Содержание статьи

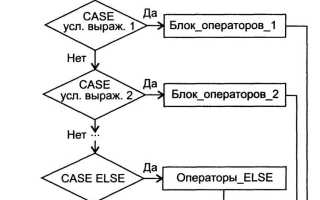
В языке Си массивы представляют собой последовательность однотипных элементов, доступ к которым осуществляется по индексу. Комбинирование массивов с конструкцией switch case позволяет создавать точные ветвления для обработки каждого элемента, особенно когда значения элементов ограничены фиксированным набором вариантов.
Для работы с массивом через switch case важно определить тип элементов и диапазон возможных значений. Например, при числовых массивах можно использовать case для конкретных чисел, диапазонов или групп значений, что сокращает количество условных операторов if-else и делает код более структурированным.
При работе со строковыми массивами или перечислениями необходимо помнить, что switch case в Си напрямую не поддерживает строки, поэтому применяются вспомогательные методы, такие как сопоставление с константами или использование числовых идентификаторов для строк. Это позволяет сохранять скорость выполнения и упрощает масштабирование кода.
Использование циклов совместно с switch case обеспечивает последовательную обработку элементов массива. Такой подход полезен при реализации функций сортировки, подсчета статистики, фильтрации данных или применения разных алгоритмов к разным элементам массива в зависимости от их значения.
Важно учитывать возможные ошибки: пропущенные break могут привести к непредсказуемому выполнению нескольких блоков, а некорректная индексация массива – к выходу за границы памяти. Планирование структуры case для каждого элемента минимизирует такие ошибки и делает код более читаемым и поддерживаемым.
Инициализация массива для использования с switch case

Перед применением switch case к массиву важно правильно определить размер и тип элементов. Для числовых массивов используют запись int arr[5] = {1, 2, 3, 4, 5};, где каждый элемент имеет фиксированное значение и индекс для прямого обращения в case. Размер массива должен соответствовать количеству обрабатываемых элементов, чтобы избежать выхода за границы памяти.
Для строковых значений применяют массив указателей на строки: char *arr[3] = {«apple», «banana», «cherry»};. Поскольку switch case в Си не поддерживает строки напрямую, каждому элементу присваивают числовой идентификатор через перечисление enum или отдельные константы. Это позволяет использовать case с числами, сохраняя связь с исходными строками.
Инициализация может быть как статической, с фиксированными значениями, так и динамической через циклы. При динамическом заполнении важно проверять корректность индексов и допустимые значения, чтобы каждый элемент можно было однозначно обработать в switch case.
Рекомендуется использовать инициализацию через константы или перечисления для элементов, которые будут обрабатываться case. Это упрощает чтение кода и позволяет избежать ошибок при добавлении новых элементов или изменении значений в массиве.
Применение switch case для обработки элементов массива

Для обработки элементов массива через switch case используют индекс или значение элемента в качестве выражения. Например, для числового массива int arr[5] = {1, 2, 3, 4, 5}; можно написать цикл for (int i = 0; i < 5; i++) и внутри него применить switch(arr[i]), задавая отдельные case для каждого значения.
Каждый case должен содержать конкретные действия для соответствующего значения. Для нескольких элементов с одинаковой обработкой можно объединять case без break до нужного блока. Это снижает дублирование кода и упрощает поддержку.
При работе с массивами, заполненными перечислениями enum, switch case позволяет напрямую использовать константы перечисления, что повышает читаемость кода и снижает риск ошибок при изменении значений.
Важно включать default для обработки неожиданных значений или пустых элементов массива. Это предотвращает некорректное выполнение программы и позволяет добавить логирование или обработку ошибок для элементов, которые не соответствуют ожидаемым вариантам.
При больших массивах или диапазонах значений рекомендуется группировать похожие значения в case и использовать вспомогательные функции для повторяющихся действий. Это делает структуру switch более компактной и понятной.
Обработка числовых значений в массиве через switch case

