата в другие функции.
Пример базового применения:
- result = set_a & set_b & set_c – пересечение трёх наборов;
- ids & allowed & active – фильтрация по нескольким условиям;
- (set_a & set_b) & set_d – пошаговое объединённое пересечение.
Оператор полезен, когда наборы создаются прямо в выражении:
- {1, 2, 3} & {2, 3, 4} & {3, 4, 5} – сразу даёт итоговое множество;
- set(users) & set(admins) & set(verified) – пересечение разных источников.
Для динамического количества множеств удобно использовать развёртку:
- Собрать все наборы в список.
- Вызвать functools.reduce с оператором &.
- Передать итог в обработку.
При работе с оператором стоит учитывать, что порядок влияет на скорость работы: первым рекомендуется указывать набор с минимальным числом элементов, чтобы сократить количество последующих проверок.
Пересечение множеств внутри циклов при динамическом количестве входных данных
Когда число входных наборов заранее неизвестно, пересечение удобно выполнять по мере поступления данных. Это снижает расход памяти и помогает контролировать объём промежуточных структур.
Базовый подход:
- Инициализировать результат первым полученным набором.
- В цикле принимать следующий набор и сразу пересекать его с текущим результатом.
- Прерывать цикл, если результат стал пустым.
Пример эффективной последовательной обработки:
result = None
for data in stream: # stream генерирует наборы
current = set(data)
if result is None:
result = current
continue
result &= current
if not result:
break
Рекомендации для больших объёмов:
- Сортировать входные наборы по размеру перед обработкой, если они доступны заранее: первая операция задаёт верхнюю границу результата.
- Избегать создания дубликатов наборов. Если источник отдаёт списки, преобразовывать их в множества один раз.
- При работе с файлами читать данные построчно и формировать множества через генераторы, не материализуя лишние структуры.
- Выбирать оператор
&=, так как он работает без создания нового объекта.
Такой алгоритм подходит для сценариев, где объёмы меняются, а итог нужно получить без задержек и лишнего копирования.
Получение пересечения списков через преобразование в множества

При обработке списков удобнее работать с множествами, так как операция пересечения выполняется быстрее за счёт хеш-структуры. Преобразование оправдано при объёмах от сотен элементов и выше.
Последовательность действий:
- Преобразовать каждый список в множество для удаления дубликатов и ускорения поиска.
- Пересекать наборы по мере готовности данных через оператор
&или методintersection(). - При необходимости вернуть итог в формате списка.
Пример:
list_a = [1, 2, 2, 3, 5]
list_b = [2, 3, 4]
list_c = [3, 5, 7]
a = set(list_a)
b = set(list_b)
c = set(list_c)
result = a & b & c
result_list = list(result)
Рекомендации:
- Трансформировать только те списки, которые используют операции поиска или сравнения; для прямой итерации множества не дают преимуществ.
- Если входные данные поступают в виде больших списков, выполнять преобразование через генераторы, избегая промежуточных копий.
- Для стабильного порядка сортировать результат вручную, так как множества его не сохраняют.
- При пересечении большого числа списков сортировать их по длине и начинать с минимального множества.
Пересечение наборов данных, полученных из словарей и их ключей
Ключи словарей удобно использовать как источник множеств: они уже уникальны и легко преобразуются в структуры для пересечения. Это позволяет быстро находить совпадающие признаки между несколькими наборами данных.
Основные варианты:
- Пересечение только ключей.
- Пересечение значений после выборки нужных полей.
- Пересечение пар «ключ–значение» через преобразование к множствам кортежей.
Пример пересечения ключей:
a = {"id": 1, "name": "A", "tags": [1, 2]}
b = {"id": 3, "name": "B", "status": True}
c = {"id": 7, "name": "C", "tags": [3, 4]}
result = set(a.keys()) & set(b.keys()) & set(c.keys())
Пересечение значений по выбранному ключу:
a = {"tags": [1, 2, 3]}
b = {"tags": [2, 4]}
c = {"tags": [2, 3, 5]}
result = set(a["tags"]) & set(b["tags"]) & set(c["tags"])
Пересечение пар:
a = {"id": 1, "role": "user"}
b = {"id": 1, "role": "admin"}
c = {"id": 1, "role": "user"}
result = set(a.items()) & set(b.items()) & set(c.items())
Рекомендации:
- При большом количестве словарей начинать пересечение с того, где меньше ключей.
- Если словари содержат вложенные структуры, заранее нормализовать нужные фрагменты в отдельные множества.
- Проверять наличие ключа перед обработкой, чтобы избежать исключений.
- Для списков внутри словарей применять преобразование в множество один раз, а не в каждой итерации.
Работа с пересечением множеств, содержащих неизменяемые объекты
Множества в Python могут хранить только неизменяемые объекты, такие как числа, строки, кортежи и frozenset. Для пересечения таких множеств можно использовать стандартные операторы & и методы intersection().