Для числовых массивов switch case позволяет точно назначить действия для конкретных значений. Например, массив int arr[6] = {0, 1, 2, 3, 4, 5}; можно обрабатывать циклом for с конструкцией switch(arr[i]), задавая отдельные case для каждого числа.
Для групп чисел с одинаковой обработкой можно объединять case через последовательность без break. Например, case 1: case 2: case 3: позволяет выполнить один блок кода для значений 1, 2 и 3, экономя строки кода и снижая вероятность ошибок.
Если массив содержит диапазоны значений, которых слишком много для перечисления в каждом case, применяют дополнительную проверку внутри case с логическим условием, например case 0: case 1: case 2: if(arr[i] <= 2) { ... }, чтобы расширить возможности ветвления.
Использование default блоков важно для обработки неожиданных или неинициализированных значений, например default: printf(«Неизвестное значение %d\n», arr[i]);. Это обеспечивает контроль ошибок и предсказуемое поведение программы при работе с массивами чисел.
Использование switch case для строковых элементов массива
В языке Си switch case напрямую не поддерживает строки, поэтому для массивов строк применяют косвенные методы:
- Создание массива указателей на строки: char *arr[3] = {«apple», «banana», «cherry»};
- Определение числовых идентификаторов через enum или константы для каждой строки:
enum Fruits {APPLE = 1, BANANA, CHERRY};
- Сопоставление каждого элемента массива с его идентификатором перед передачей в switch:
int id = strcmp(arr[i], «apple») == 0 ? APPLE : …;
После присвоения числового идентификатора выполняется обычный switch case:
- case APPLE: – действия для «apple»
- case BANANA: – действия для «banana»
- case CHERRY: – действия для «cherry»
- default: – обработка неизвестных строк
Такой подход позволяет:
- Использовать преимущества switch case для быстрого ветвления
- Упрощать масштабирование при добавлении новых строк
- Сохранять читаемость кода и минимизировать дублирование условий
Комбинация switch case и циклов при обходе массива
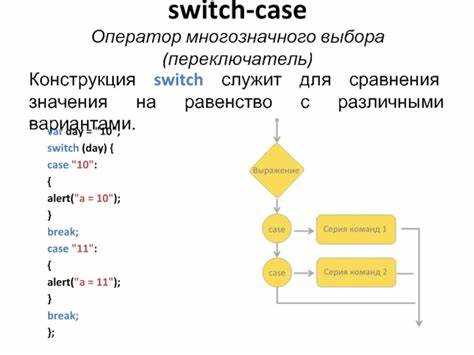
Для последовательной обработки элементов массива используют циклы совместно с switch case. Например, числовой массив int arr[5] = {0, 1, 2, 3, 4}; можно обрабатывать циклом for (int i = 0; i < 5; i++), помещая внутри switch(arr[i]) блоки case для каждого значения.
При динамически изменяемых массивах важно контролировать индекс и диапазон значений:
- Использовать for или while для обхода всех элементов.
- Применять switch case к текущему элементу массива, присваивая действия на основе его значения или идентификатора.
- Включать default для обработки неожиданных значений и предотвращения некорректного выполнения программы.
Для массивов с повторяющимися значениями или группами элементов с одинаковой обработкой можно объединять case без break. Это сокращает количество строк кода и упрощает его поддержку при изменении логики обработки.
При вложенных циклах, например для двумерных массивов, switch case позволяет управлять действиями для каждой строки или столбца отдельно, обеспечивая точное выполнение алгоритмов сортировки, фильтрации или подсчета статистики.
Обработка нескольких условий для одного элемента массива