Пример пересечения множеств с кортежами:
set_a = {(1, 2), (3, 4), (5, 6)}
set_b = {(3, 4), (7, 8)}
set_c = {(3, 4), (9, 10)}
result = set_a & set_b & set_c
Пример с frozenset:
fs1 = frozenset([1, 2, 3])
fs2 = frozenset([2, 3, 4])
fs3 = frozenset([3, 4, 5])
result = fs1.intersection(fs2, fs3)
Рекомендации:
- Для кортежей проверять, что все вложенные элементы также неизменяемы, иначе возникнет TypeError.
- Использовать
frozensetдля вложенных множеств, чтобы их можно было включить в пересечение. - При большом числе множеств начинать пересечение с самого маленького, чтобы уменьшить объём промежуточных данных.
- Метод
intersection()позволяет сразу передавать несколько наборов, что сокращает количество операций.
Такая практика обеспечивает корректное и быстрое получение пересечения для неизменяемых объектов любых уровней вложенности.
Пересечение множеств в контексте фильтрации данных

Пересечение множеств позволяет эффективно фильтровать элементы, которые одновременно удовлетворяют нескольким условиям. Этот подход применим для выборки записей из разных источников по общим признакам.
Пример фильтрации пользователей по интересам и геолокации:
users_by_interest = {"Alice", "Bob", "Charlie", "Diana"}
users_by_city = {"Bob", "Charlie", "Eve"}
users_by_subscription = {"Charlie", "Bob", "Frank"}
filtered_users = users_by_interest & users_by_city & users_by_subscription
Рекомендации по оптимизации:
- Сначала фильтровать по множеству с наименьшей размерностью, чтобы сократить промежуточные результаты.
- Использовать
intersection(), если количество фильтров заранее неизвестно и поступает динамически. - Для больших наборов данных использовать frozenset для вложенных структур.
Пример использования таблицы для отображения фильтрации:
| Пользователь | Интерес | Город | Подписка | Прошел фильтр |
|---|---|---|---|---|
| Alice | Да | Нет | Да | Нет |
| Bob | Да | Да | Да | Да |
| Charlie | Да | Да | Да | Да |
| Diana | Да | Нет | Нет | Нет |
Табличное представление позволяет наглядно отслеживать соответствие элементов нескольким критериям и быстро выявлять пересечения.
Вопрос-ответ:
Как пересечь несколько множеств в Python с помощью встроенных методов?
Для пересечения множеств можно использовать метод intersection() или оператор &. Например, result = set1.intersection(set2, set3) вернёт элементы, присутствующие во всех множествах. Оператор & позволяет записать то же самое в виде result = set1 & set2 & set3.
Можно ли пересекать динамическое количество множеств, когда их число заранее неизвестно?
Да, можно передавать несколько множеств через функцию intersection() с распаковкой списка: sets = [set1, set2, set3]; result = set1.intersection(*sets[1:]). Также можно использовать цикл, начиная с первого множества, и последовательно пересекать с остальными через оператор &=.
Как правильно пересекать множества, содержащие кортежи и другие неизменяемые объекты?
Множества в Python допускают только неизменяемые объекты. Кортежи, числа, строки и frozenset можно использовать без ограничений. Для пересечения множеств с кортежами применяют стандартные операторы: result = set_a & set_b. Если кортежи содержат изменяемые элементы, например списки, их нужно заменить на кортежи или frozenset.
Как использовать пересечение множеств для фильтрации данных из словарей?
Можно использовать ключи или значения словарей для создания множеств, а затем пересекать их. Например, чтобы найти общие ключи у нескольких словарей: result = set(dict1.keys()) & set(dict2.keys()) & set(dict3.keys()). Для значений или пар «ключ-значение» применяется аналогичный подход, с преобразованием списков в множества.
Есть ли рекомендации по оптимизации пересечения больших множеств?
При работе с большими множествами лучше начинать пересечение с самого маленького набора, чтобы уменьшить объём промежуточных данных. Если множества поступают динамически, полезно использовать метод intersection() с передачей всех остальных наборов через распаковку. Для вложенных структур использовать frozenset, чтобы их можно было включать в пересечение.
Как найти пересечение нескольких множеств в Python, если их количество неизвестно заранее?
Если множества поступают динамически, удобно использовать метод intersection() с распаковкой списка или последовательное пересечение через цикл. Например, sets = [set1, set2, set3]; result = sets[0].intersection(*sets[1:]). Альтернативно можно итерировать по списку множеств и последовательно применять оператор &=, начиная с первого набора. Такой подход позволяет работать с любым количеством входных данных без создания лишних копий.
Можно ли пересекать множества, содержащие кортежи и frozenset, и как это правильно делать?
Да, множества допускают неизменяемые объекты, включая кортежи и frozenset. Для пересечения стандартно используют оператор & или метод intersection(). Пример: result = set1 & set2, где set1 и set2 содержат кортежи. Если кортежи содержат изменяемые элементы, их нужно заменить на неизменяемые типы, чтобы избежать ошибки. Для вложенных множеств применяют frozenset, чтобы они могли участвовать в пересечении.