Для одного элемента массива можно назначить несколько условий в switch case через объединение case или использование дополнительной логики внутри блока. Например, числовой массив int arr[6] = {0, 1, 2, 3, 4, 5}; можно обработать так, чтобы один блок выполнялся для значений 1, 2 и 3, а другой для 4 и 5.
Пример организации условий можно оформить в виде таблицы:
| Значение элемента | Действие в switch case |
|---|---|
| 0 | Пропустить обработку |
| 1, 2, 3 | Выполнить блок для малых чисел |
| 4, 5 | Выполнить блок для больших чисел |
| остальные | Вывести сообщение об ошибке через default |
Если условия более сложные, внутри case можно использовать дополнительные проверки if, чтобы уточнить обработку для определенных диапазонов или комбинаций значений.
Такая организация позволяет сокращать повторяющиеся блоки, поддерживать читаемость кода и легко расширять обработку при добавлении новых значений массива.
Ошибки при использовании switch case с массивами и их исправление
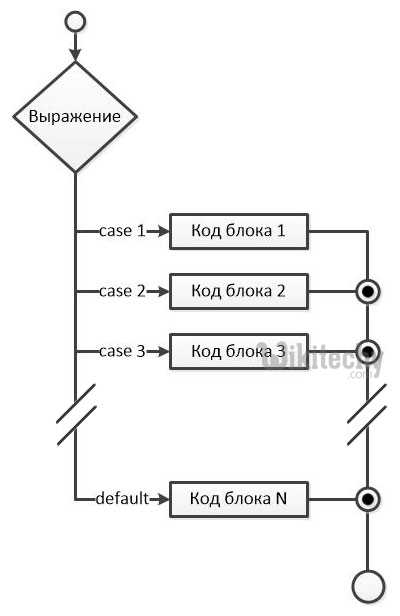
При использовании switch case с массивами часто встречаются следующие ошибки:
- Пропущенный break: выполнение нескольких блоков case подряд. Исправление – всегда завершать блок break или использовать явное объединение case.
- Выход за границы массива: обращение к несуществующему индексу. Решение – проверка индекса перед использованием: if(i >= 0 && i < SIZE).
- Несовпадение типов: попытка использовать строки напрямую в switch case. Исправление – присвоение числовых идентификаторов через enum или константы.
- Необработанные значения: отсутствие default для неожиданных элементов. Рекомендуется включать default с логированием или обработкой ошибок.
Дополнительно полезно проверять диапазоны значений при использовании группировки case для нескольких элементов и избегать вложенных switch без явной необходимости. Это предотвращает скрытые ошибки и упрощает отладку.
Регулярное тестирование с различными наборами данных массива позволяет выявить нестандартные сценарии, когда значения могут выйти за пределы ожидаемых, и своевременно корректировать блоки switch case.
Примеры практических задач с массивами и switch case

Использование switch case с массивами удобно для реализации конкретных алгоритмов обработки данных. Рассмотрим несколько практических задач:
-
Подсчет категорий чисел
- Массив: int arr[10]
- Задача: определить количество отрицательных, нулевых и положительных элементов
- Решение: присвоение идентификаторов каждому диапазону чисел и обработка через switch case
-
Классификация оценок студентов
- Массив: int grades[20] с оценками от 1 до 5
- Задача: вывести категорию оценки («неудовлетворительно», «удовлетворительно», «отлично»)
- Решение: использование switch(grades[i]) с группировкой case для одинаковых категорий
-
Обработка команд меню
- Массив: char commands[5] с кодами команд
- Задача: выполнять разные функции в зависимости от команды
- Решение: каждому коду присвоен числовой идентификатор, далее обработка через switch case
Такие примеры демонстрируют, как switch case упрощает ветвление логики при обработке массивов с разными типами данных, минимизируя дублирование кода и повышая точность выполнения алгоритмов.
Вопрос-ответ:
Можно ли использовать switch case для строк в массиве на языке Си?
Прямое использование строк в switch case в Си невозможно, так как конструкция поддерживает только целочисленные выражения. Для обработки строк применяют числовые идентификаторы, присвоенные через enum или константы, и затем используют эти идентификаторы в блоках case. Для сопоставления строки с идентификатором обычно используют функцию strcmp.
Как объединять несколько значений массива в один блок case?
Если несколько элементов массива требуют одинаковой обработки, их можно объединить в один блок case без использования break между ними. Например: case 1: case 2: case 3: выполнит один блок кода для всех трёх значений. Такой подход уменьшает дублирование кода и упрощает поддержку программы.
Какие ошибки чаще всего возникают при использовании switch case с массивами?
Основные ошибки включают пропущенные break, что приводит к выполнению нескольких блоков case, выход за границы массива при неправильной индексации, и использование строк без присвоения идентификаторов. Для исправления необходимо контролировать индексы, всегда завершать блоки case через break и применять числовые идентификаторы для строк.
Можно ли использовать циклы совместно с switch case для обработки всех элементов массива?
Да, обычно применяют цикл for или while для последовательного обхода массива, а внутри цикла используют switch case для каждого элемента. Это позволяет назначать конкретные действия для разных значений, объединять одинаковые условия в один блок и добавлять default для обработки неожиданных значений. Такой подход упрощает обработку больших массивов и обеспечивает контроль над логикой выполнения.